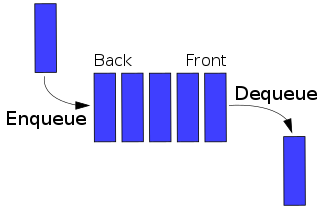
In computer science, a double-ended queue is an abstract data type that generalizes a queue, for which elements can be added to or removed from either the front (head) or back (tail). It is also often called a head-tail linked list, though properly this refers to a specific data structure implementation of a deque.
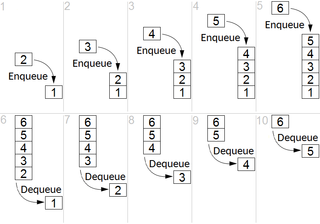
FIFO is an acronym for first in, first out, a method for organising and manipulating a data buffer, where the oldest (first) entry, or 'head' of the queue, is processed first. It is analogous to processing a queue with first-come, first-served (FCFS) behaviour: where the people leave the queue in the order in which they arrive.

In computer science, a heap is a specialized tree-based data structure which is essentially an almost complete tree that satisfies the heap property: in a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.

Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.
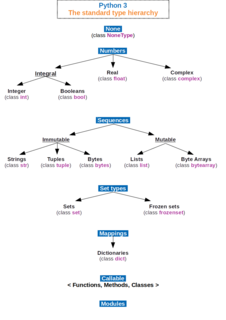
In computer science and computer programming, a data type or simply type is an attribute of data which tells the compiler or interpreter how the programmer intends to use the data. Most programming languages support common data types of real, integer and boolean. A data type constrains the values that an expression, such as a variable or a function, might take. This data type defines the operations that can be done on the data, the meaning of the data, and the way values of that type can be stored. A type of value from which an expression may take its value.
In computer science, a semaphore is a variable or abstract data type used to control access to a common resource by multiple processes in a concurrent system such as a multitasking operating system. A semaphore is simply a variable. This variable is used to solve critical section problems and to achieve process synchronization in the multi processing environment. A trivial semaphore is a plain variable that is changed depending on programmer-defined conditions.
In computer science, amortized analysis is a method for analyzing a given algorithm's complexity, or how much of a resource, especially time or memory, it takes to execute. The motivation for amortized analysis is that looking at the worst-case run time per operation, rather than per algorithm, can be too pessimistic.
In computer science, tree traversal is a form of graph traversal and refers to the process of visiting each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.
In concurrent programming, a monitor is a synchronization construct that allows threads to have both mutual exclusion and the ability to wait (block) for a certain condition to become true. Monitors also have a mechanism for signaling other threads that their condition has been met. A monitor consists of a mutex (lock) object and condition variables. A condition variable is basically a container of threads that are waiting for a certain condition. Monitors provide a mechanism for threads to temporarily give up exclusive access in order to wait for some condition to be met, before regaining exclusive access and resuming their task.
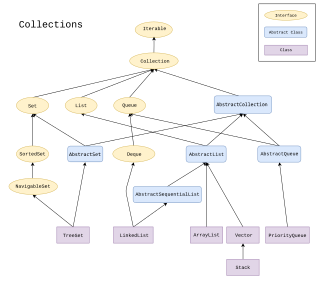
The Java collections framework is a set of classes and interfaces that implement commonly reusable collection data structures.
A calendar queue (CQ) is a priority queue. It is analogous to desk calendar, which is used by humans for ordering future events by date. Discrete event simulations require a future event list (FEL) structure that sorts pending events according to their time. Such simulators require a good and efficient data structure as time spent on queue management can be significant. The calendar queue can approach O(1) average performance.
In computer science, a double-ended priority queue (DEPQ) or double-ended heap is a data structure similar to a priority queue or heap, but allows for efficient removal of both the maximum and minimum, according to some ordering on the keys (items) stored in the structure. Every element in a DEPQ has a priority or value. In a DEPQ, it is possible to remove the elements in both ascending as well as descending order.

In computer science, a queap is a priority queue data structure. The data structure allows insertions and deletions of arbitrary elements, as well as retrieval of the highest-priority element. Each deletion takes amortized time logarithmic in the number of items that have been in the structure for a longer time than the removed item. Insertions take constant amortized time.
In computing, sequence containers refer to a group of container class templates in the standard library of the C++ programming language that implement storage of data elements. Being templates, they can be used to store arbitrary elements, such as integers or custom classes. One common property of all sequential containers is that the elements can be accessed sequentially. Like all other standard library components, they reside in namespace std.
In computer science, a randomized meldable heap is a priority queue based data structure in which the underlying structure is also a heap-ordered binary tree. However, there are no restrictions on the shape of the underlying binary tree.