Implicit combinatorial models
Simple combinatorial problems are the ones that can be solved by applying just one combinatorial operation (variations, permutations, combinations, …). These problems can be classified into three different models, called implicit combinatorial models.
Selection
A selection problem requires to choose a sample of k elements out of a set of n elements. It is needed to know if the order in which the objects are selected matters and whether an object can be selected more than once or not. This table shows the operations that the model provides to get the number of different samples for each of the selections:
| Repetition not allowed | Repetition allowed |
|---|
| Ordered sample |  |  |
|---|
| Non ordered sample |  |  |
|---|
Examples
1.- At a party there are 50 people. Everybody shakes everybody’s hand once. How often are hands shaken in total? What we need to do is calculate the number of all possible pairs of party guests, which means, a sample of 2 people out of the 50 guests, so  and
and  . A pair will be the same no matter the order of the two people. A handshake must be carried out by two different people (no repetition). So, it is required to select an ordered sample of 2 elements out of a set of 50 elements, in which repetition is not allowed. That is all we need to know to choose the right operation, and the result is:
. A pair will be the same no matter the order of the two people. A handshake must be carried out by two different people (no repetition). So, it is required to select an ordered sample of 2 elements out of a set of 50 elements, in which repetition is not allowed. That is all we need to know to choose the right operation, and the result is:

2.- Unfortunately, you can’t remember the code for your four-digit lock. You only know that you didn’t use any digit more than once. How many different ways do you have to try? We need to choose a sample of 4 digits out of the set of 10 digits (base 10), so  and
and  . The digits must be ordered in a certain way to get the correct number, so we want to select an ordered sample. As the statement says, no digit was chosen more than once, so our sample will not have repeated digits. So, it is required to select an ordered sample of 4 elements out of a set of 10 elements, in which repetition is not allowed. That is all we need to know to choose the right operation, and the result is:
. The digits must be ordered in a certain way to get the correct number, so we want to select an ordered sample. As the statement says, no digit was chosen more than once, so our sample will not have repeated digits. So, it is required to select an ordered sample of 4 elements out of a set of 10 elements, in which repetition is not allowed. That is all we need to know to choose the right operation, and the result is:

3.- A boy wants to buy 20 invitation cards to give to their friends for his birthday party. There are 3 types of cards in the store, and he likes them all. In how many ways can he buy the 20 cards? It is required to choose a sample of 20 invitation cards out of the set of 3 types of cards, so  and
and  . The order in which you choose the different types of invitations does not matter. As a type of card must be selected more than once, there will be repetitions in our invitation cards. So, we want to select a non ordered sample of 20 elements () out of a set of 3 elements (), in which repetition is allowed. That is all we need to know to choose the right operation, and the result is:
. The order in which you choose the different types of invitations does not matter. As a type of card must be selected more than once, there will be repetitions in our invitation cards. So, we want to select a non ordered sample of 20 elements () out of a set of 3 elements (), in which repetition is allowed. That is all we need to know to choose the right operation, and the result is:

Distribution
In a distribution problem it is required to place k objects into n boxes or recipients. In order to choose the right operation out of the ones that the model provides, it is necessary to know:
- Whether the objects are distinguishable or not.
- Whether the boxes are distinguishable or not.
- If the order in which the objects are placed in a box matters.
- The conditions that the distribution must meet. Depending on this, the distribution can be:
- Injective distribution: every box must have at most 1 object (
 )
) - Surjective distribution: every box must have at least 1 object (
 )
) - Bijective distribution: every box must exactly 1 object (
 )
) - Distribution with no restrictions
The following table shows the operations that the model provides to get the number of different ways of distributing the objects for each of the distributions:
Distribution of k objects into n boxes | Non ordered distribution | Ordered distribution |
|---|
| Distinguishable objects | Indistinguishable objects | Distinguishable objects |
|---|
| Distinguishable boxes | Indistinguishable boxes | Distinguishable boxes | Indistinguishable boxes | Distinguishable boxes | Indistinguishable boxes |
|---|
| Any distribution | |  | |  |  |  |
|---|
| Injective distribution | |  | | | | |
|---|
| Surjective distribution |  |  |  |  |  |  |
|---|
| Bijective distribution |  | | | | | |
|---|
 Stirling numbers of the second kind
Stirling numbers of the second kind
 Number of partitions of the integer k into n parts
Number of partitions of the integer k into n parts
 Lah numbers (Stirling numbers of the third kind)
Lah numbers (Stirling numbers of the third kind)
Examples
1.- A maths teacher has to give 3 studentships among his students. 7 of them got an 'outstanding' grade, so they are the candidates to get them. In how many ways can he distribute the grants? Let's consider the 3 studentships are objects that have to be distributed into 7 boxes, which are the students. As the objects are identical studentships, they are indistinguishable. The boxes are distinguishable, as they are different students. Every studentship must be given to a different student, so every box must have at most 1 object. Furthermore, the order in which the objects are placed in a boxes does not matter, because there cannot be more than one on each box. So, it is a non ordered injective distribution of 3 indistinguishable objects ( ) into 7 distinguishable boxes (
) into 7 distinguishable boxes ( ). That is all we need to know to choose the right operation, and the result is:
). That is all we need to know to choose the right operation, and the result is:

