
Peer-to-peer (P2P) computing or networking is a distributed application architecture that partitions tasks or workloads between peers. Peers are equally privileged, equipotent participants in the application. They are said to form a peer-to-peer network of nodes.

A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map.

Social network analysis (SNA) is the process of investigating social structures through the use of networks and graph theory. It characterizes networked structures in terms of nodes and the ties, edges, or links that connect them. Examples of social structures commonly visualized through social network analysis include social media networks, memes spread, information circulation, friendship and acquaintance networks, business networks, knowledge networks, difficult working relationships, social networks, collaboration graphs, kinship, disease transmission, and sexual relationships. These networks are often visualized through sociograms in which nodes are represented as points and ties are represented as lines. These visualizations provide a means of qualitatively assessing networks by varying the visual representation of their nodes and edges to reflect attributes of interest.

In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple segments. The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is typically used to locate objects and boundaries in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.
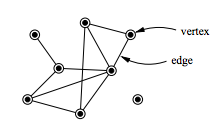
Network theory is the study of graphs as a representation of either symmetric relations or asymmetric relations between discrete objects. In computer science and network science, network theory is a part of graph theory: a network can be defined as a graph in which nodes and/or edges have attributes.
Misinformation is false, inaccurate, or misleading information that is communicated regardless of an intention to deceive. Examples of misinformation are false rumors, insults, and pranks. Disinformation is a subset of misinformation that is deliberately deceptive, e.g., malicious hoaxes, spearphishing, and computational propaganda. The principal effect of misinformation is to elicit fear and suspicion among a population. News parody or satire can become misinformation if it is believed to be credible and communicated as if it were true. The words "misinformation" and "disinformation" have often been associated with the concept of "fake news", which some scholars define as "fabricated information that mimics news media content in form but not in organizational process or intent".
In the study of complex networks, a network is said to have community structure if the nodes of the network can be easily grouped into sets of nodes such that each set of nodes is densely connected internally. In the particular case of non-overlapping community finding, this implies that the network divides naturally into groups of nodes with dense connections internally and sparser connections between groups. But overlapping communities are also allowed. The more general definition is based on the principle that pairs of nodes are more likely to be connected if they are both members of the same community(ies), and less likely to be connected if they do not share communities. A related but different problem is community search, where the goal is to find a community that a certain vertex belongs to.
In computing, reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change. With this paradigm, it's possible to express static or dynamic data streams with ease, and also communicate that an inferred dependency within the associated execution model exists, which facilitates the automatic propagation of the changed data flow.
Network motifs are recurrent and statistically significant subgraphs or patterns of a larger graph. All networks, including biological networks, social networks, technological networks and more, can be represented as graphs, which include a wide variety of subgraphs.

Social media measurement and social media analytics, social listening is a way of computing popularity of a brand or company by extracting information from social media channels, such as blogs, wikis, news sites, micro-blogs such as Twitter, social networking sites, video/photo sharing websites, forums, message boards and user-generated content from time to time. In other words, this is the way to caliber success of social media marketing strategies used by a company or a brand. It is also used by companies to gauge current trends in the industry. The process first gathers data from different websites and then performs analysis based on different metrics like time spent on the page, click through rate, content share, comments, text analytics to identify positive or negative emotions about the brand.
The clique percolation method is a popular approach for analyzing the overlapping community structure of networks. The term network community has no widely accepted unique definition and it is usually defined as a group of nodes that are more densely connected to each other than to other nodes in the network. There are numerous alternative methods for detecting communities in networks, for example, the Girvan–Newman algorithm, hierarchical clustering and modularity maximization.
A social network is a social structure made up of a set of social actors, sets of dyadic ties, and other social interactions between actors. The social network perspective provides a set of methods for analyzing the structure of whole social entities as well as a variety of theories explaining the patterns observed in these structures. The study of these structures uses social network analysis to identify local and global patterns, locate influential entities, and examine network dynamics.

