In computer science, an array data structure, or simply an array, is a data structure consisting of a collection of elements, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called one-dimensional array.

In computing, a hash table is a data structure that implements an associative array abstract data type, a structure that can map keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains: data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that access time is linear. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.

In computer science, a trie, also called digital tree or prefix tree, is a type of search tree, a tree data structure used for locating specific keys from within a set. These keys are most often strings, with links between nodes defined not by the entire key, but by individual characters. In order to access a key, the trie is traversed depth-first, following the links between nodes, which represent each character in the key.
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type composed of a collection of pairs, such that each possible key appears at most once in the collection. Not to be confused with Associative Processors

A quadtree is a tree data structure in which each internal node has exactly four children. Quadtrees are the two-dimensional analog of octrees and are most often used to partition a two-dimensional space by recursively subdividing it into four quadrants or regions. The data associated with a leaf cell varies by application, but the leaf cell represents a "unit of interesting spatial information".
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. False positive matches are possible, but false negatives are not – in other words, a query returns either "possibly in set" or "definitely not in set". Elements can be added to the set, but not removed ; the more items added, the larger the probability of false positives.
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjans' 1986 article.

R-trees are tree data structures used for spatial access methods, i.e., for indexing multi-dimensional information such as geographical coordinates, rectangles or polygons. The R-tree was proposed by Antonin Guttman in 1984 and has found significant use in both theoretical and applied contexts. A common real-world usage for an R-tree might be to store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc. and then find answers quickly to queries such as "Find all museums within 2 km of my current location", "retrieve all road segments within 2 km of my location" or "find the nearest gas station". The R-tree can also accelerate nearest neighbor search for various distance metrics, including great-circle distance.
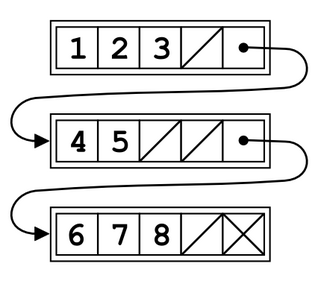
In computer programming, an unrolled linked list is a variation on the linked list which stores multiple elements in each node. It can dramatically increase cache performance, while decreasing the memory overhead associated with storing list metadata such as references. It is related to the B-tree.
A van Emde Boas tree, also known as a vEB tree or van Emde Boas priority queue, is a tree data structure which implements an associative array with m-bit integer keys. It performs all operations in O(log m) time, or equivalently in O(log log M) time, where M = 2m is the maximum number of elements that can be stored in the tree. The M is not to be confused with the actual number of elements stored in the tree, by which the performance of other tree data-structures is often measured. The vEB tree has good space efficiency when it contains many elements. It was invented by a team led by Dutch computer scientist Peter van Emde Boas in 1975.

In computer science, a dynamic array, growable array, resizable array, dynamic table, mutable array, or array list is a random access, variable-size list data structure that allows elements to be added or removed. It is supplied with standard libraries in many modern mainstream programming languages. Dynamic arrays overcome a limit of static arrays, which have a fixed capacity that needs to be specified at allocation.
In computer science, an interval tree is a tree data structure to hold intervals. Specifically, it allows one to efficiently find all intervals that overlap with any given interval or point. It is often used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene. A similar data structure is the segment tree.

Cuckoo hashing is a scheme in computer programming for resolving hash collisions of values of hash functions in a table, with worst-case constant lookup time. The name derives from the behavior of some species of cuckoo, where the cuckoo chick pushes the other eggs or young out of the nest when it hatches; analogously, inserting a new key into a cuckoo hashing table may push an older key to a different location in the table.
In computer science, fractional cascading is a technique to speed up a sequence of binary searches for the same value in a sequence of related data structures. The first binary search in the sequence takes a logarithmic amount of time, as is standard for binary searches, but successive searches in the sequence are faster. The original version of fractional cascading, introduced in two papers by Chazelle and Guibas in 1986, combined the idea of cascading, originating in range searching data structures of Lueker (1978) and Willard (1978), with the idea of fractional sampling, which originated in Chazelle (1983). Later authors introduced more complex forms of fractional cascading that allow the data structure to be maintained as the data changes by a sequence of discrete insertion and deletion events.
In computer science, a search data structure is any data structure that allows the efficient retrieval of specific items from a set of items, such as a specific record from a database.
Skip graphs are a kind of distributed data structure based on skip lists. They were invented in 2003 by James Aspnes and Gauri Shah. A nearly identical data structure called SkipNet was independently invented by Nicholas Harvey, Michael Jones, Stefan Saroiu, Marvin Theimer and Alec Wolman, also in 2003.
In computer science, an x-fast trie is a data structure for storing integers from a bounded domain. It supports exact and predecessor or successor queries in time O(log log M), using O(n log M) space, where n is the number of stored values and M is the maximum value in the domain. The structure was proposed by Dan Willard in 1982, along with the more complicated y-fast trie, as a way to improve the space usage of van Emde Boas trees, while retaining the O(log log M) query time.
A concurrent hash-trie or Ctrie is a concurrent thread-safe lock-free implementation of a hash array mapped trie. It is used to implement the concurrent map abstraction. It has particularly scalable concurrent insert and remove operations and is memory-efficient. It is the first known concurrent data-structure that supports O(1), atomic, lock-free snapshots.

A quotient filter is a space-efficient probabilistic data structure used to test whether an element is a member of a set. A query will elicit a reply specifying either that the element is definitely not in the set or that the element is probably in the set. The former result is definitive; i.e., the test does not generate false negatives. But with the latter result there is some probability, ε, of the test returning "element is in the set" when in fact the element is not present in the set. There is a tradeoff between ε, the false positive rate, and storage size; increasing the filter's storage size reduces ε. Other AMQ operations include "insert" and "optionally delete". The more elements are added to the set, the larger the probability of false positives.

