This article's factual accuracy may be compromised due to out-of-date information. Please help update this article to reflect recent events or newly available information.(March 2017)
In computer architecture, a branch target predictor is the part of a processor that predicts the target, i.e., the address of the instruction that is executed next, of a taken conditional branch or unconditional branch instruction before the target of the branch instruction is computed by the execution unit of the processor.
Branch target prediction is not the same as branch prediction, which guesses whether a conditional branch will be taken or not-taken in a binary manner.
In more parallel processor designs, as the instruction cache latency grows longer and the fetch width grows wider, branch target extraction becomes a bottleneck. The recurrence is:
Instruction cache fetches block of instructions
Instructions in block are scanned to identify branches
In machines where this recurrence takes two cycles, the machine loses one full cycle of fetch after every predicted taken branch. As predicted branches happen every 10 instructions or so, this can force a substantial drop in fetch bandwidth. Some machines with longer instruction cache latencies would have an even larger loss. To ameliorate the loss, some machines implement branch target prediction: given the address of a branch, they predict the target of that branch. A refinement of the idea predicts the start of a sequential run of instructions given the address of the start of the previous sequential run of instructions.
This predictor reduces the recurrence above to:
Hash the address of the first instruction in a run
Fetch the prediction for the addresses of the targets of branches in that run of instructions
Select the address corresponding to the branch predicted taken
As the predictor RAM can be 5–10% of the size of the instruction cache, the fetch happens much faster than the instruction cache fetch, and so this recurrence is much faster. If it were not fast enough, it could be parallelized, by predicting target addresses of target branches.
An optimizing compiler is a compiler designed to generate code that is optimized in aspects such as minimizing program execution time, memory use, storage size, and power consumption. Optimization is generally implemented as a sequence of optimizing transformations, algorithms that transform code to produce semantically equivalent code optimized for some aspect. It is typically CPU and memory intensive. In practice, factors such as available memory and a programmer's willingness to wait for compilation limit the optimizations that a compiler might provide. Research indicates that some optimization problems are NP-complete, or even undecidable.
In computer science, an instruction set architecture (ISA) is an abstract model that generally defines how software controls the CPU in a computer or a family of computers. A device or program that executes instructions described by that ISA, such as a central processing unit (CPU), is called an implementation of that ISA.
The program counter (PC), commonly called the instruction pointer (IP) in Intel x86 and Itanium microprocessors, and sometimes called the instruction address register (IAR), the instruction counter, or just part of the instruction sequencer, is a processor register that indicates where a computer is in its program sequence.
In computer science, locality of reference, also known as the principle of locality, is the tendency of a processor to access the same set of memory locations repetitively over a short period of time. There are two basic types of reference locality – temporal and spatial locality. Temporal locality refers to the reuse of specific data and/or resources within a relatively small time duration. Spatial locality refers to the use of data elements within relatively close storage locations. Sequential locality, a special case of spatial locality, occurs when data elements are arranged and accessed linearly, such as traversing the elements in a one-dimensional array.
In computer architecture, predication is a feature that provides an alternative to conditional transfer of control, as implemented by conditional branch machine instructions. Predication works by having conditional (predicated) non-branch instructions associated with a predicate, a Boolean value used by the instruction to control whether the instruction is allowed to modify the architectural state or not. If the predicate specified in the instruction is true, the instruction modifies the architectural state; otherwise, the architectural state is unchanged. For example, a predicated move instruction will only modify the destination if the predicate is true. Thus, instead of using a conditional branch to select an instruction or a sequence of instructions to execute based on the predicate that controls whether the branch occurs, the instructions to be executed are associated with that predicate, so that they will be executed, or not executed, based on whether that predicate is true or false.
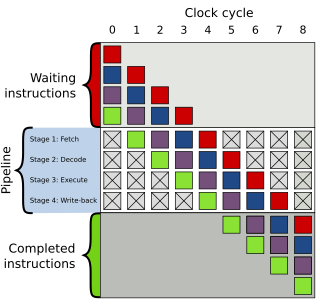
In computer engineering, instruction pipelining is a technique for implementing instruction-level parallelism within a single processor. Pipelining attempts to keep every part of the processor busy with some instruction by dividing incoming instructions into a series of sequential steps performed by different processor units with different parts of instructions processed in parallel.
Instruction-level parallelism (ILP) is the parallel or simultaneous execution of a sequence of instructions in a computer program. More specifically ILP refers to the average number of instructions run per step of this parallel execution.
