Background
Dependencies
When attempting to execute instructions out of order, a microprocessor must respect true dependencies between instructions. For example, consider a simple true dependence:
1: add $1, $2, $3 # R1 <= R2 + R3 2: add $5, $1, $4 # R5 <= R1 + R4 (dependent on 1)
In this example, the add instruction on line 2 is dependent on the add instruction on line 1 because the register R1 is a source operand of the addition operation on line 2. The add on line 2 cannot execute until the add on line 1 completes. In this case, the dependence is static and easily determined by a microprocessor, because the sources and destinations are registers. The destination register of the add instruction on line 1 (R1) is part of the instruction encoding, and so can be determined by the microprocessor early on, during the decode stage of the pipeline. Similarly, the source registers of the add instruction on line 2 (R1 and R4) are also encoded into the instruction itself and are determined in decode. To respect this true dependence, the microprocessor's scheduler logic will issue these instructions in the correct order (instruction 1 first, followed by instruction 2) so that the results of 1 are available when instruction 2 needs them.
Complications arise when the dependence is not statically determinable. Such non-static dependencies arise with memory instructions (loads and stores) because the location of the operand may be indirectly specified as a register operand rather than directly specified in the instruction encoding itself.
1: store $1, 2($2) # Mem[R2+2] <= R1 2: load $3, 4($4) # R3 <= Mem[R4+4] (possibly dependent on 1, possible same address as above)
Here, the store instruction writes a value to the memory location specified by the value in the address (R2+2), and the load instruction reads the value at the memory location specified by the value in address (R4+4). The microprocessor cannot statically determine, prior to execution, if the memory locations specified in these two instructions are different, or are the same location, because the locations depend on the values in R2 and R4. If the locations are different, the instructions are independent and can be successfully executed out of order. However, if the locations are the same, then the load instruction is dependent on the store to produce its value. This is known as an ambiguous dependence.
Out-of-order execution and memory access operations
Executing loads and stores out of order can produce incorrect results if a dependent load/store pair was executed out of order. Consider the following code snippet, given in MIPS assembly:
1: div $27, $20 2: sw $27, 0($30) 3: lw $08, 0($31) 4: sw $26, 0($30) 5: lw $09, 0($31)
Assume that the scheduling logic will issue an instruction to the execution unit when all of its register operands are ready. Further, assume that registers $30 and $31 are ready: the values in $30 and $31 were computed a long time ago and have not changed. However, assume $27 is not ready: its value is still in the process of being computed by the div (integer divide) instruction. Finally, assume that registers $30 and $31 hold the same value, and thus all the loads and stores in the snippet access the same memory word.
In this situation, the sw $27, 0($30) instruction on line 2 is not ready to execute, but the lw $08, 0($31) instruction on line 3 is ready. If the processor allows the lw instruction to execute before the sw, the load will read an old value from the memory system; however, it should have read the value that was just written there by the sw. The load and store were executed out of program order, but there was a memory dependence between them that was violated.
Similarly, assume that register $26is ready. The sw $26, 0($30) instruction on line 4 is also ready to execute, and it may execute before the preceding lw $08, 0($31) on line 3. If this occurs, the lw $08, 0($31) instruction will read the wrong value from the memory system, since a later store instruction wrote its value there before the load executed.
Characterization of memory dependencies
Memory dependencies come in three flavors:
- Read-After-Write (RAW) dependencies: Also known as true dependencies, RAW dependencies arise when a load operation reads a value from memory that was produced by the most recent preceding store operation to that same address.
- Write-After-Read (WAR) dependencies: Also known as anti dependencies, WAR dependencies arise when a store operation writes a value to memory that a preceding load reads.
- Write-After-Write (WAW) dependencies: Also known as output dependencies, WAW dependencies arise when two store operations write values to the same memory address.
