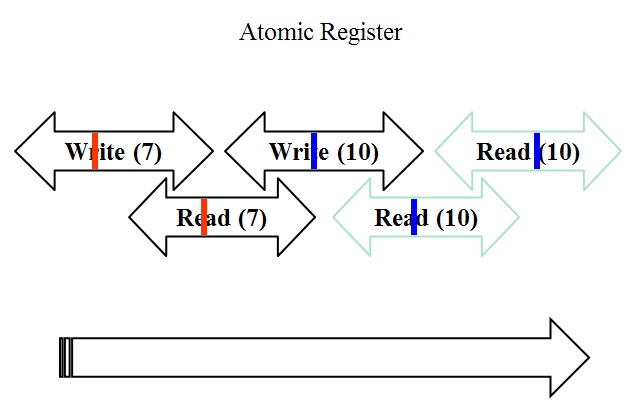
Regular semantics is a computing term which describes one type of guarantee provided by a data register shared by several processors in a parallel machine or in a network of computers working together. Regular semantics are defined for a variable with a single writer but multiple readers. These semantics are stronger than safe semantics but weaker than atomic semantics: they guarantee that there is a total order to the write operations which is consistent with real-time and that read operations return either the value of the last write completed before the read begins, or that of one of the writes which are concurrent with the read.
Safe semantics is a computer hardware consistency model. It describes one type of guarantee that a data register provides when it is shared by several processors in a parallel computer or in a network of computers working together.
In computer science, mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions. It is the requirement that one thread of execution never enters a critical section while a concurrent thread of execution is already accessing said critical section, which refers to an interval of time during which a thread of execution accesses a shared resource or shared memory.
In computer science, ACID is a set of properties of database transactions intended to guarantee data validity despite errors, power failures, and other mishaps. In the context of databases, a sequence of database operations that satisfies the ACID properties is called a transaction. For example, a transfer of funds from one bank account to another, even involving multiple changes such as debiting one account and crediting another, is a single transaction.
In information technology and computer science, especially in the fields of computer programming, operating systems, multiprocessors, and databases, concurrency control ensures that correct results for concurrent operations are generated, while getting those results as quickly as possible.
In computer science, a consistency model specifies a contract between the programmer and a system, wherein the system guarantees that if the programmer follows the rules for operations on memory, memory will be consistent and the results of reading, writing, or updating memory will be predictable. Consistency models are used in distributed systems like distributed shared memory systems or distributed data stores. Consistency is different from coherence, which occurs in systems that are cached or cache-less, and is consistency of data with respect to all processors. Coherence deals with maintaining a global order in which writes to a single location or single variable are seen by all processors. Consistency deals with the ordering of operations to multiple locations with respect to all processors.
In computer science, read-copy-update (RCU) is a synchronization mechanism that avoids the use of lock primitives while multiple threads concurrently read and update elements that are linked through pointers and that belong to shared data structures.
In the fields of databases and transaction processing, a schedule of a system is an abstract model to describe execution of transactions running in the system. Often it is a list of operations (actions) ordered by time, performed by a set of transactions that are executed together in the system. If the order in time between certain operations is not determined by the system, then a partial order is used. Examples of such operations are requesting a read operation, reading, writing, aborting, committing, requesting a lock, locking, etc. Not all transaction operation types should be included in a schedule, and typically only selected operation types are included, as needed to reason about and describe certain phenomena. Schedules and schedule properties are fundamental concepts in database concurrency control theory.
In computer science, compare-and-swap (CAS) is an atomic instruction used in multithreading to achieve synchronization. It compares the contents of a memory location with a given value and, only if they are the same, modifies the contents of that memory location to a new given value. This is done as a single atomic operation. The atomicity guarantees that the new value is calculated based on up-to-date information; if the value had been updated by another thread in the meantime, the write would fail. The result of the operation must indicate whether it performed the substitution; this can be done either with a simple boolean response, or by returning the value read from the memory location.

In concurrent programming, an operation is linearizable if it consists of an ordered list of invocation and response events, that may be extended by adding response events such that:
- The extended list can be re-expressed as a sequential history.
- That sequential history is a subset of the original unextended list.
In computer science, software transactional memory (STM) is a concurrency control mechanism analogous to database transactions for controlling access to shared memory in concurrent computing. It is an alternative to lock-based synchronization. STM is a strategy implemented in software, rather than as a hardware component. A transaction in this context occurs when a piece of code executes a series of reads and writes to shared memory. These reads and writes logically occur at a single instant in time; intermediate states are not visible to other (successful) transactions. The idea of providing hardware support for transactions originated in a 1986 paper by Tom Knight. The idea was popularized by Maurice Herlihy and J. Eliot B. Moss. In 1995, Nir Shavit and Dan Touitou extended this idea to software-only transactional memory (STM). Since 2005, STM has been the focus of intense research and support for practical implementations is growing.
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. Eventual consistency, also called optimistic replication, is widely deployed in distributed systems and has origins in early mobile computing projects. A system that has achieved eventual consistency is often said to have converged, or achieved replica convergence. Eventual consistency is a weak guarantee – most stronger models, like linearizability, are trivially eventually consistent.
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
In computer science, a readers–writer is a synchronization primitive that solves one of the readers–writers problems. An RW lock allows concurrent access for read-only operations, whereas write operations require exclusive access. This means that multiple threads can read the data in parallel but an exclusive lock is needed for writing or modifying data. When a writer is writing the data, all other writers and readers will be blocked until the writer is finished writing. A common use might be to control access to a data structure in memory that cannot be updated atomically and is invalid until the update is complete.
In computer science, read–modify–write is a class of atomic operations that both read a memory location and write a new value into it simultaneously, either with a completely new value or some function of the previous value. These operations prevent race conditions in multi-threaded applications. Typically they are used to implement mutexes or semaphores. These atomic operations are also heavily used in non-blocking synchronization.
The Java programming language and the Java virtual machine (JVM) is designed to support concurrent programming. All execution takes place in the context of threads. Objects and resources can be accessed by many separate threads. Each thread has its own path of execution, but can potentially access any object in the program. The programmer must ensure read and write access to objects is properly coordinated between threads. Thread synchronization ensures that objects are modified by only one thread at a time and prevents threads from accessing partially updated objects during modification by another thread. The Java language has built-in constructs to support this coordination.
A concurrent hash-trie or Ctrie is a concurrent thread-safe lock-free implementation of a hash array mapped trie. It is used to implement the concurrent map abstraction. It has particularly scalable concurrent insert and remove operations and is memory-efficient. It is the first known concurrent data-structure that supports O(1), atomic, lock-free snapshots.
In distributed computing, a shared snapshot object is a type of data structure, which is shared between several threads or processes. For many tasks, it is important to have a data structure, that can provide a consistent view of the state of the memory. In practice, it turns out that it is not possible to get such a consistent state of the memory by just accessing one shared register after another, since the values stored in individual registers can be changed at any time during this process. To solve this problem, snapshot objects store a vector of n components and provide the following two atomic operations: update(i,v) changes the value in the ith component to v, and scan returns the values stored in all n components. Snapshot objects can be constructed using atomic single-writer multi-reader shared registers.
In distributed computing, shared-memory systems and message-passing systems are two means of interprocess communication which have been heavily studied. In shared-memory systems, processes communicate by accessing shared data structures. A shared (read/write) register, sometimes just called a register, is a fundamental type of shared data structure which stores a value and has two operations: read, which returns the value stored in the register, and write, which updates the value stored. Other types of shared data structures include read–modify–write, test-and-set, compare-and-swap etc. The memory location which is concurrently accessed is sometimes called a register.