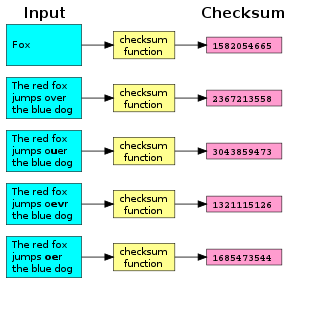
A checksum is a small-sized block of data derived from another block of digital data for the purpose of detecting errors that may have been introduced during its transmission or storage. By themselves, checksums are often used to verify data integrity but are not relied upon to verify data authenticity.

In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
A cyclic redundancy check (CRC) is an error-detecting code commonly used in digital networks and storage devices to detect accidental changes to digital data. Blocks of data entering these systems get a short check value attached, based on the remainder of a polynomial division of their contents. On retrieval, the calculation is repeated and, in the event the check values do not match, corrective action can be taken against data corruption. CRCs can be used for error correction.
In digital transmission, the number of bit errors is the number of received bits of a data stream over a communication channel that have been altered due to noise, interference, distortion or bit synchronization errors.
In computer science and telecommunication, Hamming codes are a family of linear error-correcting codes. Hamming codes can detect one-bit and two-bit errors, or correct one-bit errors without detection of uncorrected errors. By contrast, the simple parity code cannot correct errors, and can detect only an odd number of bits in error. Hamming codes are perfect codes, that is, they achieve the highest possible rate for codes with their block length and minimum distance of three. Richard W. Hamming invented Hamming codes in 1950 as a way of automatically correcting errors introduced by punched card readers. In his original paper, Hamming elaborated his general idea, but specifically focused on the Hamming(7,4) code which adds three parity bits to four bits of data.

In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different. In other words, it measures the minimum number of substitutions required to change one string into the other, or the minimum number of errors that could have transformed one string into the other. In a more general context, the Hamming distance is one of several string metrics for measuring the edit distance between two sequences. It is named after the American mathematician Richard Hamming.

A two-out-of-five code is a constant-weight code that provides exactly ten possible combinations of two bits, and is thus used for representing the decimal digits using five bits. Each bit is assigned a weight, such that the set bits sum to the desired value, with an exception for zero.
In mathematics and computing, Fibonacci coding is a universal code which encodes positive integers into binary code words. It is one example of representations of integers based on Fibonacci numbers. Each code word ends with "11" and contains no other instances of "11" before the end.
The reflected binary code (RBC), also known as reflected binary (RB) or Gray code after Frank Gray, is an ordering of the binary numeral system such that two successive values differ in only one bit.
In computing, a linear-feedback shift register (LFSR) is a shift register whose input bit is a linear function of its previous state.
A parity bit, or check bit, is a bit added to a string of binary code. Parity bits are a simple form of error detecting code. Parity bits are generally applied to the smallest units of a communication protocol, typically 8-bit octets (bytes), although they can also be applied separately to an entire message string of bits.
Two's complement is a mathematical operation to reversibly convert a positive binary number into a negative binary number with equivalent value, using the binary digit with the greatest place value to indicate whether the binary number is positive or negative. It is used in computer science as the most common method of representing signed integers on computers, and more generally, fixed point binary values. When the most significant bit is a one, the number is signed as negative. (see Converting from two's complement representation, below).

Aztec Code is a type of 2D barcode invented by Andrew Longacre, Jr. and Robert Hussey in 1995. The code was published by AIM, Inc. in 1997. Although the Aztec Code was patented, that patent was officially made public domain. The Aztec Code is also published as ISO/IEC 24778:2008 standard. Named after the resemblance of the central finder pattern to an Aztec pyramid, Aztec Code has the potential to use less space than other matrix barcodes because it does not require a surrounding blank "quiet zone".
Binary data is data whose unit can take on only two possible states. These are often labelled as 0 and 1 in accordance with the binary numeral system and Boolean algebra.
In coding theory, a linear code is an error-correcting code for which any linear combination of codewords is also a codeword. Linear codes are traditionally partitioned into block codes and convolutional codes, although turbo codes can be seen as a hybrid of these two types. Linear codes allow for more efficient encoding and decoding algorithms than other codes.
A pseudorandom binary sequence (PRBS), pseudorandom binary code or pseudorandom bitstream is a binary sequence that, while generated with a deterministic algorithm, is difficult to predict and exhibits statistical behavior similar to a truly random sequence. PRBS generators are used in telecommunication, such as in analog-to-information conversion, but also in encryption, simulation, correlation technique and time-of-flight spectroscopy. The most common example is the maximum length sequence generated by a (maximal) linear feedback shift register (LFSR). Other examples are Gold sequences, Kasami sequences and JPL sequences, all based on LFSRs.
In coding theory, a constant-weight code, also called an m-of-n code, is an error detection and correction code where all codewords share the same Hamming weight. The one-hot code and the balanced code are two widely used kinds of constant-weight code.
In coding theory, Hamming(7,4) is a linear error-correcting code that encodes four bits of data into seven bits by adding three parity bits. It is a member of a larger family of Hamming codes, but the term Hamming code often refers to this specific code that Richard W. Hamming introduced in 1950. At the time, Hamming worked at Bell Telephone Laboratories and was frustrated with the error-prone punched card reader, which is why he started working on error-correcting codes.
The cyclic redundancy check (CRC) is based on division in the ring of polynomials over the finite field GF(2), that is, the set of polynomials where each coefficient is either zero or one, and arithmetic operations wrap around.

Computation of a cyclic redundancy check is derived from the mathematics of polynomial division, modulo two. In practice, it resembles long division of the binary message string, with a fixed number of zeroes appended, by the "generator polynomial" string except that exclusive or operations replace subtractions. Division of this type is efficiently realised in hardware by a modified shift register, and in software by a series of equivalent algorithms, starting with simple code close to the mathematics and becoming faster through byte-wise parallelism and space–time tradeoffs.