The three dependencies are shown in the preceding code segment (reproduced for clarity):
1: div $27, $20 2: sw $27, 0($30) 3: lw $08, 0($31) 4: sw $26, 0($30) 5: lw $09, 0($31)
- The
lw $08, 0($31) instruction on line 3 has a RAW dependence on the sw $27, 0($30) instruction on line 2, and the lw $09, 0($31) instruction on line 5 has a RAW dependence on the sw $26, 0($30) instruction on line 4. Both load instructions read the memory address that the preceding stores wrote. The stores were the most recent producers to that memory address, and the loads are reading that memory address's value. - The
sw $26, 0($30) instruction on line 4 has a WAR dependence on the lw $08, 0($31) instruction on line 3 since it writes the memory address that the preceding load reads from. - The
sw $26, 0($30) instruction on line 4 has a WAW dependence on the sw $27, 0($30) instruction on line 2 since both stores write to the same memory address.
Memory disambiguation mechanisms
Modern microprocessors use the following mechanisms, implemented in hardware, to resolve ambiguous dependences and recover when a dependence was violated.
Avoiding WAR and WAW dependencies
Values from store instructions are not committed to the memory system (in modern microprocessors, CPU cache) when they execute. Instead, the store instructions, including the memory address and store data, are buffered in a store queue until they reach the retirement point. When a store retires, it then writes its value to the memory system. This avoids the WAR and WAW dependence problems shown in the code snippet above where an earlier load receives an incorrect value from the memory system because a later store was allowed to execute before the earlier load.
Additionally, buffering stores until retirement allows processors to speculatively execute store instructions that follow an instruction that may produce an exception (such as a load of a bad address, divide by zero, etc.) or a conditional branch instruction whose direction (taken or not taken) is not yet known. If the exception-producing instruction has not executed or the branch direction was predicted incorrectly, the processor will have fetched and executed instructions on a "wrong path." These instructions should not have been executed at all; the exception condition should have occurred before any of the speculative instructions executed, or the branch should have gone the other direction and caused different instructions to be fetched and executed. The processor must "throw away" any results from the bad-path, speculatively-executed instructions when it discovers the exception or branch misprediction. The complication for stores is that any stores on the bad or mispredicted path should not have committed their values to the memory system; if the stores had committed their values, it would be impossible to "throw away" the commit, and the memory state of the machine would be corrupted by data from a store instruction that should not have executed.
Thus, without store buffering, stores cannot execute until all previous possibly-exception-causing instructions have executed (and not caused an exception) and all previous branch directions are known. Forcing stores to wait until branch directions and exceptions are known significantly reduces the out-of-order aggressiveness and limits ILP (Instruction level parallelism) and performance. With store buffering, stores can execute ahead of exception-causing or unresolved branch instructions, buffering their data in the store queue but not committing their values until retirement. This prevents stores on mispredicted or bad paths from committing their values to the memory system while still offering the increased ILP and performance from full out-of-order execution of stores.
Store to load forwarding
Buffering stores until retirement avoids WAW and WAR dependencies but introduces a new issue. Consider the following scenario: a store executes and buffers its address and data in the store queue. A few instructions later, a load executes that reads from the same memory address to which the store just wrote. If the load reads its data from the memory system, it will read an old value that would have been overwritten by the preceding store. The data obtained by the load will be incorrect.
To solve this problem, processors employ a technique called store-to-load forwarding using the store queue. In addition to buffering stores until retirement, the store queue serves a second purpose: forwarding data from completed but not-yet-retired ("in-flight") stores to later loads. Rather than a simple FIFO queue, the store queue is really a Content-Addressable Memory (CAM) searched using the memory address. When a load executes, it searches the store queue for in-flight stores to the same address that are logically earlier in program order. If a matching store exists, the load obtains its data value from that store instead of the memory system. If there is no matching store, the load accesses the memory system as usual; any preceding, matching stores must have already retired and committed their values. This technique allows loads to obtain correct data if their producer store has completed but not yet retired.
Multiple stores to the load's memory address may be present in the store queue. To handle this case, the store queue is priority encoded to select the latest store that is logically earlier than the load in program order. The determination of which store is "latest" can be achieved by attaching some sort of timestamp to the instructions as they are fetched and decoded, or alternatively by knowing the relative position (slot) of the load with respect to the oldest and newest stores within the store queue.
