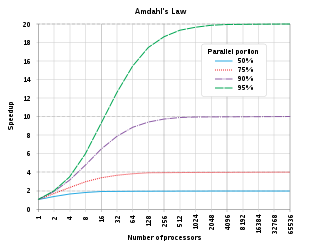
In computer architecture, Amdahl's law is a formula which gives the theoretical speedup in latency of the execution of a task at fixed workload that can be expected of a system whose resources are improved. It states that "the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used". It is named after computer scientist Gene Amdahl, and was presented at the American Federation of Information Processing Societies (AFIPS) Spring Joint Computer Conference in 1967.

In information theory, the entropy of a random variable is the average level of "information", "surprise", or "uncertainty" inherent to the variable's possible outcomes. Given a discrete random variable , which takes values in the alphabet and is distributed according to :

Queueing theory is the mathematical study of waiting lines, or queues. A queueing model is constructed so that queue lengths and waiting time can be predicted. Queueing theory is generally considered a branch of operations research because the results are often used when making business decisions about the resources needed to provide a service.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.

VMEbus is a computer bus standard physically based on Eurocard sizes.
Flynn's taxonomy is a classification of computer architectures, proposed by Michael J. Flynn in 1966 and extended in 1972. The classification system has stuck, and it has been used as a tool in the design of modern processors and their functionalities. Since the rise of multiprocessing central processing units (CPUs), a multiprogramming context has evolved as an extension of the classification system. Vector processing, covered by Duncan's taxonomy, is missing from Flynn's work because the Cray-1 was released in 1977: Flynn's second paper was published in 1972.

The CDC Cyber range of mainframe-class supercomputers were the primary products of Control Data Corporation (CDC) during the 1970s and 1980s. In their day, they were the computer architecture of choice for scientific and mathematically intensive computing. They were used for modeling fluid flow, material science stress analysis, electrochemical machining analysis, probabilistic analysis, energy and academic computing, radiation shielding modeling, and other applications. The lineup also included the Cyber 18 and Cyber 1000 minicomputers. Like their predecessor, the CDC 6600, they were unusual in using the ones' complement binary representation.
In computer science, a parallel random-access machine is a shared-memory abstract machine. As its name indicates, the PRAM is intended as the parallel-computing analogy to the random-access machine (RAM). In the same way that the RAM is used by sequential-algorithm designers to model algorithmic performance, the PRAM is used by parallel-algorithm designers to model parallel algorithmic performance. Similar to the way in which the RAM model neglects practical issues, such as access time to cache memory versus main memory, the PRAM model neglects such issues as synchronization and communication, but provides any (problem-size-dependent) number of processors. Algorithm cost, for instance, is estimated using two parameters O(time) and O(time × processor_number).
In mathematical statistics, the Kullback–Leibler divergence, denoted , is a type of statistical distance: a measure of how one probability distribution P is different from a second, reference probability distribution Q. A simple interpretation of the KL divergence of P from Q is the expected excess surprise from using Q as a model when the actual distribution is P. While it is a measure of how different two distributions are, and in some sense is thus a "distance", it is not actually a metric, which is the most familiar and formal type of distance. In particular, it is not symmetric in the two distributions, and does not satisfy the triangle inequality. Instead, in terms of information geometry, it is a type of divergence, a generalization of squared distance, and for certain classes of distributions, it satisfies a generalized Pythagorean theorem.
In computing, a parallel programming model is an abstraction of parallel computer architecture, with which it is convenient to express algorithms and their composition in programs. The value of a programming model can be judged on its generality: how well a range of different problems can be expressed for a variety of different architectures, and its performance: how efficiently the compiled programs can execute. The implementation of a parallel programming model can take the form of a library invoked from a sequential language, as an extension to an existing language, or as an entirely new language.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.

In computer architecture, Gustafson's law gives the speedup in the execution time of a task that theoretically gains from parallel computing, using a hypothetical run of the task on a single-core machine as the baseline. To put it another way, it is the theoretical "slowdown" of an already parallelized task if running on a serial machine. It is named after computer scientist John L. Gustafson and his colleague Edwin H. Barsis, and was presented in the article Reevaluating Amdahl's Law in 1988.
A binary multiplier is an electronic circuit used in digital electronics, such as a computer, to multiply two binary numbers.
The Karp–Flatt metric is a measure of parallelization of code in parallel processor systems. This metric exists in addition to Amdahl's law and Gustafson's law as an indication of the extent to which a particular computer code is parallelized. It was proposed by Alan H. Karp and Horace P. Flatt in 1990.

Data parallelism is parallelization across multiple processors in parallel computing environments. It focuses on distributing the data across different nodes, which operate on the data in parallel. It can be applied on regular data structures like arrays and matrices by working on each element in parallel. It contrasts to task parallelism as another form of parallelism.
Relaxed sequential in computer science is an execution model describing the ability for a parallel program to run sequentially. If a parallel program has a valid sequential execution it is said to follow a relaxed sequential execution model. It does not need to be efficient.

In queueing theory, a discipline within the mathematical theory of probability, an M/M/1 queue represents the queue length in a system having a single server, where arrivals are determined by a Poisson process and job service times have an exponential distribution. The model name is written in Kendall's notation. The model is the most elementary of queueing models and an attractive object of study as closed-form expressions can be obtained for many metrics of interest in this model. An extension of this model with more than one server is the M/M/c queue.
Bit-level parallelism is a form of parallel computing based on increasing processor word size. Increasing the word size reduces the number of instructions the processor must execute in order to perform an operation on variables whose sizes are greater than the length of the word.
In computer architecture, bit-serial architectures send data one bit at a time, along a single wire, in contrast to bit-parallel word architectures, in which data values are sent all bits or a word at once along a group of wires.
In queueing theory, a discipline within the mathematical theory of probability, the M/M/∞ queue is a multi-server queueing model where every arrival experiences immediate service and does not wait. In Kendall's notation it describes a system where arrivals are governed by a Poisson process, there are infinitely many servers, so jobs do not need to wait for a server. Each job has an exponentially distributed service time. It is a limit of the M/M/c queue model where the number of servers c becomes very large.