Speculative execution is an optimization technique where a computer system performs some task that may not be needed. Work is done before it is known whether it is actually needed, so as to prevent a delay that would have to be incurred by doing the work after it is known that it is needed. If it turns out the work was not needed after all, most changes made by the work are reverted and the results are ignored.
In the history of computer hardware, some early reduced instruction set computer central processing units used a very similar architectural solution, now called a classic RISC pipeline. Those CPUs were: MIPS, SPARC, Motorola 88000, and later the notional CPU DLX invented for education.
In computer architecture, a branch predictor is a digital circuit that tries to guess which way a branch will go before this is known definitively. The purpose of the branch predictor is to improve the flow in the instruction pipeline. Branch predictors play a critical role in achieving high performance in many modern pipelined microprocessor architectures.
In computer science, computer engineering and programming language implementations, a stack machine is a computer processor or a virtual machine in which the primary interaction is moving short-lived temporary values to and from a push down stack. In the case of a hardware processor, a hardware stack is used. The use of a stack significantly reduces the required number of processor registers. Stack machines extend push-down automata with additional load/store operations or multiple stacks and hence are Turing-complete.
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost to access data from the main memory. A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels, with different instruction-specific and data-specific caches at level 1. The cache memory is typically implemented with static random-access memory (SRAM), in modern CPUs by far the largest part of them by chip area, but SRAM is not always used for all levels, or even any level, sometimes some latter or all levels are implemented with eDRAM.
A branch, jump or transfer is an instruction in a computer program that can cause a computer to begin executing a different instruction sequence and thus deviate from its default behavior of executing instructions in order. Branch may also refer to the act of switching execution to a different instruction sequence as a result of executing a branch instruction. Branch instructions are used to implement control flow in program loops and conditionals.
In electronics, computer science and computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as μarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.
Hardware acceleration is the use of computer hardware designed to perform specific functions more efficiently when compared to software running on a general-purpose central processing unit (CPU). Any transformation of data that can be calculated in software running on a generic CPU can also be calculated in custom-made hardware, or in some mix of both.
The instruction unit, also called, e.g., instruction fetch unit (IFU), instruction issue unit (IIU), instruction sequencing unit (ISU), in a central processing unit (CPU) is responsible for organizing program instructions to be fetched from memory, and executed, in an appropriate order, and for forwarding them to an execution unit. The I-unit may also do, e.g., address resolution, pre-fetching, prior to forwarding an instruction. It is a part of the control unit, which in turn is part of the CPU.
Runahead is a technique that allows a computer processor to speculatively pre-process instructions during cache miss cycles. The pre-processed instructions are used to generate instruction and data stream prefetches by executing instructions leading to cache misses before they would normally occur, effectively hiding memory latency. In runahead, the processor uses the idle execution resources to calculate instruction and data stream addresses using the available information that is independent of a cache miss. Once the processor has resolved the initial cache miss, all runahead results are discarded, and the processor resumes execution as normal. The primary use case of the technique is to mitigate the effects of the memory wall. The technique may also be used for other purposes, such as pre-computing branch outcomes to achieve highly accurate branch prediction.
The PA-8000 (PCX-U), code-named Onyx, is a microprocessor developed and fabricated by Hewlett-Packard (HP) that implemented the PA-RISC 2.0 instruction set architecture (ISA). It was a completely new design with no circuitry derived from previous PA-RISC microprocessors. The PA-8000 was introduced on 2 November 1995 when shipments began to members of the Precision RISC Organization (PRO). It was used exclusively by PRO members and was not sold on the merchant market. All follow-on PA-8x00 processors are based on the basic PA-8000 processor core.
Latency oriented processor architecture is the microarchitecture of a microprocessor designed to serve a serial computing thread with a low latency. This is typical of most central processing units (CPU) being developed since the 1970s. These architectures, in general, aim to execute as many instructions as possible belonging to a single serial thread, in a given window of time; however, the time to execute a single instruction completely from fetch to retire stages may vary from a few cycles to even a few hundred cycles in some cases. Latency oriented processor architectures are the opposite of throughput-oriented processors which concern themselves more with the total throughput of the system, rather than the service latencies for all individual threads that they work on.
In computer architecture, a trace cache or execution trace cache is a specialized instruction cache which stores the dynamic stream of instructions known as trace. It helps in increasing the instruction fetch bandwidth and decreasing power consumption by storing traces of instructions that have already been fetched and decoded. A trace processor is an architecture designed around the trace cache and processes the instructions at trace level granularity. The formal mathematical theory of traces is described by trace monoids.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.