Definition
A real-valued function  on an interval (or, more generally, a convex set in vector space) is said to be concave if, for any
on an interval (or, more generally, a convex set in vector space) is said to be concave if, for any  and
and  in the interval and for any
in the interval and for any  , [1]
, [1]

A function is called strictly concave if

for any  and
and  .
.
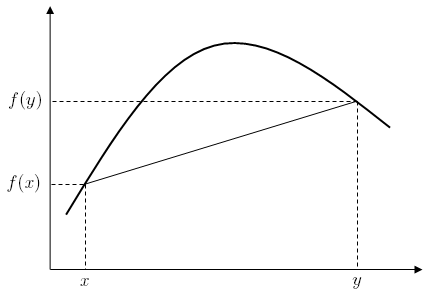
For a function  , this second definition merely states that for every
, this second definition merely states that for every  strictly between and , the point
strictly between and , the point  on the graph of is above the straight line joining the points
on the graph of is above the straight line joining the points  and
and  .
.
A function is quasiconcave if the upper contour sets of the function  are convex sets. [2]
are convex sets. [2]
This page is based on this
Wikipedia article Text is available under the
CC BY-SA 4.0 license; additional terms may apply.
Images, videos and audio are available under their respective licenses.


