RAW dependence violations
Detecting RAW dependence violations
Modern out-of-order CPUs can use a number of techniques to detect a RAW dependence violation, but all techniques require tracking in-flight loads from execution until retirement. When a load executes, it accesses the memory system and/or store queue to obtain its data value, and then its address and data are buffered in a load queue until retirement. The load queue is similar in structure and function to the store queue, and in fact in some processors may be combined with the store queue in a single structure called a load-store queue, or LSQ. The following techniques are used or have been proposed to detect RAW dependence violations:
Load queue CAM search
With this technique, the load queue, like the store queue, is a CAM searched using the memory access address, and keeps track of all in-flight loads. When a store executes, it searches the load queue for completed loads from the same address that are logically later in program order. If such a matching load exists, it must have executed before the store and thus read an incorrect, old value from the memory system/store queue. Any instructions that used the load's value have also used bad data. To recover if such a violation is detected, the load is marked as "violated" in the retirement buffer. The store remains in the store queue and retirement buffer and retires normally, committing its value to the memory system when it retires. However, when the violated load reaches the retirement point, the processor flushes the pipeline and restarts execution from the load instruction. At this point, all previous stores have committed their values to the memory system. The load instruction will now read the correct value from the memory system, and any dependent instructions will re-execute using the correct value.
This technique requires an associative search of the load queue on every store execution, which consumes circuit power and can prove to be a difficult timing path for large load queues. However, it does not require any additional memory (cache) ports or create resource conflicts with other loads or stores that are executing.
Disambiguation at retirement
With this technique, load instructions that have executed out-of-order are re-executed (they access the memory system and read the value from their address a second time) when they reach the retirement point. Since the load is now the retiring instruction, it has no dependencies on any instruction still in-flight; all stores ahead of it have committed their values to the memory system, and so any value read from the memory system is guaranteed to be correct. The value read from memory at re-execution time is compared to the value obtained when the load first executed. If the values are the same, the original value was correct and no violation has occurred. If the re-execution value differs from the original value, a RAW violation has occurred and the pipeline must be flushed because instructions dependent on the load have used an incorrect value.
This technique is conceptually simpler than the load queue search, and it eliminates a second CAM and its power-hungry search (the load queue can now be a simple FIFO queue). Since the load must re-access the memory system just before retirement, the access must be very fast, so this scheme relies on a fast cache. No matter how fast the cache is, however, the second memory system access for every out-of-order load instruction does increase instruction retirement latency and increases the total number of cache accesses that must be performed by the processor. The additional retire-time cache access can be satisfied by re-using an existing cache port; however, this creates port resource contention with other loads and stores in the processor trying to execute, and thus may cause a decrease in performance. Alternatively, an additional cache port can be added just for load disambiguation, but this increases the complexity, power, and area of the cache. Some recent work (Roth 2005) has shown ways to filter many loads from re-executing if it is known that no RAW dependence violation could have occurred; such a technique would help or eliminate such latency and resource contention.
A minor benefit of this scheme (compared to a load-queue search) is that it will not flag a RAW dependence violation and trigger a pipeline flush if a store that would have caused a RAW dependence violation (the store's address matches an in-flight load's address) has a data value that matches the data value already in the cache. In the load-queue search scheme, an additional data comparison would need to be added to the load-queue search hardware to prevent such a pipeline flush.
Avoiding RAW dependence violations
CPUs that fully support out-of-order execution of loads and stores must be able to detect RAW dependence violations when they occur. However, many CPUs avoid this problem by forcing all loads and stores to execute in-order, or by supporting only a limited form of out-of-order load/store execution. This approach offers lower performance compared to supporting full out-of-order load/store execution, but it can significantly reduce the complexity of the execution core and caches.
The first option, making loads and stores go in-order, avoids RAW dependences because there is no possibility of a load executing before its producer store and obtaining incorrect data. Another possibility is to effectively break loads and stores into two operations: address generation and cache access. With these two separate but linked operations, the CPU can allow loads and stores to access the memory system only once all previous loads and stores have had their address generated and buffered in the LSQ. After address generation, there are no longer any ambiguous dependencies since all addresses are known, and so dependent loads will not be executed until their corresponding stores complete. This scheme still allows for some "out-of-orderness" — the address generation operations for any in-flight loads and stores can execute out-of-order, and once addresses have been generated, the cache accesses for each load or store can happen in any order that respects the (now known) true dependences.