2.- A group of 8 friends rent a 5-room cottage to spend their holidays. If the rooms are identical and no one can be empty, in how many ways can they be distributed in the cottage? Let's consider the friends are objects that have to be distributed into 5 boxes, which are the rooms. As the objects are different people, they are distinguishable. The boxes are indistinguishable, as they are identical rooms. We can consider it as a non ordered distribution, because the ordered in which everyone is placed in the rooms does not matter. No room can be empty, so every box must have at least 1 object. So, it is a non ordered surjective distribution of 8 distinguishable objects ( ) into 5 indistinguishable boxes (
) into 5 indistinguishable boxes ( ). That is all we need to know to choose the right operation, and the result is:
). That is all we need to know to choose the right operation, and the result is:

3.- 12 people are done shopping in a supermarket where 4 cashiers are working at the moment. In how many different ways can they be distributed into the checkouts? Let's consider the people are objects that have to be distributed into boxes, which are the check-outs. As the people and the checkouts are different, the objects and the boxes are distinguishable. The order in which the objects are placed in the boxes matter, because they are people getting into queues. The statement does not mention any restriction. So, it is an ordered distribution with no restrictions of 12 distinguishable objects ( ) into 4 distinguishable boxes (
) into 4 distinguishable boxes ( ). That is all we need to know to choose the right operation, and the result is:
). That is all we need to know to choose the right operation, and the result is:

Partition
A partition problem requires to divide a set of k elements into n subsets. This model is related to the distribution one, as we can consider the objects inside every box as subsets of the set of objects to distribute. So, each of the 24 distributions described previously has a matching kind of partition into subsets. So, a partition problem can be solved by transforming it into a distribution one and applying the correspondent operation provided by the distribution model (previous table). Following this method, we will get the number of possible ways of dividing the set. The relation between these two models is described in the following table:
| Distribution | Partition |
|---|
| Ordered | Subsets of ordered elements |
| Non ordered | Subsets of non ordered elements |
| Distinguishable objects | Distinguishable elements |
| Indistinguishable objects | Indistinguishable elements |
| Distinguishable boxes | Ordered partitions |
| Indistinguishable boxes | Non ordered partitions |
| Injective distribution | Subsets of 1 element or empty ones |
| Surjective distribution | No empty subsets |
| Bijective distribution | Subsets of exactly 1 element |
| No restrictions | Subsets of 1 or more elements or empty ones |
This relation let us transform the table provided by the distribution model into a new one that can be used to know the different ways of dividing a set of k elements into n subsets:
Partition of a set of k elements into n subsets | Non ordered elements | , |
|---|
| Distinguishable elements | Indistinguishable elements | Distinguishable elements |
|---|
| Ordered subsets | Non ordered subsets | Ordered subsets | Non ordered subsets | Ordered subsets | Non ordered subsets |
|---|
| Any subsets | | | | | | |
|---|
| Empty or 1-element subsets | | | | | | |
|---|
| No empty subsets | | | | | |  |
|---|
| Subsets of 1 element | | | | | | |
|---|

In mathematics, the binomial coefficients are the positive integers that occur as coefficients in the binomial theorem. Commonly, a binomial coefficient is indexed by a pair of integers n ≥ k ≥ 0 and is written It is the coefficient of the xk term in the polynomial expansion of the binomial power (1 + x)n, and is given by the formula
In mathematics, a combination is a selection of items from a collection, such that the order of selection does not matter. For example, given three fruits, say an apple, an orange and a pear, there are three combinations of two that can be drawn from this set: an apple and a pear; an apple and an orange; or a pear and an orange. More formally, a k-combination of a set S is a subset of k distinct elements of S. If the set has n elements, the number of k-combinations is equal to the binomial coefficient
In combinatorial mathematics, a Steiner system is a type of block design, specifically a t-design with λ = 1 and t ≥ 2.
In probability theory, a probability space or a probability triple is a mathematical construct that provides a formal model of a random process or "experiment". For example, one can define a probability space which models the throwing of a dice.

In mathematics, a permutation of a set is, loosely speaking, an arrangement of its members into a sequence or linear order, or if the set is already ordered, a rearrangement of its elements. The word "permutation" also refers to the act or process of changing the linear order of an ordered set.

