
The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution, Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The Cauchy distribution is the distribution of the x-intercept of a ray issuing from with a uniformly distributed angle. It is also the distribution of the ratio of two independent normally distributed random variables with mean zero.

In probability theory and statistics, variance is the expected value of the squared deviation from the mean of a random variable. The standard deviation (SD) is obtained as the square root of the variance. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. It is the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .

In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

In probability theory and statistics, the chi-squared distribution with degrees of freedom is the distribution of a sum of the squares of independent standard normal random variables. The chi-squared distribution is a special case of the gamma distribution and is one of the most widely used probability distributions in inferential statistics, notably in hypothesis testing and in construction of confidence intervals. This distribution is sometimes called the central chi-squared distribution, a special case of the more general noncentral chi-squared distribution.

In probability theory, the law of large numbers (LLN) is a mathematical theorem that states that the average of the results obtained from a large number of independent and identical random samples converges to the true value, if it exists. More formally, the LLN states that given a sample of independent and identically distributed values, the sample mean converges to the true mean.
Pearson's chi-squared test or Pearson's test is a statistical test applied to sets of categorical data to evaluate how likely it is that any observed difference between the sets arose by chance. It is the most widely used of many chi-squared tests – statistical procedures whose results are evaluated by reference to the chi-squared distribution. Its properties were first investigated by Karl Pearson in 1900. In contexts where it is important to improve a distinction between the test statistic and its distribution, names similar to Pearson χ-squared test or statistic are used.

A chi-squared test is a statistical hypothesis test used in the analysis of contingency tables when the sample sizes are large. In simpler terms, this test is primarily used to examine whether two categorical variables are independent in influencing the test statistic. The test is valid when the test statistic is chi-squared distributed under the null hypothesis, specifically Pearson's chi-squared test and variants thereof. Pearson's chi-squared test is used to determine whether there is a statistically significant difference between the expected frequencies and the observed frequencies in one or more categories of a contingency table. For contingency tables with smaller sample sizes, a Fisher's exact test is used instead.

In statistics, Spearman's rank correlation coefficient or Spearman's ρ, named after Charles Spearman and often denoted by the Greek letter (rho) or as , is a nonparametric measure of rank correlation. It assesses how well the relationship between two variables can be described using a monotonic function.
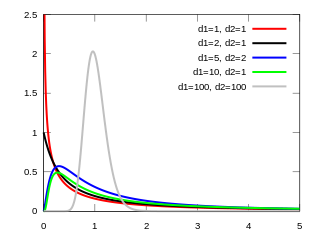
In probability theory and statistics, the F-distribution or F-ratio, also known as Snedecor's F distribution or the Fisher–Snedecor distribution, is a continuous probability distribution that arises frequently as the null distribution of a test statistic, most notably in the analysis of variance (ANOVA) and other F-tests.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. Sometimes loosely referred to as "the" exponential family, this class of distributions is distinct because they all possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In statistics, G-tests are likelihood-ratio or maximum likelihood statistical significance tests that are increasingly being used in situations where chi-squared tests were previously recommended.
In statistics, the score test assesses constraints on statistical parameters based on the gradient of the likelihood function—known as the score—evaluated at the hypothesized parameter value under the null hypothesis. Intuitively, if the restricted estimator is near the maximum of the likelihood function, the score should not differ from zero by more than sampling error. While the finite sample distributions of score tests are generally unknown, they have an asymptotic χ2-distribution under the null hypothesis as first proved by C. R. Rao in 1948, a fact that can be used to determine statistical significance.
In statistics, the Wald test assesses constraints on statistical parameters based on the weighted distance between the unrestricted estimate and its hypothesized value under the null hypothesis, where the weight is the precision of the estimate. Intuitively, the larger this weighted distance, the less likely it is that the constraint is true. While the finite sample distributions of Wald tests are generally unknown, it has an asymptotic χ2-distribution under the null hypothesis, a fact that can be used to determine statistical significance.
In econometrics and statistics, the generalized method of moments (GMM) is a generic method for estimating parameters in statistical models. Usually it is applied in the context of semiparametric models, where the parameter of interest is finite-dimensional, whereas the full shape of the data's distribution function may not be known, and therefore maximum likelihood estimation is not applicable.
In statistics, Bartlett's test, named after Maurice Stevenson Bartlett, is used to test homoscedasticity, that is, if multiple samples are from populations with equal variances. Some statistical tests, such as the analysis of variance, assume that variances are equal across groups or samples, which can be verified with Bartlett's test.
In statistics, the number of degrees of freedom is the number of values in the final calculation of a statistic that are free to vary.

In statistics, Fisher's method, also known as Fisher's combined probability test, is a technique for data fusion or "meta-analysis" (analysis of analyses). It was developed by and named for Ronald Fisher. In its basic form, it is used to combine the results from several independence tests bearing upon the same overall hypothesis (H0).

The Nakagami distribution or the Nakagami-m distribution is a probability distribution related to the gamma distribution. It is used to model physical phenomena, such as those found in medical ultrasound imaging, communications engineering, meteorology, hydrology, multimedia, and seismology.
In statistics, the multinomial test is the test of the null hypothesis that the parameters of a multinomial distribution equal specified values; it is used for categorical data.
In statistics Wilks' theorem states that the log-likelihood ratio is asymptotically normal. This can be used to produce confidence intervals for maximum-likelihood estimates or as a test statistic for performing the likelihood-ratio test.










