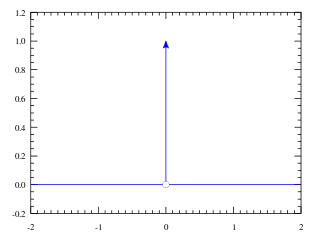
In mathematical analysis, the Dirac delta distribution, also known as the unit impulse, is a generalized function or distribution over the real numbers, whose value is zero everywhere except at zero, and whose integral over the entire real line is equal to one.
In probability theory, the central limit theorem (CLT) states that, under appropriate conditions, the distribution of a normalized version of the sample mean converges to a standard normal distribution. This holds even if the original variables themselves are not normally distributed. There are several versions of the CLT, each applying in the context of different conditions.
In probability theory, there exist several different notions of convergence of sequences of random variables. The different notions of convergence capture different properties about the sequence, with some notions of convergence being stronger than others. For example, convergence in distribution tells us about the limit distribution of a sequence of random variables. This is a weaker notion than convergence in probability, which tells us about the value a random variable will take, rather than just the distribution.

In mathematics, the Wiener process is a real-valued continuous-time stochastic process named in honor of American mathematician Norbert Wiener for his investigations on the mathematical properties of the one-dimensional Brownian motion. It is often also called Brownian motion due to its historical connection with the physical process of the same name originally observed by Scottish botanist Robert Brown. It is one of the best known Lévy processes and occurs frequently in pure and applied mathematics, economics, quantitative finance, evolutionary biology, and physics.
In probability theory, Chebyshev's inequality provides an upper bound on the probability of deviation of a random variable from its mean. More specifically, the probability that a random variable deviates from its mean by more than is at most , where is any positive constant.
![<span class="mw-page-title-main">Law of large numbers</span> Averages of repeated trials converge to the [[expected value]]](https://upload.wikimedia.org/wikipedia/commons/thumb/3/3a/Standard_deviation_diagram_micro.svg/320px-Standard_deviation_diagram_micro.svg.png)
In probability theory, the law of large numbers (LLN) is a mathematical theorem that states that the average of the results obtained from a large number of independent and identical random samples converges to the true value, if it exists. More formally, the LLN states that given a sample of independent and identically distributed values, the sample mean converges to the true mean.
In probability theory, Markov's inequality gives an upper bound on the probability that a non-negative random variable is greater than or equal to some positive constant. It is named after the Russian mathematician Andrey Markov, although it appeared earlier in the work of Pafnuty Chebyshev, and many sources, especially in analysis, refer to it as Chebyshev's inequality or Bienaymé's inequality. Markov's inequality is tight in the sense that for each chosen positive constant, there exists a random variable such that the inequality is in fact an equality.
In mathematics, the Fourier inversion theorem says that for many types of functions it is possible to recover a function from its Fourier transform. Intuitively it may be viewed as the statement that if we know all frequency and phase information about a wave then we may reconstruct the original wave precisely.
In information theory, Shannon's source coding theorem establishes the statistical limits to possible data compression for data whose source is an independent identically-distributed random variable, and the operational meaning of the Shannon entropy.
In mathematics, the Riemann–Lebesgue lemma, named after Bernhard Riemann and Henri Lebesgue, states that the Fourier transform or Laplace transform of an L1 function vanishes at infinity. It is of importance in harmonic analysis and asymptotic analysis.

In statistics, an empirical distribution function is the distribution function associated with the empirical measure of a sample. This cumulative distribution function is a step function that jumps up by 1/n at each of the n data points. Its value at any specified value of the measured variable is the fraction of observations of the measured variable that are less than or equal to the specified value.
In the theory of probability, the Glivenko–Cantelli theorem, named after Valery Ivanovich Glivenko and Francesco Paolo Cantelli, describes the asymptotic behaviour of the empirical distribution function as the number of independent and identically distributed observations grows. Specifically, the empirical distribution function converges uniformly to the true distribution function almost surely.
In the mathematical theory of probability, a Doob martingale is a stochastic process that approximates a given random variable and has the martingale property with respect to the given filtration. It may be thought of as the evolving sequence of best approximations to the random variable based on information accumulated up to a certain time.

In the theory of probability and statistics, the Dvoretzky–Kiefer–Wolfowitz–Massart inequality provides a bound on the worst case distance of an empirically determined distribution function from its associated population distribution function. It is named after Aryeh Dvoretzky, Jack Kiefer, and Jacob Wolfowitz, who in 1956 proved the inequality
In mathematics, Dvoretzky's theorem is an important structural theorem about normed vector spaces proved by Aryeh Dvoretzky in the early 1960s, answering a question of Alexander Grothendieck. In essence, it says that every sufficiently high-dimensional normed vector space will have low-dimensional subspaces that are approximately Euclidean. Equivalently, every high-dimensional bounded symmetric convex set has low-dimensional sections that are approximately ellipsoids.
In probability theory and theoretical computer science, McDiarmid's inequality is a concentration inequality which bounds the deviation between the sampled value and the expected value of certain functions when they are evaluated on independent random variables. McDiarmid's inequality applies to functions that satisfy a bounded differences property, meaning that replacing a single argument to the function while leaving all other arguments unchanged cannot cause too large of a change in the value of the function.
In mathematics, uniform integrability is an important concept in real analysis, functional analysis and measure theory, and plays a vital role in the theory of martingales.
Beliefs depend on the available information. This idea is formalized in probability theory by conditioning. Conditional probabilities, conditional expectations, and conditional probability distributions are treated on three levels: discrete probabilities, probability density functions, and measure theory. Conditioning leads to a non-random result if the condition is completely specified; otherwise, if the condition is left random, the result of conditioning is also random.
Uncertainty theory is a branch of mathematics based on normality, monotonicity, self-duality, countable subadditivity, and product measure axioms.
In probability theory, Kolmogorov's two-series theorem is a result about the convergence of random series. It follows from Kolmogorov's inequality and is used in one proof of the strong law of large numbers.




