In mathematics, the pigeonhole principle states that if items are put into containers, with , then at least one container must contain more than one item. For example, if one has three gloves, then one must have at least two right-hand gloves, or at least two left-hand gloves, because one has three objects, but only two categories of handedness to put them into. This seemingly obvious statement, a type of counting argument, can be used to demonstrate possibly unexpected results. For example, given that the population of London is greater than the maximum number of hairs that can be present on a human's head, then the pigeonhole principle requires that there must be at least two people in London who have the same number of hairs on their heads.
In statistics, the kth order statistic of a statistical sample is equal to its kth-smallest value. Together with rank statistics, order statistics are among the most fundamental tools in non-parametric statistics and inference.
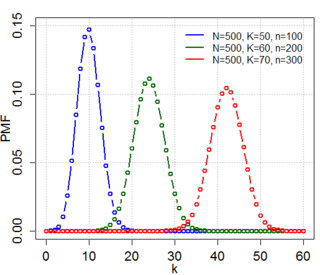
In probability theory and statistics, the hypergeometric distribution is a discrete probability distribution that describes the probability of successes in draws, without replacement, from a finite population of size that contains exactly objects with that feature, wherein each draw is either a success or a failure. In contrast, the binomial distribution describes the probability of successes in draws with replacement.
In mathematics, a multiset is a modification of the concept of a set that, unlike a set, allows for multiple instances for each of its elements. The number of instances given for each element is called the multiplicity of that element in the multiset. As a consequence, an infinite number of multisets exist which contain only elements a and b, but vary in the multiplicities of their elements:
An F-test is any statistical test in which the test statistic has an F-distribution under the null hypothesis. It is most often used when comparing statistical models that have been fitted to a data set, in order to identify the model that best fits the population from which the data were sampled. Exact "F-tests" mainly arise when the models have been fitted to the data using least squares. The name was coined by George W. Snedecor, in honour of Sir Ronald A. Fisher. Fisher initially developed the statistic as the variance ratio in the 1920s.

In combinatorics, a branch of mathematics, the inclusion–exclusion principle is a counting technique which generalizes the familiar method of obtaining the number of elements in the union of two finite sets; symbolically expressed as
In mathematics, the term combinatorial proof is often used to mean either of two types of mathematical proof:
Sperner's theorem, in discrete mathematics, describes the largest possible families of finite sets none of which contain any other sets in the family. It is one of the central results in extremal set theory. It is named after Emanuel Sperner, who published it in 1928.
In combinatorics, the symbolic method is a technique for counting combinatorial objects. It uses the internal structure of the objects to derive formulas for their generating functions. The method is mostly associated with Philippe Flajolet and is detailed in Part A of his book with Robert Sedgewick, Analytic Combinatorics, while the rest of the book explains how to use complex analysis in order to get asymptotic and probabilistic results on the corresponding generating functions.
In mathematics, and in particular in combinatorics, the combinatorial number system of degree k, also referred to as combinadics, is a correspondence between natural numbers N and k-combinations, represented as strictly decreasing sequences ck > ... > c2 > c1 ≥ 0. Since the latter are strings of numbers, one can view this as a kind of numeral system for representing N, although the main utility is representing a k-combination by N rather than the other way around. Distinct numbers correspond to distinct k-combinations, and produce them in lexicographic order; moreover the numbers less than correspond to all k-combinations of { 0, 1, ..., n − 1}. The correspondence does not depend on the size n of the set that the k-combinations are taken from, so it can be interpreted as a map from N to the k-combinations taken from N; in this view the correspondence is a bijection.

In mathematics, particularly in combinatorics, a Stirling number of the second kind is the number of ways to partition a set of n objects into k non-empty subsets and is denoted by or . Stirling numbers of the second kind occur in the field of mathematics called combinatorics and the study of partitions.
In combinatorics, the twelvefold way is a systematic classification of 12 related enumerative problems concerning two finite sets, which include the classical problems of counting permutations, combinations, multisets, and partitions either of a set or of a number. The idea of the classification is credited to Gian-Carlo Rota, and the name was suggested by Joel Spencer.
Enumerative combinatorics is an area of combinatorics that deals with the number of ways that certain patterns can be formed. Two examples of this type of problem are counting combinations and counting permutations. More generally, given an infinite collection of finite sets Si indexed by the natural numbers, enumerative combinatorics seeks to describe a counting function which counts the number of objects in Sn for each n. Although counting the number of elements in a set is a rather broad mathematical problem, many of the problems that arise in applications have a relatively simple combinatorial description. The twelvefold way provides a unified framework for counting permutations, combinations and partitions.
In the context of combinatorial mathematics, stars and bars is a graphical aid for deriving certain combinatorial theorems. It was popularized by William Feller in his classic book on probability. It can be used to solve many simple counting problems, such as how many ways there are to put n indistinguishable balls into k distinguishable bins.
In statistics, a simple random sample is a subset of individuals chosen from a larger set in which each individual is chosen randomly and entirely by chance. More specifically, each individual has the same probability of being chosen at any stage during the sampling process, and each subset of k individuals has the same probability of being chosen for the sample as any other subset of k individuals. This process and technique is known as simple random sampling, and should not be confused with systematic random sampling. A simple random sample is an unbiased surveying technique.




