In mathematics, the determinant is a scalar value that is a function of the entries of a square matrix. It characterizes some properties of the matrix and the linear map represented by the matrix. In particular, the determinant is nonzero if and only if the matrix is invertible and the linear map represented by the matrix is an isomorphism. The determinant of a product of matrices is the product of their determinants (the preceding property is a corollary of this one). The determinant of a matrix A is denoted det(A), det A, or |A|.
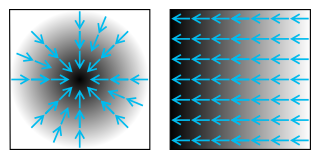
In vector calculus, the gradient of a scalar-valued differentiable function of several variables is the vector field whose value at a point is the "direction and rate of fastest increase". If the gradient of a function is non-zero at a point , the direction of the gradient is the direction in which the function increases most quickly from , and the magnitude of the gradient is the rate of increase in that direction, the greatest absolute directional derivative. Further, a point where the gradient is the zero vector is known as a stationary point. The gradient thus plays a fundamental role in optimization theory, where it is used to maximize a function by gradient ascent. In coordinate-free terms, the gradient of a function may be defined by:
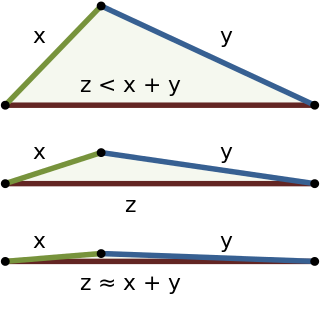
In mathematics, the triangle inequality states that for any triangle, the sum of the lengths of any two sides must be greater than or equal to the length of the remaining side. This statement permits the inclusion of degenerate triangles, but some authors, especially those writing about elementary geometry, will exclude this possibility, thus leaving out the possibility of equality. If x, y, and z are the lengths of the sides of the triangle, with no side being greater than z, then the triangle inequality states that

In mathematics, the complex conjugate of a complex number is the number with an equal real part and an imaginary part equal in magnitude but opposite in sign. That is, if and are real numbers then the complex conjugate of is The complex conjugate of is often denoted as or .

In mathematics, a quadratic polynomial is a polynomial of degree two in one or more variables. A quadratic function is the polynomial function defined by a quadratic polynomial. Before the 20th century, the distinction was unclear between a polynomial and its associated polynomial function; so "quadratic polynomial" and "quadratic function" were almost synonymous. This is still the case in many elementary courses, where both terms are often abbreviated as "quadratic".
In linear algebra, the adjugate or classical adjoint of a square matrix A is the transpose of its cofactor matrix and is denoted by adj(A). It is also occasionally known as adjunct matrix, or "adjoint", though the latter term today normally refers to a different concept, the adjoint operator which for a matrix is the conjugate transpose.
In mathematics, and in particular linear algebra, the Moore–Penrose inverse of a matrix is the most widely known generalization of the inverse matrix. It was independently described by E. H. Moore in 1920, Arne Bjerhammar in 1951, and Roger Penrose in 1955. Earlier, Erik Ivar Fredholm had introduced the concept of a pseudoinverse of integral operators in 1903. When referring to a matrix, the term pseudoinverse, without further specification, is often used to indicate the Moore–Penrose inverse. The term generalized inverse is sometimes used as a synonym for pseudoinverse.
In mathematics, a monomial is, roughly speaking, a polynomial which has only one term. Two definitions of a monomial may be encountered:
- A monomial, also called power product, is a product of powers of variables with nonnegative integer exponents, or, in other words, a product of variables, possibly with repetitions. For example, is a monomial. The constant is a monomial, being equal to the empty product and to for any variable . If only a single variable is considered, this means that a monomial is either or a power of , with a positive integer. If several variables are considered, say, then each can be given an exponent, so that any monomial is of the form with non-negative integers.
- A monomial is a monomial in the first sense multiplied by a nonzero constant, called the coefficient of the monomial. A monomial in the first sense is a special case of a monomial in the second sense, where the coefficient is . For example, in this interpretation and are monomials.
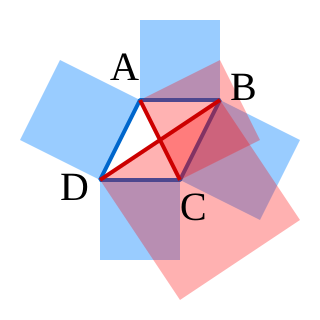
In mathematics, the simplest form of the parallelogram law belongs to elementary geometry. It states that the sum of the squares of the lengths of the four sides of a parallelogram equals the sum of the squares of the lengths of the two diagonals. We use these notations for the sides: AB, BC, CD, DA. But since in Euclidean geometry a parallelogram necessarily has opposite sides equal, that is, AB = CD and BC = DA, the law can be stated as
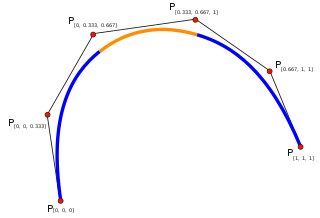
In mathematics, a spline is a special function defined piecewise by polynomials. In interpolating problems, spline interpolation is often preferred to polynomial interpolation because it yields similar results, even when using low degree polynomials, while avoiding Runge's phenomenon for higher degrees.
In mathematics, the lexicographic or lexicographical order is a generalization of the alphabetical order of the dictionaries to sequences of ordered symbols or, more generally, of elements of a totally ordered set.
In computer science, the Boyer–Moore string-search algorithm is an efficient string-searching algorithm that is the standard benchmark for practical string-search literature. It was developed by Robert S. Boyer and J Strother Moore in 1977. The original paper contained static tables for computing the pattern shifts without an explanation of how to produce them. The algorithm for producing the tables was published in a follow-on paper; this paper contained errors which were later corrected by Wojciech Rytter in 1980.

