A document type definition (DTD) is a set of markup declarations that define a document type for an SGML-family markup language.
In computing, a namespace is a set of signs (names) that are used to identify and refer to objects of various kinds. A namespace ensures that all of a given set of objects have unique names so that they can be easily identified.
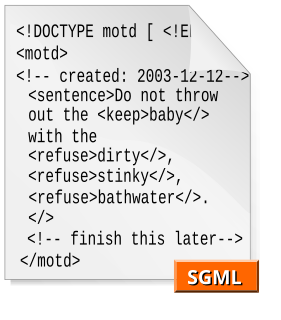
The Standard Generalized Markup Language is a standard for defining generalized markup languages for documents. ISO 8879 Annex A.1 states that generalized markup is "based on two postulates":
A Uniform Resource Identifier (URI) is a unique sequence of characters that identifies a logical or physical resource used by web technologies. URIs may be used to identify anything, including real-world objects, such as people and places, concepts, or information resources such as web pages and books. Some URIs provide a means of locating and retrieving information resources on a network ; these are Uniform Resource Locators (URLs). A URL provides the location of the resource. A URI identifies the resource by name at the specified location or URL. Other URIs provide only a unique name, without a means of locating or retrieving the resource or information about it, these are Uniform Resource Names (URNs). The web technologies that use URIs are not limited to web browsers. URIs are used to identify anything described using the Resource Description Framework (RDF), for example, concepts that are part of an ontology defined using the Web Ontology Language (OWL), and people who are described using the Friend of a Friend vocabulary would each have an individual URI.

Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.
DocBook is a semantic markup language for technical documentation. It was originally intended for writing technical documents related to computer hardware and software, but it can be used for any other sort of documentation.
XSD, a recommendation of the World Wide Web Consortium (W3C), specifies how to formally describe the elements in an Extensible Markup Language (XML) document. It can be used by programmers to verify each piece of item content in a document, to assure it adheres to the description of the element it is placed in.
The Geography Markup Language (GML) is the XML grammar defined by the Open Geospatial Consortium (OGC) to express geographical features. GML serves as a modeling language for geographic systems as well as an open interchange format for geographic transactions on the Internet. Key to GML's utility is its ability to integrate all forms of geographic information, including not only conventional "vector" or discrete objects, but coverages and sensor data.
In computing, RELAX NG is a schema language for XML—a RELAX NG schema specifies a pattern for the structure and content of an XML document. A RELAX NG schema is itself an XML document but RELAX NG also offers a popular compact, non-XML syntax. Compared to other XML schema languages RELAX NG is considered relatively simple.
XML Signature defines an XML syntax for digital signatures and is defined in the W3C recommendation XML Signature Syntax and Processing. Functionally, it has much in common with PKCS #7 but is more extensible and geared towards signing XML documents. It is used by various Web technologies such as SOAP, SAML, and others.
An XML schema is a description of a type of XML document, typically expressed in terms of constraints on the structure and content of documents of that type, above and beyond the basic syntactical constraints imposed by XML itself. These constraints are generally expressed using some combination of grammatical rules governing the order of elements, Boolean predicates that the content must satisfy, data types governing the content of elements and attributes, and more specialized rules such as uniqueness and referential integrity constraints.
XML namespaces are used for providing uniquely named elements and attributes in an XML document. They are defined in a W3C recommendation. An XML instance may contain element or attribute names from more than one XML vocabulary. If each vocabulary is given a namespace, the ambiguity between identically named elements or attributes can be resolved.
RDFa or Resource Description Framework in Attributes is a W3C Recommendation that adds a set of attribute-level extensions to HTML, XHTML and various XML-based document types for embedding rich metadata within Web documents. The Resource Description Framework (RDF) data-model mapping enables its use for embedding RDF subject-predicate-object expressions within XHTML documents. It also enables the extraction of RDF model triples by compliant user agents.
XML documents have a hierarchical structure and can conceptually be interpreted as a tree structure, called an XML tree.
Canonical XML is a normal form of XML, intended to allow relatively simple comparison of pairs of XML documents for equivalence; for this purpose, the Canonical XML transformation removes non-meaningful differences between the documents. Any XML document can be converted to Canonical XML.
The Open Packaging Conventions (OPC) is a container-file technology initially created by Microsoft to store a combination of XML and non-XML files that together form a single entity such as an Open XML Paper Specification (OpenXPS) document. OPC-based file formats combine the advantages of leaving the independent file entities embedded in the document intact and resulting in much smaller files compared to normal use of XML.
The Internationalization Tag Set (ITS) is a set of attributes and elements designed to provide internationalization and localization support in XML documents.
An Extensible Resource Identifier is a scheme and resolution protocol for abstract identifiers compatible with Uniform Resource Identifiers and Internationalized Resource Identifiers, developed by the XRI Technical Committee at OASIS. The goal of XRI was a standard syntax and discovery format for abstract, structured identifiers that are domain-, location-, application-, and transport-independent, so they can be shared across any number of domains, directories, and interaction protocols.
In computer programming, a fully qualified name is an unambiguous name that specifies which object, function, or variable a call refers to without regard to the context of the call. In a hierarchical structure, a name is fully qualified when it "is complete in the sense that it includes (a) all names in the hierarchic sequence above the given element and (b) the name of the given element itself."