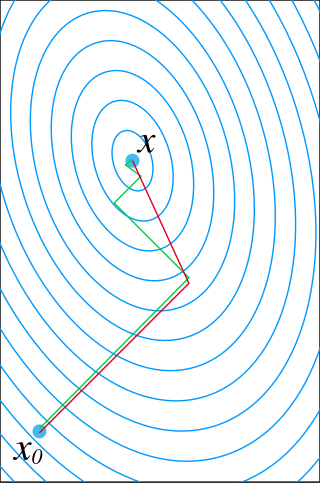
Gradient descent is a method for unconstrained mathematical optimization. It is a first-order iterative algorithm for finding a local minimum of a differentiable multivariate function.
In the calculus of variations, a field of mathematical analysis, the functional derivative relates a change in a functional to a change in a function on which the functional depends.

In thermodynamics, the Onsager reciprocal relations express the equality of certain ratios between flows and forces in thermodynamic systems out of equilibrium, but where a notion of local equilibrium exists.
In Bayesian probability theory, if the posterior distribution is in the same probability distribution family as the prior probability distribution , the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood function .
In mathematics and computing, the Levenberg–Marquardt algorithm, also known as the damped least-squares (DLS) method, is used to solve non-linear least squares problems. These minimization problems arise especially in least squares curve fitting. The LMA interpolates between the Gauss–Newton algorithm (GNA) and the method of gradient descent. The LMA is more robust than the GNA, which means that in many cases it finds a solution even if it starts very far off the final minimum. For well-behaved functions and reasonable starting parameters, the LMA tends to be slower than the GNA. LMA can also be viewed as Gauss–Newton using a trust region approach.

The Gauss–Newton algorithm is used to solve non-linear least squares problems, which is equivalent to minimizing a sum of squared function values. It is an extension of Newton's method for finding a minimum of a non-linear function. Since a sum of squares must be nonnegative, the algorithm can be viewed as using Newton's method to iteratively approximate zeroes of the components of the sum, and thus minimizing the sum. In this sense, the algorithm is also an effective method for solving overdetermined systems of equations. It has the advantage that second derivatives, which can be challenging to compute, are not required.
In mathematics, the conjugate gradient method is an algorithm for the numerical solution of particular systems of linear equations, namely those whose matrix is positive-definite. The conjugate gradient method is often implemented as an iterative algorithm, applicable to sparse systems that are too large to be handled by a direct implementation or other direct methods such as the Cholesky decomposition. Large sparse systems often arise when numerically solving partial differential equations or optimization problems.
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the input dataset and the output of the (linear) function of the independent variable.
In numerical analysis, the Crank–Nicolson method is a finite difference method used for numerically solving the heat equation and similar partial differential equations. It is a second-order method in time. It is implicit in time, can be written as an implicit Runge–Kutta method, and it is numerically stable. The method was developed by John Crank and Phyllis Nicolson in the mid 20th century.
In numerical optimization, the Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm is an iterative method for solving unconstrained nonlinear optimization problems. Like the related Davidon–Fletcher–Powell method, BFGS determines the descent direction by preconditioning the gradient with curvature information. It does so by gradually improving an approximation to the Hessian matrix of the loss function, obtained only from gradient evaluations via a generalized secant method.
In mathematics, more specifically in numerical linear algebra, the biconjugate gradient method is an algorithm to solve systems of linear equations
In mathematics, preconditioning is the application of a transformation, called the preconditioner, that conditions a given problem into a form that is more suitable for numerical solving methods. Preconditioning is typically related to reducing a condition number of the problem. The preconditioned problem is then usually solved by an iterative method.

In probability theory and statistics, the beta-binomial distribution is a family of discrete probability distributions on a finite support of non-negative integers arising when the probability of success in each of a fixed or known number of Bernoulli trials is either unknown or random. The beta-binomial distribution is the binomial distribution in which the probability of success at each of n trials is not fixed but randomly drawn from a beta distribution. It is frequently used in Bayesian statistics, empirical Bayes methods and classical statistics to capture overdispersion in binomial type distributed data.
In many-body theory, the term Green's function is sometimes used interchangeably with correlation function, but refers specifically to correlators of field operators or creation and annihilation operators.
In numerical optimization, the nonlinear conjugate gradient method generalizes the conjugate gradient method to nonlinear optimization. For a quadratic function
Non-linear least squares is the form of least squares analysis used to fit a set of m observations with a model that is non-linear in n unknown parameters (m ≥ n). It is used in some forms of nonlinear regression. The basis of the method is to approximate the model by a linear one and to refine the parameters by successive iterations. There are many similarities to linear least squares, but also some significant differences. In economic theory, the non-linear least squares method is applied in (i) the probit regression, (ii) threshold regression, (iii) smooth regression, (iv) logistic link regression, (v) Box–Cox transformed regressors ().
The purpose of this page is to provide supplementary materials for the ordinary least squares article, reducing the load of the main article with mathematics and improving its accessibility, while at the same time retaining the completeness of exposition.
In numerical linear algebra, the conjugate gradient method is an iterative method for numerically solving the linear system

The Minimal Residual Method or MINRES is a Krylov subspace method for the iterative solution of symmetric linear equation systems. It was proposed by mathematicians Christopher Conway Paige and Michael Alan Saunders in 1975.
In numerical linear algebra, the conjugate gradient squared method (CGS) is an iterative algorithm for solving systems of linear equations of the form , particularly in cases where computing the transpose is impractical. The CGS method was developed as an improvement to the biconjugate gradient method.