In geometry, Euler's rotation theorem states that, in three-dimensional space, any displacement of a rigid body such that a point on the rigid body remains fixed, is equivalent to a single rotation about some axis that runs through the fixed point. It also means that the composition of two rotations is also a rotation. Therefore the set of rotations has a group structure, known as a rotation group.
In linear algebra, a circulant matrix is a square matrix in which all row vectors are composed of the same elements and each row vector is rotated one element to the right relative to the preceding row vector. It is a particular kind of Toeplitz matrix.
In group theory, a word metric on a discrete group is a way to measure distance between any two elements of . As the name suggests, the word metric is a metric on , assigning to any two elements , of a distance that measures how efficiently their difference can be expressed as a word whose letters come from a generating set for the group. The word metric on G is very closely related to the Cayley graph of G: the word metric measures the length of the shortest path in the Cayley graph between two elements of G.
A maximum length sequence (MLS) is a type of pseudorandom binary sequence.
Many letters of the Latin alphabet, both capital and small, are used in mathematics, science, and engineering to denote by convention specific or abstracted constants, variables of a certain type, units, multipliers, or physical entities. Certain letters, when combined with special formatting, take on special meaning.
In computer science, a longest common substring of two or more strings is a longest string that is a substring of all of them. There may be more than one longest common substring. Applications include data deduplication and plagiarism detection.
In numerical analysis, the Weierstrass method or Durand–Kerner method, discovered by Karl Weierstrass in 1891 and rediscovered independently by Durand in 1960 and Kerner in 1966, is a root-finding algorithm for solving polynomial equations. In other words, the method can be used to solve numerically the equation
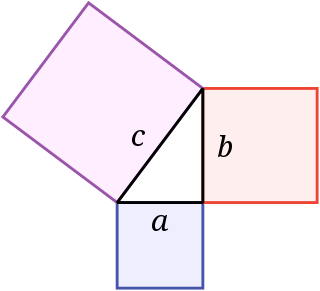
In mathematics, the Pythagorean theorem or Pythagoras' theorem is a fundamental relation in Euclidean geometry between the three sides of a right triangle. It states that the area of the square whose side is the hypotenuse is equal to the sum of the areas of the squares on the other two sides.














































