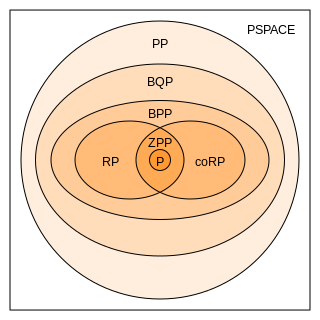
In computational complexity theory, bounded-error quantum polynomial time (BQP) is the class of decision problems solvable by a quantum computer in polynomial time, with an error probability of at most 1/3 for all instances. It is the quantum analogue to the complexity class BPP.

In mathematics, computable numbers are the real numbers that can be computed to within any desired precision by a finite, terminating algorithm. They are also known as the recursive numbers, effective numbers or the computable reals or recursive reals. The concept of a computable real number was introduced by Emile Borel in 1912, using the intuitive notion of computability available at the time.
In theoretical computer science and mathematics, computational complexity theory focuses on classifying computational problems according to their resource usage, and relating these classes to each other. A computational problem is a task solved by a computer. A computation problem is solvable by mechanical application of mathematical steps, such as an algorithm.

In computational complexity theory, NP is a complexity class used to classify decision problems. NP is the set of decision problems for which the problem instances, where the answer is "yes", have proofs verifiable in polynomial time by a deterministic Turing machine, or alternatively the set of problems that can be solved in polynomial time by a nondeterministic Turing machine.

In computational learning theory, probably approximately correct (PAC) learning is a framework for mathematical analysis of machine learning. It was proposed in 1984 by Leslie Valiant.

In theoretical computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.

In computational complexity theory, a complexity class is a set of computational problems "of related resource-based complexity". The two most commonly analyzed resources are time and memory.
In computer science, parameterized complexity is a branch of computational complexity theory that focuses on classifying computational problems according to their inherent difficulty with respect to multiple parameters of the input or output. The complexity of a problem is then measured as a function of those parameters. This allows the classification of NP-hard problems on a finer scale than in the classical setting, where the complexity of a problem is only measured as a function of the number of bits in the input. This appears to have been first demonstrated in Gurevich, Stockmeyer & Vishkin (1984). The first systematic work on parameterized complexity was done by Downey & Fellows (1999).
In computational complexity theory, P, also known as PTIME or DTIME(nO(1)), is a fundamental complexity class. It contains all decision problems that can be solved by a deterministic Turing machine using a polynomial amount of computation time, or polynomial time.

In computational complexity theory, the complexity class PH is the union of all complexity classes in the polynomial hierarchy:
In computational complexity theory, the polynomial hierarchy is a hierarchy of complexity classes that generalize the classes NP and co-NP. Each class in the hierarchy is contained within PSPACE. The hierarchy can be defined using oracle machines or alternating Turing machines. It is a resource-bounded counterpart to the arithmetical hierarchy and analytical hierarchy from mathematical logic. The union of the classes in the hierarchy is denoted PH.
In complexity theory, PP is the class of decision problems solvable by a probabilistic Turing machine in polynomial time, with an error probability of less than 1/2 for all instances. The abbreviation PP refers to probabilistic polynomial time. The complexity class was defined by Gill in 1977.
In theoretical computer science and cryptography, a pseudorandom generator (PRG) for a class of statistical tests is a deterministic procedure that maps a random seed to a longer pseudorandom string such that no statistical test in the class can distinguish between the output of the generator and the uniform distribution. The random seed itself is typically a short binary string drawn from the uniform distribution.
In computational complexity theory, P/poly is a complexity class representing problems that can be solved by small circuits. More precisely, it is the set of formal languages that have polynomial-size circuit families. It can also be defined equivalently in terms of Turing machines with advice, extra information supplied to the Turing machine along with its input, that may depend on the input length but not on the input itself. In this formulation, P/poly is the class of decision problems that can be solved by a polynomial-time Turing machine with advice strings of length polynomial in the input size. These two different definitions make P/poly central to circuit complexity and non-uniform complexity.
MAX-3SAT is a problem in the computational complexity subfield of computer science. It generalises the Boolean satisfiability problem (SAT) which is a decision problem considered in complexity theory. It is defined as:

In theoretical computer science, circuit complexity is a branch of computational complexity theory in which Boolean functions are classified according to the size or depth of the Boolean circuits that compute them. A related notion is the circuit complexity of a recursive language that is decided by a uniform family of circuits .
In computational complexity theory, the average-case complexity of an algorithm is the amount of some computational resource used by the algorithm, averaged over all possible inputs. It is frequently contrasted with worst-case complexity which considers the maximal complexity of the algorithm over all possible inputs.
Quantum complexity theory is the subfield of computational complexity theory that deals with complexity classes defined using quantum computers, a computational model based on quantum mechanics. It studies the hardness of computational problems in relation to these complexity classes, as well as the relationship between quantum complexity classes and classical complexity classes.
Generic-case complexity is a subfield of computational complexity theory that studies the complexity of computational problems on "most inputs".
In computational complexity theory, NP/poly is a complexity class, a non-uniform analogue of the class NP of problems solvable in polynomial time by a non-deterministic Turing machine. It is the non-deterministic complexity class corresponding to the deterministic class P/poly.












