Related Research Articles

Ambiguity is the type of meaning in which a phrase, statement, or resolution is not explicitly defined, making for several interpretations; others describe it as a concept or statement that has no real reference. A common aspect of ambiguity is uncertainty. It is thus an attribute of any idea or statement whose intended meaning cannot be definitively resolved, according to a rule or process with a finite number of steps..

Cyc is a long-term artificial intelligence project that aims to assemble a comprehensive ontology and knowledge base that spans the basic concepts and rules about how the world works. Hoping to capture common sense knowledge, Cyc focuses on implicit knowledge. The project began in July 1984 at MCC and was developed later by the Cycorp company.

ISO 8601 is an international standard covering the worldwide exchange and communication of date and time-related data. It is maintained by the International Organization for Standardization (ISO) and was first published in 1988, with updates in 1991, 2000, 2004, and 2019, and an amendment in 2022. The standard provides a well-defined, unambiguous method of representing calendar dates and times in worldwide communications, especially to avoid misinterpreting numeric dates and times when such data is transferred between countries with different conventions for writing numeric dates and times.
Natural language processing (NLP) is an interdisciplinary subfield of computer science and artificial intelligence. It is primarily concerned with providing computers with the ability to process data encoded in natural language and is thus closely related to information retrieval, knowledge representation and computational linguistics, a subfield of linguistics. Typically data is collected in text corpora, using either rule-based, statistical or neural-based approaches in machine learning and deep learning.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
In linguistics and philosophy, a vague predicate is one which gives rise to borderline cases. For example, the English adjective "tall" is vague since it is not clearly true or false for someone of middling height. By contrast, the word "prime" is not vague since every number is definitively either prime or not. Vagueness is commonly diagnosed by a predicate's ability to give rise to the Sorites paradox. Vagueness is separate from ambiguity, in which an expression has multiple denotations. For instance the word "bank" is ambiguous since it can refer either to a river bank or to a financial institution, but there are no borderline cases between both interpretations.
Fuzzy logic is a form of many-valued logic in which the truth value of variables may be any real number between 0 and 1. It is employed to handle the concept of partial truth, where the truth value may range between completely true and completely false. By contrast, in Boolean logic, the truth values of variables may only be the integer values 0 or 1.
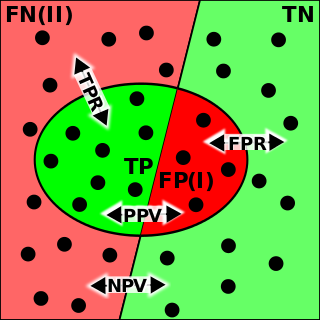
Binary classification is the task of classifying the elements of a set into one of two groups. Typical binary classification problems include:

A radical, or indexing component, is a visually prominent component of a Chinese character under which the character is traditionally listed in a Chinese dictionary. The radical for a character is typically a semantic component, but can also be another structural component or even an artificially extracted portion of the character. In some cases the original semantic or phonological connection has become obscure, owing to changes in the meaning or pronunciation of the character over time.
Question answering (QA) is a computer science discipline within the fields of information retrieval and natural language processing (NLP) that is concerned with building systems that automatically answer questions that are posed by humans in a natural language.
Document retrieval is defined as the matching of some stated user query against a set of free-text records. These records could be any type of mainly unstructured text, such as newspaper articles, real estate records or paragraphs in a manual. User queries can range from multi-sentence full descriptions of an information need to a few words.

James Alexander Hendler is an artificial intelligence researcher at Rensselaer Polytechnic Institute, United States, and one of the originators of the Semantic Web. He is a Fellow of the National Academy of Public Administration.
Geographic information retrieval (GIR) or geographical information retrieval systems are search tools for searching the Web, enterprise documents, and mobile local search that combine traditional text-based queries with location querying, such as a map or placenames. Like traditional information retrieval systems, GIR systems index text and information from structured and unstructured documents, and also augment those indices with geographic information. The development and engineering of GIR systems aims to build systems that can reliably answer queries that include a geographic dimension, such as "What wars were fought in Greece?" or "restaurants in Beirut". Semantic similarity and word-sense disambiguation are important components of GIR. To identify place names, GIR systems often rely on natural language processing or other metadata to associate text documents with locations. Such georeferencing, geotagging, and geoparsing tools often need databases of location names, known as gazetteers.
Data preprocessing can refer to manipulation, filtration or augmentation of data before it is analyzed, and is often an important step in the data mining process. Data collection methods are often loosely controlled, resulting in out-of-range values, impossible data combinations, and missing values, amongst other issues.

In pattern recognition, information retrieval, object detection and classification, precision and recall are performance metrics that apply to data retrieved from a collection, corpus or sample space.
Epistemicism is a position about vagueness in the philosophy of language or metaphysics, according to which there are facts about the boundaries of a vague predicate which we cannot possibly discover. Given a vague predicate, such as 'is thin' or 'is bald', epistemicists hold that there is some sharp cutoff, dividing cases where a person, for example, is thin from those in which they are not. As a result, a statement such as "Saul is thin" is either true or false. The statement does not, as other theories of vagueness might claim, lack a truth-value – even if the determinate truth-value is beyond our epistemological grasp. Epistemicism gets its name because it holds that there is no semantic indeterminacy present in vague terms, only epistemic uncertainty.
A concept search is an automated information retrieval method that is used to search electronically stored unstructured text for information that is conceptually similar to the information provided in a search query. In other words, the ideas expressed in the information retrieved in response to a concept search query are relevant to the ideas contained in the text of the query.
In mathematics and computer science, computer algebra, also called symbolic computation or algebraic computation, is a scientific area that refers to the study and development of algorithms and software for manipulating mathematical expressions and other mathematical objects. Although computer algebra could be considered a subfield of scientific computing, they are generally considered as distinct fields because scientific computing is usually based on numerical computation with approximate floating point numbers, while symbolic computation emphasizes exact computation with expressions containing variables that have no given value and are manipulated as symbols.
Semantic Scholar is a research tool for scientific literature powered by artificial intelligence. It is developed at the Allen Institute for AI and was publicly released in November 2015. Semantic Scholar uses modern techniques in natural language processing to support the research process, for example by providing automatically generated summaries of scholarly papers. The Semantic Scholar team is actively researching the use of artificial intelligence in natural language processing, machine learning, human–computer interaction, and information retrieval.
The syntax of the SQL programming language is defined and maintained by ISO/IEC SC 32 as part of ISO/IEC 9075. This standard is not freely available. Despite the existence of the standard, SQL code is not completely portable among different database systems without adjustments.
References
- Smith, N. J. J. (2008). "Worldly Vagueness and Semantic Indeterminacy". Vagueness and Degrees of Truth. pp. 277–316. doi:10.1093/acprof:oso/9780199233007.003.0007. ISBN 9780199233007.
| | This applied mathematics-related article is a stub. You can help Wikipedia by expanding it. |
| | This statistics-related article is a stub. You can help Wikipedia by expanding it. |