The Knowbot Information Service (KIS), also known as netaddress, is an Internet user search engine that debuted in December 1989. Although it searched users, not content, it could be argued to be the first search engine on the Internet as it queried more than a single network for information. It provided a uniform user interface to a variety of remote directory services such as whois, finger, X.500, and MCI Mail. By submitting a single query to KIS, a user can search a set of remote white pages services and see the results of the search in a uniform format. There are several interfaces to the KIS service including e-mail and telnet. Another KIS interface imitates the Berkeley whois command.
KIS consists of two distinct types of modules that interact with each other (typically across a network) to provide the service. One module is a user agent module that runs on the KIS mail host machine. The second module is a remote server module (possibly on a different machine) that interrogates various database services across the network and provides the results to the user agent module in a uniform fashion. Interactions between the two modules can be via messages between knowbots or by actual movement of knowbots.
In computing, Common Gateway Interface (CGI) is an interface specification that enables web servers to execute an external program, typically to process user requests.
The Domain Name System (DNS) is the hierarchical and decentralized naming system used to identify computers, services, and other resources reachable through the internet or other internet protocol networks. The resource records contained in the DNS associate domain names with other forms of information. These are most commonly used to map human-friendly domain names to the numerical IP addresses computers need to locate services and devices using the underlying network protocols, but have been extended over time to perform many other functions as well. The Domain Name System has been an essential component of the functionality of the Internet since 1985.
A web portal is a specially designed website that brings information from diverse sources, like emails, online forums and search engines, together in a uniform way. Usually, each information source gets its dedicated area on the page for displaying information ; often, the user can configure which ones to display. Variants of portals include mashups and intranet "dashboards" for executives and managers. The extent to which content is displayed in a "uniform way" may depend on the intended user and the intended purpose, as well as the diversity of the content. Very often design emphasis is on a certain "metaphor" for configuring and customizing the presentation of the content and the chosen implementation framework or code libraries. In addition, the role of the user in an organization may determine which content can be added to the portal or deleted from the portal configuration.
Kis or KIS may refer to:
An application layer is an abstraction layer that specifies the shared communications protocols and interface methods used by hosts in a communications network. An application layer abstraction is specified in both the Internet Protocol Suite (TCP/IP) and the OSI model. Although both models use the same term for their respective highest-level layer, the detailed definitions and purposes are different.
WebDAV is a set of extensions to the Hypertext Transfer Protocol (HTTP), which allows user agents to collaboratively author contents directly in an HTTP web server by providing facilities for concurrency control and namespace operations, thus allowing Web to be viewed as a writeable, collaborative medium and not just a read-only medium. WebDAV is defined in RFC 4918 by a working group of the Internet Engineering Task Force (IETF).
The deep web, invisible web, or hidden web are parts of the World Wide Web whose contents are not indexed by standard web search-engines. This is in contrast to the "surface web", which is accessible to anyone using the Internet. Computer-scientist Michael K. Bergman is credited with coining the term in 2001 as a search-indexing term.
A metasearch engine is an online information retrieval tool that uses the data of a web search engine to produce its own results. Metasearch engines take input from a user and immediately query search engines for results. Sufficient data is gathered, ranked, and presented to the users.
The Entrez Global Query Cross-Database Search System is a federated search engine, or web portal that allows users to search many discrete health sciences databases at the National Center for Biotechnology Information (NCBI) website. The NCBI is a part of the National Library of Medicine (NLM), which is itself a department of the National Institutes of Health (NIH), which in turn is a part of the United States Department of Health and Human Services. The name "Entrez" was chosen to reflect the spirit of welcoming the public to search the content available from the NLM.
Representational state transfer (REST) is a software architectural style that was created to guide the design and development of the architecture for the World Wide Web. REST defines a set of constraints for how the architecture of an Internet-scale distributed hypermedia system, such as the Web, should behave. The REST architectural style emphasises the scalability of interactions between components, uniform interfaces, independent deployment of components, and the creation of a layered architecture to facilitate caching components to reduce user-perceived latency, enforce security, and encapsulate legacy systems.
Federated search retrieves information from a variety of sources via a search application built on top of one or more search engines. A user makes a single query request which is distributed to the search engines, databases or other query engines participating in the federation. The federated search then aggregates the results that are received from the search engines for presentation to the user. Federated search can be used to integrate disparate information resources within a single large organization ("enterprise") or for the entire web.
A search engine is a software system that is designed to carry out web searches. They search the World Wide Web in a systematic way for particular information specified in a textual web search query. The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs) The information may be a mix of links to web pages, images, videos, infographics, articles, research papers, and other types of files. Some search engines also mine data available in databases or open directories. Unlike web directories, which are maintained only by human editors, search engines also maintain real-time information by running an algorithm on a web crawler. Internet content that is not capable of being searched by a web search engine is generally described as the deep web.
WHOIS is a query and response protocol that is widely used for querying databases that store the registered users or assignees of an Internet resource, such as a domain name, an IP address block or an autonomous system, but is also used for a wider range of other information. The protocol stores and delivers database content in a human-readable format. The current iteration of the WHOIS protocol was drafted by the Internet Society, and is documented in RFC 3912.
The EB-eye, also known as EBI Search, is a search engine that provides uniform access to the biological data resources hosted at the European Bioinformatics Institute (EBI).
A search appliance (SA) is a type of computer appliance which is attached to a corporate network for the purpose of indexing the content shared across that network in a way that is similar to a web search engine.
In computer science, the Semantic Desktop is a collective term for ideas related to changing a computer's user interface and data handling capabilities so that data are more easily shared between different applications or tasks and so that data that once could not be automatically processed by a computer could be. It also encompasses some ideas about being able to share information automatically between different people. This concept is very much related to the Semantic Web, but is distinct insofar as its main concern is the personal use of information.
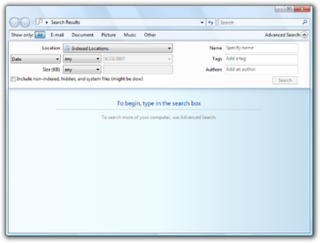
Windows Search is a content index desktop search platform by Microsoft introduced in Windows Vista as a replacement for both the previous Indexing Service of Windows 2000 and the optional MSN Desktop Search for Windows XP and Windows Server 2003, designed to facilitate local and remote queries for files and non-file items in compatible applications including Windows Explorer. It was developed after the postponement of WinFS and introduced to Windows constituents originally touted as benefits of that platform.
Natural-language user interface is a type of computer human interface where linguistic phenomena such as verbs, phrases and clauses act as UI controls for creating, selecting and modifying data in software applications.
Shinken is an open source computer system and network monitoring software application compatible with Nagios. It watches hosts and services, gathers performance data and alerts users when error conditions occur and again when the conditions clear.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.