
A central processing unit (CPU), also called a central processor, main processor, or just processor, is the most important processor in a given computer. Its electronic circuitry executes instructions of a computer program, such as arithmetic, logic, controlling, and input/output (I/O) operations. This role contrasts with that of external components, such as main memory and I/O circuitry, and specialized coprocessors such as graphics processing units (GPUs).

A superscalar processor is a CPU that implements a form of parallelism called instruction-level parallelism within a single processor. In contrast to a scalar processor, which can execute at most one single instruction per clock cycle, a superscalar processor can execute more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to different execution units on the processor. It therefore allows more throughput than would otherwise be possible at a given clock rate. Each execution unit is not a separate processor, but an execution resource within a single CPU such as an arithmetic logic unit.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
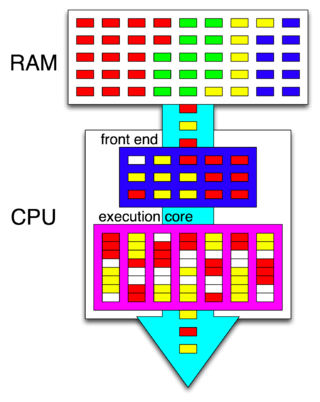
Hyper-threading is Intel's proprietary simultaneous multithreading (SMT) implementation used to improve parallelization of computations performed on x86 microprocessors. It was introduced on Xeon server processors in February 2002 and on Pentium 4 desktop processors in November 2002. Since then, Intel has included this technology in Itanium, Atom, and Core 'i' Series CPUs, among others.
In computer engineering, instruction pipelining is a technique for implementing instruction-level parallelism within a single processor. Pipelining attempts to keep every part of the processor busy with some instruction by dividing incoming instructions into a series of sequential steps performed by different processor units with different parts of instructions processed in parallel.

Instruction-level parallelism (ILP) is the parallel or simultaneous execution of a sequence of instructions in a computer program. More specifically ILP refers to the average number of instructions run per step of this parallel execution.
Simultaneous multithreading (SMT) is a technique for improving the overall efficiency of superscalar CPUs with hardware multithreading. SMT permits multiple independent threads of execution to better use the resources provided by modern processor architectures.
Fetching the instruction opcodes from program memory well in advance is known as prefetching and it is served by using a prefetch input queue (PIQ). The pre-fetched instructions are stored in a queue. The fetching of opcodes well in advance, prior to their need for execution, increases the overall efficiency of the processor boosting its speed. The processor no longer has to wait for the memory access operations for the subsequent instruction opcode to complete. This architecture was prominently used in the Intel 8086 microprocessor.
A barrel processor is a CPU that switches between threads of execution on every cycle. This CPU design technique is also known as "interleaved" or "fine-grained" temporal multithreading. Unlike simultaneous multithreading in modern superscalar architectures, it generally does not allow execution of multiple instructions in one cycle.

In electronics, computer science and computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as μarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.

Hardware acceleration is the use of computer hardware designed to perform specific functions more efficiently when compared to software running on a general-purpose central processing unit (CPU). Any transformation of data that can be calculated in software running on a generic CPU can also be calculated in custom-made hardware, or in some mix of both.
MAJC was a Sun Microsystems multi-core, multithreaded, very long instruction word (VLIW) microprocessor design from the mid-to-late 1990s. Originally called the UltraJava processor, the MAJC processor was targeted at running Java programs, whose "late compiling" allowed Sun to make several favourable design decisions. The processor was released into two commercial graphical cards from Sun. Lessons learned regarding multi-threads on a multi-core processor provided a basis for later OpenSPARC implementations such as the UltraSPARC T1.
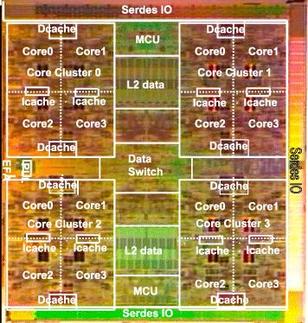
Rock was a multithreading, multicore, SPARC microprocessor under development at Sun Microsystems. Canceled in 2010, it was a separate project from the SPARC T-Series (CoolThreads/Niagara) family of processors.

In computer architecture, multithreading is the ability of a central processing unit (CPU) to provide multiple threads of execution.
In computer architecture, memory-level parallelism (MLP) is the ability to have pending multiple memory operations, in particular cache misses or translation lookaside buffer (TLB) misses, at the same time.
Runahead is a technique that allows a computer processor to speculatively pre-process instructions during cache miss cycles. The pre-processed instructions are used to generate instruction and data stream prefetches by executing instructions leading to cache misses before they would normally occur, effectively hiding memory latency. In runahead, the processor uses the idle execution resources to calculate instruction and data stream addresses using the available information that is independent of a cache miss. Once the processor has resolved the initial cache miss, all runahead results are discarded, and the processor resumes execution as normal. The primary use case of the technique is to mitigate the effects of the memory wall. The technique may also be used for other purposes, such as pre-computing branch outcomes to achieve highly accurate branch prediction.
In computing, a cache control instruction is a hint embedded in the instruction stream of a processor intended to improve the performance of hardware caches, using foreknowledge of the memory access pattern supplied by the programmer or compiler. They may reduce cache pollution, reduce bandwidth requirement, bypass latencies, by providing better control over the working set. Most cache control instructions do not affect the semantics of a program, although some can.
A thread block is a programming abstraction that represents a group of threads that can be executed serially or in parallel. For better process and data mapping, threads are grouped into thread blocks. The number of threads in a thread block was formerly limited by the architecture to a total of 512 threads per block, but as of March 2010, with compute capability 2.x and higher, blocks may contain up to 1024 threads. The threads in the same thread block run on the same stream processor. Threads in the same block can communicate with each other via shared memory, barrier synchronization or other synchronization primitives such as atomic operations.
Latency oriented processor architecture is the microarchitecture of a microprocessor designed to serve a serial computing thread with a low latency. This is typical of most central processing units (CPU) being developed since the 1970s. These architectures, in general, aim to execute as many instructions as possible belonging to a single serial thread, in a given window of time; however, the time to execute a single instruction completely from fetch to retire stages may vary from a few cycles to even a few hundred cycles in some cases. Latency oriented processor architectures are the opposite of throughput-oriented processors which concern themselves more with the total throughput of the system, rather than the service latencies for all individual threads that they work on.
A CPU cache is a piece of hardware that reduces access time to data in memory by keeping some part of the frequently used data of the main memory in a 'cache' of smaller and faster memory.