In computing, a context switch is the process of storing the state of a process or thread, so that it can be restored and resume execution at a later point, and then restoring a different, previously saved, state. This allows multiple processes to share a single central processing unit (CPU), and is an essential feature of a multitasking operating system. In a traditional CPU, each process - a program in execution - utilizes the various CPU registers to store data and hold the current state of the running process. However, in a multitasking operating system, the operating system switches between processes or threads to allow the execution of multiple processes simultaneously. For every switch, the operating system must save the state of the currently running process, followed by loading the next process state, which will run on the CPU. This sequence of operations that stores the state of the running process and the loading of the following running process is called a context switch.
A complex instruction set computer is a computer architecture in which single instructions can execute several low-level operations or are capable of multi-step operations or addressing modes within single instructions. The term was retroactively coined in contrast to reduced instruction set computer (RISC) and has therefore become something of an umbrella term for everything that is not RISC, where the typical differentiating characteristic is that most RISC designs use uniform instruction length for almost all instructions, and employ strictly separate load and store instructions.
A re-order buffer (ROB) is a hardware unit used in an extension to the Tomasulo algorithm to support out-of-order and speculative instruction execution. The extension forces instructions to be committed in-order.
Tomasulo's algorithm is a computer architecture hardware algorithm for dynamic scheduling of instructions that allows out-of-order execution and enables more efficient use of multiple execution units. It was developed by Robert Tomasulo at IBM in 1967 and was first implemented in the IBM System/360 Model 91’s floating point unit.
In computer architecture, register renaming is a technique that abstracts logical registers from physical registers. Every logical register has a set of physical registers associated with it. When a machine language instruction refers to a particular logical register, the processor transposes this name to one specific physical register on the fly. The physical registers are opaque and cannot be referenced directly but only via the canonical names.
Fetching the instruction opcodes from program memory well in advance is known as prefetching and it is served by using prefetch input queue (PIQ).The pre-fetched instructions are stored in data structure - namely a queue. The fetching of opcodes well in advance, prior to their need for execution increases the overall efficiency of the processor boosting its speed. The processor no longer has to wait for the memory access operations for the subsequent instruction opcode to complete. This architecture was prominently used in the Intel 8086 microprocessor.
In computer science, computer engineering and programming language implementations, a stack machine is a computer processor or a virtual machine in which the primary interaction is moving short-lived temporary values to and from a push down stack. In the case of a hardware processor, a hardware stack is used. The use of a stack significantly reduces the required number of processor registers. Stack machines extend push-down automata with additional load/store operations or multiple stacks and hence are Turing-complete.
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost to access data from the main memory. A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels, with different instruction-specific and data-specific caches at level 1. The cache memory is typically implemented with static random-access memory (SRAM), in modern CPUs by far the largest part of them by chip area, but SRAM is not always used for all levels, or even any level, sometimes some latter or all levels are implemented with eDRAM.
In computer engineering, out-of-order execution is a paradigm used in most high-performance central processing units to make use of instruction cycles that would otherwise be wasted. In this paradigm, a processor executes instructions in an order governed by the availability of input data and execution units, rather than by their original order in a program. In doing so, the processor can avoid being idle while waiting for the preceding instruction to complete and can, in the meantime, process the next instructions that are able to run immediately and independently.

The POWER3 is a microprocessor, designed and exclusively manufactured by IBM, that implemented the 64-bit version of the PowerPC instruction set architecture (ISA), including all of the optional instructions of the ISA such as instructions present in the POWER2 version of the POWER ISA but not in the PowerPC ISA. It was introduced on 5 October 1998, debuting in the RS/6000 43P Model 260, a high-end graphics workstation. The POWER3 was originally supposed to be called the PowerPC 630 but was renamed, probably to differentiate the server-oriented POWER processors it replaced from the more consumer-oriented 32-bit PowerPCs. The POWER3 was the successor of the P2SC derivative of the POWER2 and completed IBM's long-delayed transition from POWER to PowerPC, which was originally scheduled to conclude in 1995. The POWER3 was used in IBM RS/6000 servers and workstations at 200 MHz. It competed with the Digital Equipment Corporation (DEC) Alpha 21264 and the Hewlett-Packard (HP) PA-8500.