NetMiner is an application software for exploratory analysis and visualization of large network data based on SNA(Social Network Analysis). It can be used for general research and teaching in social networks. This tool allows researchers to explore their network data visually and interactively, helps them to detect underlying patterns and structures of the network. It features data transformation, network analysis, statistics, visualization of network data, chart, and a programming language based on the Python script language. Also, it enables users to import unstructured text data(e.g. news, articles, tweets, etc.) and extract words and network from text data. In addition, NetMiner SNS Data Collector, an extension of NetMiner, can collect some social networking service(SNS) data with a few clicks.
NodeXL is a network analysis and visualization software package for Microsoft Excel 2007/2010/2013/2016. It is a popular package similar to other network visualization tools such as Pajek, UCINet, and Gephi. It is widely applied in ring, mapping of vertex and edge, and customizable visual attributes and tags. It enables researchers to undertake social network analysis work’s metrics such as centrality, degree, and clustering. It allows us to see the relational data and describe the overall relational network structure. When we applied it in Twitter data analysis, it can show the huge network of all users participating in public discussion and its internal structure through big data mining. It permits social Network analysis (SNA) emphasizes the relationships rather than isolated individuals or organizations, so this method allows us to investigate the ‘two-way dialogue between the organization and the public. SNA also provides researchers with a flexible measurement system and parameter selection to confirm the influential nodes in the network, such as in-degree and out-degree centrality. The free version contains network visualization and social network analysis features. The commercial version includes access to social media network data importers, advanced network metrics, and automation.
Social media mining is the process of obtaining big data from user-generated content on social media sites and mobile apps in order to extract patterns, form conclusions about users, and act upon the information, often for the purpose of advertising to users or conducting research. The term is an analogy to the resource extraction process of mining for rare minerals. Resource extraction mining requires mining companies to shift through vast quantities of raw ore to find the precious minerals; likewise, social media mining requires human data analysts and automated software programs to shift through massive amounts of raw social media data in order to discern patterns and trends relating to social media usage, online behaviours, sharing of content, connections between individuals, online buying behaviour, and more. These patterns and trends are of interest to companies, governments and not-for-profit organizations, as these organizations can use these patterns and trends to design their strategies or introduce new programs, new products, processes or services.
Social navigation is a form of social computing introduced by Dourish and Chalmers in 1994. They defined it as when "movement from one item to another is provoked as an artifact of the activity of another or a group of others". According to later research in 2002, "social navigation exploits the knowledge and experience of peer users of information resources" to guide users in the information space. With all of the digital information available both on the World Wide Web and from other sources, it is becoming increasingly difficult to navigate and search efficiently. Studying others' navigational trails and understanding their behavior can help improve one's own search strategy by helping them to make more informed decisions based on the actions of others. "The idea of social navigation is to aid users to navigate information spaces through making the collective, aggregated, or individual actions of others visible and useful as a basis for making decisions on where to go next and what to choose."
A social bot or troll bot is an agent that communicates more or less autonomously on social media, often with the task of influencing the course of discussion and/or the opinions of its readers. It is related to chatbots but mostly only uses rather simple interactions or no reactivity at all. The messages it distributes are mostly either very simple, or prefabricated, and it often operates in groups and various configurations of partial human control (hybrid). It usually targets advocating certain ideas, supporting campaigns, or aggregating other sources either by acting as a "follower" and/or gathering followers itself. In this very limited respect, social bots can be said to have passed the Turing test. If social media profiles are expected to be human, then social bots represent fake accounts. The automated creation and deployment of many social bots against a distributed system or community is one form of Sybil attack.
Network eavesdropping, also known as eavesdropping attack, sniffing attack, or snooping attack, is a method that retrieves user information through the internet. This attack happens on electronic devices like computers and smartphones. This network attack typically happens under the usage of unsecured networks, such as public wifi connections or shared electronic devices. Eavesdropping attacks through the network is considered one of the most urgent threats in industries that rely on collecting and storing data.
In network theory, link prediction is the problem of predicting the existence of a link between two entities in a network. Examples of link prediction include predicting friendship links among users in a social network, predicting co-authorship links in a citation network, and predicting interactions between genes and proteins in a biological network. Link prediction can also have a temporal aspect, where, given a snapshot of the set of links at time , the goal is to predict the links at time . Link prediction is widely applicable. In e-commerce, link prediction is often a subtask for recommending items to users. In the curation of citation databases, it can be used for record deduplication. In bioinformatics, it has been used to predict protein-protein interactions (PPI). It is also used to identify hidden groups of terrorists and criminals in security related applications.
In network theory, collective classification is the simultaneous prediction of the labels for multiple objects, where each label is predicted using information about the object's observed features, the observed features and labels of its neighbors, and the unobserved labels of its neighbors. Collective classification problems are defined in terms of networks of random variables, where the network structure determines the relationship between the random variables. Inference is performed on multiple random variables simultaneously, typically by propagating information between nodes in the network to perform approximate inference. Approaches that use collective classification can make use of relational information when performing inference. Examples of collective classification include predicting attributes of individuals in a social network, classifying webpages in the World Wide Web, and inferring the research area of a paper in a scientific publication dataset.