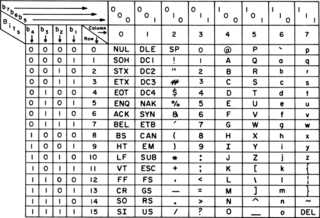
ASCII, abbreviated from American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text in computers, telecommunications equipment, and other devices. Because of technical limitations of computer systems at the time it was invented, ASCII has just 128 code points, of which only 95 are printable characters, which severely limited its scope. Modern computer systems have evolved to use Unicode, which has millions of code points, but the first 128 of these are the same as the ASCII set.
The byte is a unit of digital information that most commonly consists of eight bits. Historically, the byte was the number of bits used to encode a single character of text in a computer and for this reason it is the smallest addressable unit of memory in many computer architectures. To disambiguate arbitrarily sized bytes from the common 8-bit definition, network protocol documents such as the Internet Protocol refer to an 8-bit byte as an octet. Those bits in an octet are usually counted with numbering from 0 to 7 or 7 to 0 depending on the bit endianness.

In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.

In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding or using such a code is Huffman coding, an algorithm developed by David A. Huffman while he was a Sc.D. student at MIT, and published in the 1952 paper "A Method for the Construction of Minimum-Redundancy Codes".
In telecommunication, a convolutional code is a type of error-correcting code that generates parity symbols via the sliding application of a boolean polynomial function to a data stream. The sliding application represents the 'convolution' of the encoder over the data, which gives rise to the term 'convolutional coding'. The sliding nature of the convolutional codes facilitates trellis decoding using a time-invariant trellis. Time invariant trellis decoding allows convolutional codes to be maximum-likelihood soft-decision decoded with reasonable complexity.
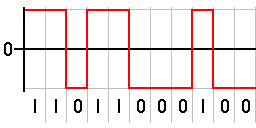
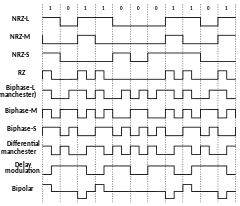
In telecommunication, a line code is a pattern of voltage, current, or photons used to represent digital data transmitted down a communication channel or written to a storage medium. This repertoire of signals is usually called a constrained code in data storage systems. Some signals are more prone to error than others as the physics of the communication channel or storage medium constrains the repertoire of signals that can be used reliably.

bzip2 is a free and open-source file compression program that uses the Burrows–Wheeler algorithm. It only compresses single files and is not a file archiver. It relies on separate external utilities for tasks such as handling multiple files, encryption, and archive-splitting.

In computer and machine-based telecommunications terminology, a character is a unit of information that roughly corresponds to a grapheme, grapheme-like unit, or symbol, such as in an alphabet or syllabary in the written form of a natural language.
Lempel–Ziv–Welch (LZW) is a universal lossless data compression algorithm created by Abraham Lempel, Jacob Ziv, and Terry Welch. It was published by Welch in 1984 as an improved implementation of the LZ78 algorithm published by Lempel and Ziv in 1978. The algorithm is simple to implement and has the potential for very high throughput in hardware implementations. It is the algorithm of the Unix file compression utility compress and is used in the GIF image format.
In computer programming, Base64 is a group of tetrasexagesimal binary-to-text encoding schemes that represent binary data in sequences of 24 bits that can be represented by four 6-bit Base64 digits.
Run-length limited or RLL coding is a line coding technique that is used to send arbitrary data over a communications channel with bandwidth limits. RLL codes are defined by four main parameters: m, n, d, k. The first two, m/n, refer to the rate of the code, while the remaining two specify the minimal d and maximal k number of zeroes between consecutive ones. This is used in both telecommunication and storage systems that move a medium past a fixed recording head.
In information theory, turbo codes are a class of high-performance forward error correction (FEC) codes developed around 1990–91, but first published in 1993. They were the first practical codes to closely approach the maximum channel capacity or Shannon limit, a theoretical maximum for the code rate at which reliable communication is still possible given a specific noise level. Turbo codes are used in 3G/4G mobile communications and in satellite communications as well as other applications where designers seek to achieve reliable information transfer over bandwidth- or latency-constrained communication links in the presence of data-corrupting noise. Turbo codes compete with low-density parity-check (LDPC) codes, which provide similar performance.
In telecommunications, 8b/10b is a line code that maps 8-bit words to 10-bit symbols to achieve DC balance and bounded disparity, and at the same time provide enough state changes to allow reasonable clock recovery. This means that the difference between the counts of ones and zeros in a string of at least 20 bits is no more than two, and that there are not more than five ones or zeros in a row. This helps to reduce the demand for the lower bandwidth limit of the channel necessary to transfer the signal.
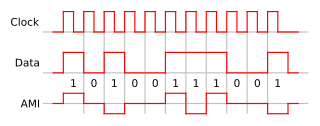
In telecommunication, bipolar encoding is a type of return-to-zero (RZ) line code, where two nonzero values are used, so that the three values are +, −, and zero. Such a signal is called a duobinary signal. Standard bipolar encodings are designed to be DC-balanced, spending equal amounts of time in the + and − states.
In telecommunication, 4B5B is a form of data communications line code. 4B5B maps groups of 4 bits of data onto groups of 5 bits for transmission. These 5-bit words are pre-determined in a dictionary and they are chosen to ensure that there will be sufficient transitions in the line state to produce a self-clocking signal. A collateral effect of the code is that 25% more bits are needed to send the same information.
4B3T, which stands for 4 (four) binary 3 (three) ternary, is a line encoding scheme used for ISDN PRI interface. 4B3T represents four binary bits using three pulses.

IEEE Standard 1355-1995, IEC 14575, or ISO 14575 is a data communications standard for Heterogeneous Interconnect (HIC).
A Serializer/Deserializer (SerDes) is a pair of functional blocks commonly used in high speed communications to compensate for limited input/output. These blocks convert data between serial data and parallel interfaces in each direction. The term "SerDes" generically refers to interfaces used in various technologies and applications. The primary use of a SerDes is to provide data transmission over a single line or a differential pair in order to minimize the number of I/O pins and interconnects.
In coding theory, a constant-weight code, also called an m-of-n code, is an error detection and correction code where all codewords share the same Hamming weight. The one-hot code and the balanced code are two widely used kinds of constant-weight code.
In data networking and transmission, 64b/66b is a line code that transforms 64-bit data to 66-bit line code to provide enough state changes to allow reasonable clock recovery and alignment of the data stream at the receiver. It was defined by the IEEE 802.3 working group as part of the IEEE 802.3ae-2002 amendment which introduced 10 Gbit/s Ethernet. At the time 64b/66b was deployed, it allowed 10 Gb Ethernet to be transmitted with the same lasers used by SONET OC-192, rather than requiring the 12.5 Gbit/s lasers that were not expected to be available for several years.