Information retrieval (IR) in computing and information science is the process of obtaining information system resources that are relevant to an information need from a collection of those resources. Searches can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.
Wide Area Information Server (WAIS) is a client–server text searching system that uses the ANSI Standard Z39.50 Information Retrieval Service Definition and Protocol Specifications for Library Applications" (Z39.50:1988) to search index databases on remote computers. It was developed in 1990 as a project of Thinking Machines, Apple Computer, Dow Jones, and KPMG Peat Marwick.
A document management system (DMS) is usually a computerized system used to store, share, track and manage files or documents. Some systems include history tracking where a log of the various versions created and modified by different users is recorded. The term has some overlap with the concepts of content management systems. It is often viewed as a component of enterprise content management (ECM) systems and related to digital asset management, document imaging, workflow systems and records management systems.
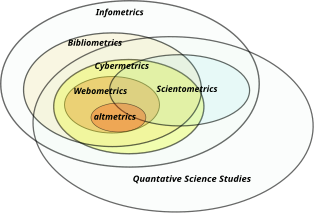
Information science is an academic field which is primarily concerned with analysis, collection, classification, manipulation, storage, retrieval, movement, dissemination, and protection of information. Practitioners within and outside the field study the application and the usage of knowledge in organizations in addition to the interaction between people, organizations, and any existing information systems with the aim of creating, replacing, improving, or understanding the information systems.
Music information retrieval (MIR) is the interdisciplinary science of retrieving information from music. MIR is a small but growing field of research with many real-world applications. Those involved in MIR may have a background in academic musicology, psychoacoustics, psychology, signal processing, informatics, machine learning, optical music recognition, computational intelligence or some combination of these.
An image retrieval system is a computer system used for browsing, searching and retrieving images from a large database of digital images. Most traditional and common methods of image retrieval utilize some method of adding metadata such as captioning, keywords, title or descriptions to the images so that retrieval can be performed over the annotation words. Manual image annotation is time-consuming, laborious and expensive; to address this, there has been a large amount of research done on automatic image annotation. Additionally, the increase in social web applications and the semantic web have inspired the development of several web-based image annotation tools.
Apache Lucene is a free and open-source search engine software library, originally written in Java by Doug Cutting. It is supported by the Apache Software Foundation and is released under the Apache Software License. Lucene is widely used as a standard foundation for non-research search applications.

The Entrez Global Query Cross-Database Search System is a federated search engine, or web portal that allows users to search many discrete health sciences databases at the National Center for Biotechnology Information (NCBI) website. The NCBI is a part of the National Library of Medicine (NLM), which is itself a department of the National Institutes of Health (NIH), which in turn is a part of the United States Department of Health and Human Services. The name "Entrez" was chosen to reflect the spirit of welcoming the public to search the content available from the NLM.
Z39.50 is an international standard client–server, application layer communications protocol for searching and retrieving information from a database over a TCP/IP computer network, developed and maintained by the Library of Congress. It is covered by ANSI/NISO standard Z39.50, and ISO standard 23950.
In text retrieval, full-text search refers to techniques for searching a single computer-stored document or a collection in a full-text database. Full-text search is distinguished from searches based on metadata or on parts of the original texts represented in databases.

The following outline is provided as an overview of and topical guide to library science:
Isearch is open-source text retrieval software first developed in 1994 by Nassib Nassar as part of the Isite Z39.50 information framework. The project started at the Clearinghouse for Networked Information Discovery and Retrieval (CNIDR) of the North Carolina supercomputing center MCNC and funded by the National Science Foundation to follow in the track of WAIS and develop prototype systems for distributed information networks encompassing Internet applications, library catalogs and other information resources.
The Lemur Project is a collaboration between the Center for Intelligent Information Retrieval at the University of Massachusetts Amherst and the Language Technologies Institute at Carnegie Mellon University. The Lemur Project develops search engines, browser toolbars, text analysis tools, and data resources that support research and development of information retrieval and text mining software. The project is best known for its Indri and Galago search engines, the ClueWeb09 and ClueWeb12 datasets, and the RankLib learning-to-rank library. The software and datasets are used widely in scientific and research applications, as well as in some commercial applications.
Xapian is a free and open-source probabilistic information retrieval library, released under the GNU General Public License (GPL). It is a full-text search engine library for programmers.
Zettair is a compact text search engine for indexing and search of HTML collections. It is an open source software developed by a group of researchers at RMIT University.
BRS/Search is a full-text database and information retrieval system. BRS/Search uses a fully inverted indexing system to store, locate, and retrieve unstructured data. It was the search engine that in 1977 powered Bibliographic Retrieval Services (BRS) commercial operations with 20 databases ; it has changed ownership several times during its development and is currently sold as Livelink ECM Discovery Server by Open Text Corporation.
Faceted search is a technique that involves augmenting traditional search techniques with a faceted navigation system, allowing users to narrow down search results by applying multiple filters based on faceted classification of the items. It is sometimes referred to as a parametric search technique. A faceted classification system classifies each information element along multiple explicit dimensions, called facets, enabling the classifications to be accessed and ordered in multiple ways rather than in a single, pre-determined, taxonomic order.
ISO 25964 is the international standard for thesauri, published in two parts as follows:
ISO 25964 Information and documentation - Thesauri and interoperability with other vocabulariesPart 1: Thesauri for information retrieval [published August 2011] Part 2: Interoperability with other vocabularies [published March 2013]
The Clearinghouse for Networked Information Discovery and Retrieval or CNIDR was an organization funded by the U.S. National Science Foundation from 1993 to 1997 and based at the Microelectronics Center of North Carolina (MCNC) in Research Triangle Park. CNIDR was active in the research and development of open source software and open standards, centered on information discovery and retrieval, in the emerging Internet.
Semantic Scholar is an artificial intelligence–powered research tool for scientific literature developed at the Allen Institute for AI and publicly released in November 2015. It uses advances in natural language processing to provide summaries for scholarly papers. The Semantic Scholar team is actively researching the use of artificial-intelligence in natural language processing, machine learning, Human-Computer interaction, and information retrieval.