Information retrieval (IR) in computing and information science is the process of obtaining information system resources that are relevant to an information need from a collection of those resources. Searches can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.
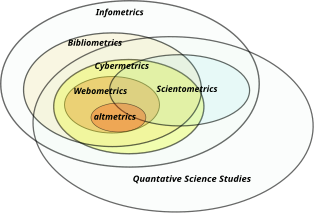
Information science is an academic field which is primarily concerned with analysis, collection, classification, manipulation, storage, retrieval, movement, dissemination, and protection of information. Practitioners within and outside the field study the application and the usage of knowledge in organizations in addition to the interaction between people, organizations, and any existing information systems with the aim of creating, replacing, improving, or understanding the information systems.
Music information retrieval (MIR) is the interdisciplinary science of retrieving information from music. Those involved in MIR may have a background in academic musicology, psychoacoustics, psychology, signal processing, informatics, machine learning, optical music recognition, computational intelligence or some combination of these.
Question answering (QA) is a computer science discipline within the fields of information retrieval and natural language processing (NLP) that is concerned with building systems that automatically answer questions that are posed by humans in a natural language.
The following outline is provided as an overview of and topical guide to human–computer interaction:

The Text REtrieval Conference (TREC) is an ongoing series of workshops focusing on a list of different information retrieval (IR) research areas, or tracks. It is co-sponsored by the National Institute of Standards and Technology (NIST) and the Intelligence Advanced Research Projects Activity, and began in 1992 as part of the TIPSTER Text program. Its purpose is to support and encourage research within the information retrieval community by providing the infrastructure necessary for large-scale evaluation of text retrieval methodologies and to increase the speed of lab-to-product transfer of technology.
Bibliographic coupling, like co-citation, is a similarity measure that uses citation analysis to establish a similarity relationship between documents. Bibliographic coupling occurs when two works reference a common third work in their bibliographies. It is an indication that a probability exists that the two works treat a related subject matter.
Relevance feedback is a feature of some information retrieval systems. The idea behind relevance feedback is to take the results that are initially returned from a given query, to gather user feedback, and to use information about whether or not those results are relevant to perform a new query. We can usefully distinguish between three types of feedback: explicit feedback, implicit feedback, and blind or "pseudo" feedback.
Query expansion (QE) is the process of reformulating a given query to improve retrieval performance in information retrieval operations, particularly in the context of query understanding. In the context of search engines, query expansion involves evaluating a user's input and expanding the search query to match additional documents. Query expansion involves techniques such as:
Knowledge organization (KO), organization of knowledge, organization of information, or information organization, is an intellectual discipline concerned with activities such as document description, indexing, and classification that serve to provide systems of representation and order for knowledge and information objects. According to The Organization of Information by Joudrey and Taylor, information organization:
examines the activities carried out and tools used by people who work in places that accumulate information resources for the use of humankind, both immediately and for posterity. It discusses the processes that are in place to make resources findable, whether someone is searching for a single known item or is browsing through hundreds of resources just hoping to discover something useful. Information organization supports a myriad of information-seeking scenarios.
The National Centre for Text Mining (NaCTeM) is a publicly funded text mining (TM) centre. It was established to provide support, advice, and information on TM technologies and to disseminate information from the larger TM community, while also providing tailored services and tools in response to the requirements of the United Kingdom academic community.

Data collection or data gathering is the process of gathering and measuring information on targeted variables in an established system, which then enables one to answer relevant questions and evaluate outcomes. Data collection is a research component in all study fields, including physical and social sciences, humanities, and business. While methods vary by discipline, the emphasis on ensuring accurate and honest collection remains the same. The goal for all data collection is to capture evidence that allows data analysis to lead to the formulation of credible answers to the questions that have been posed.
Human–computer information retrieval (HCIR) is the study and engineering of information retrieval techniques that bring human intelligence into the search process. It combines the fields of human-computer interaction (HCI) and information retrieval (IR) and creates systems that improve search by taking into account the human context, or through a multi-step search process that provides the opportunity for human feedback.
A concept search is an automated information retrieval method that is used to search electronically stored unstructured text for information that is conceptually similar to the information provided in a search query. In other words, the ideas expressed in the information retrieved in response to a concept search query are relevant to the ideas contained in the text of the query.
Ranking of query is one of the fundamental problems in information retrieval (IR), the scientific/engineering discipline behind search engines. Given a query q and a collection D of documents that match the query, the problem is to rank, that is, sort, the documents in D according to some criterion so that the "best" results appear early in the result list displayed to the user. Ranking in terms of information retrieval is an important concept in computer science and is used in many different applications such as search engine queries and recommender systems. A majority of search engines use ranking algorithms to provide users with accurate and relevant results.
The European Summer School in Information Retrieval (ESSIR) is a scientific event founded in 1990, which starts off a series of Summer Schools to provide high-quality teaching of information retrieval on advanced topics. ESSIR is typically a week-long event consisting of guest lectures and seminars from invited lecturers who are recognized experts in the field. The aim of ESSIR is to give to its participants a common ground in different aspects of Information Retrieval (IR). Maristella Agosti in 2008 stated that: "The term IR identifies the activities that a person – the user – has to conduct to choose, from a collection of documents, those that can be of interest to him to satisfy a specific and contingent information need."

Lucene Geographic and Temporal (LGTE) is an information retrieval tool developed at Technical University of Lisbon which can be used as a search engine or as evaluation system for information retrieval techniques for research purposes. The first implementation powered by LGTE was the search engine of DIGMAP, a project co-funded by the community programme eContentplus between 2006 and 2008, which was aimed to provide services available on the web over old digitized maps from a group of partners over Europe including several National Libraries.
The MAtrixware REsearch Collection (MAREC) is a standardised patent data corpus available for research purposes. MAREC seeks to represent patent documents of several languages in order to answer specific research questions. It consists of 19 million patent documents in different languages, normalised to a highly specific XML schema.
BisQue is a free, open source web-based platform for the exchange and exploration of large, complex datasets. It is being developed at the Vision Research Lab at the University of California, Santa Barbara. BisQue specifically supports large scale, multi-dimensional multimodal-images and image analysis. Metadata is stored as arbitrarily nested and linked tag/value pairs, allowing for domain-specific data organization. Image analysis modules can be added to perform complex analysis tasks on compute clusters. Analysis results are stored within the database for further querying and processing. The data and analysis provenance is maintained for reproducibility of results. BisQue can be easily deployed in cloud computing environments or on computer clusters for scalability. BisQue has been integrated into the NSF Cyberinfrastructure project CyVerse. The user interacts with BisQue via any modern web browser.
Evaluation measures for an information retrieval (IR) system assess how well an index, search engine or database returns results from a collection of resources that satisfy a user's query. They are therefore fundamental to the success of information systems and digital platforms. The success of an IR system may be judged by a range of criteria including relevance, speed, user satisfaction, usability, efficiency and reliability. However, the most important factor in determining a system's effectiveness for users is the overall relevance of results retrieved in response to a query. Evaluation measures may be categorised in various ways including offline or online, user-based or system-based and include methods such as observed user behaviour, test collections, precision and recall, and scores from prepared benchmark test sets.