The R10000, code-named "T5", is a RISC microprocessor implementation of the MIPS IV instruction set architecture (ISA) developed by MIPS Technologies, Inc. (MTI), then a division of Silicon Graphics, Inc. (SGI). The chief designers are Chris Rowen and Kenneth C. Yeager. The R10000 microarchitecture is known as ANDES, an abbreviation for Architecture with Non-sequential Dynamic Execution Scheduling. The R10000 largely replaces the R8000 in the high-end and the R4400 elsewhere. MTI was a fabless semiconductor company; the R10000 was fabricated by NEC and Toshiba. Previous fabricators of MIPS microprocessors such as Integrated Device Technology (IDT) and three others did not fabricate the R10000 as it was more expensive to do so than the R4000 and R4400.

The R4000 is a microprocessor developed by MIPS Computer Systems that implements the MIPS III instruction set architecture (ISA). Officially announced on 1 October 1991, it was one of the first 64-bit microprocessors and the first MIPS III implementation. In the early 1990s, when RISC microprocessors were expected to replace CISC microprocessors such as the Intel i486, the R4000 was selected to be the microprocessor of the Advanced Computing Environment (ACE), an industry standard that intended to define a common RISC platform. ACE ultimately failed for a number of reasons, but the R4000 found success in the workstation and server markets.
The R8000 is a microprocessor chipset developed by MIPS Technologies, Inc. (MTI), Toshiba, and Weitek. It was the first implementation of the MIPS IV instruction set architecture. The R8000 is also known as the TFP, for Tremendous Floating-Point, its name during development.
Memory dependence prediction is a technique, employed by high-performance out-of-order execution microprocessors that execute memory access operations out of program order, to predict true dependencies between loads and stores at instruction execution time. With the predicted dependence information, the processor can then decide to speculatively execute certain loads and stores out of order, while preventing other loads and stores from executing out-of-order. Later in the pipeline, memory disambiguation techniques are used to determine if the loads and stores were correctly executed and, if not, to recover.
Memory ordering describes the order of accesses to computer memory by a CPU. The term can refer either to the memory ordering generated by the compiler during compile time, or to the memory ordering generated by a CPU during runtime.
Runahead is a technique that allows a microprocessor to pre-process instructions during cache miss cycles instead of stalling. The pre-processed instructions are used to generate instruction and data stream prefetches by detecting cache misses before they would otherwise occur by using the idle execution resources to calculate instruction and data stream fetch addresses using the available information that is independent of the cache miss.
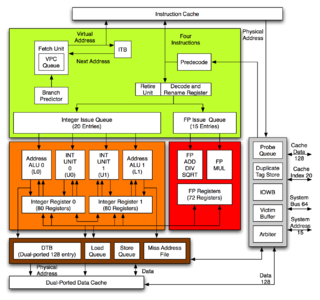
The Alpha 21264 is a Digital Equipment Corporation RISC microprocessor launched on 19 October 1998. The 21264 implemented the Alpha instruction set architecture (ISA).

The PA-8000 (PCX-U), code-named Onyx, is a microprocessor developed and fabricated by Hewlett-Packard (HP) that implemented the PA-RISC 2.0 instruction set architecture (ISA). It was a completely new design with no circuitry derived from previous PA-RISC microprocessors. The PA-8000 was introduced on 2 November 1995 when shipments began to members of the Precision RISC Organization (PRO). It was used exclusively by PRO members and was not sold on the merchant market. All follow-on PA-8x00 processors are based on the basic PA-8000 processor core.
Processor Consistency is one of the consistency models used in the domain of concurrent computing.
Latency oriented processor architecture is the microarchitecture of a microprocessor designed to serve a serial computing thread with a low latency. This is typical of most central processing units (CPU) being developed since the 1970s. These architectures, in general, aim to execute as many instructions as possible belonging to a single serial thread, in a given window of time; however, the time to execute a single instruction completely from fetch to retire stages may vary from a few cycles to even a few hundred cycles in some cases. Latency oriented processor architectures are the opposite of throughput-oriented processors which concern themselves more with the total throughput of the system, rather than the service latencies for all individual threads that they work on.