In linear algebra, the determinant is a scalar value that can be computed from the elements of a square matrix and encodes certain properties of the linear transformation described by the matrix. The determinant of a matrix A is denoted det(A), det A, or |A|. Geometrically, it can be viewed as the volume scaling factor of the linear transformation described by the matrix. This is also the signed volume of the n-dimensional parallelepiped spanned by the column or row vectors of the matrix. The determinant is positive or negative according to whether the linear mapping preserves or reverses the orientation of n-space.

In probability theory and statistics, the exponential distribution is the probability distribution that describes the time between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

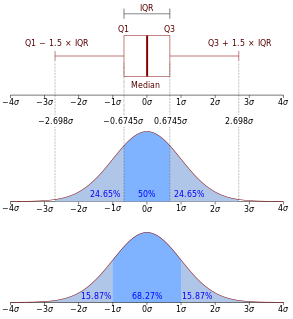
In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.

In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are three different parametrizations in common use:
- With a shape parameter k and a scale parameter θ.
- With a shape parameter α = k and an inverse scale parameter β = 1/θ, called a rate parameter.
- With a shape parameter k and a mean parameter μ = kθ = α/β.
In linear algebra, an n-by-n square matrix A is called invertible if there exists an n-by-n square matrix B such that
In statistics, the matrix normal distribution or matrix Gaussian distribution is a probability distribution that is a generalization of the multivariate normal distribution to matrix-valued random variables.
In mathematics, more specifically in multivariable calculus, the implicit function theorem is a tool that allows relations to be converted to functions of several real variables. It does so by representing the relation as the graph of a function. There may not be a single function whose graph can represent the entire relation, but there may be such a function on a restriction of the domain of the relation. The implicit function theorem gives a sufficient condition to ensure that there is such a function.
In probability and statistics, the Dirichlet distribution, often denoted , is a family of continuous multivariate probability distributions parameterized by a vector of positive reals. It is a multivariate generalization of the beta distribution, hence its alternative name of Multivariate Beta distribution (MBD). Dirichlet distributions are commonly used as prior distributions in Bayesian statistics, and in fact the Dirichlet distribution is the conjugate prior of the categorical distribution and multinomial distribution.
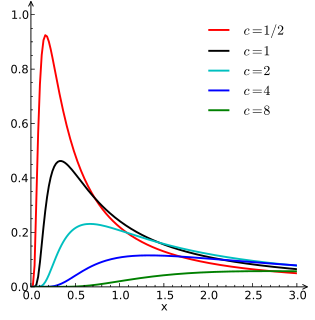
In probability theory and statistics, the Lévy distribution, named after Paul Lévy, is a continuous probability distribution for a non-negative random variable. In spectroscopy, this distribution, with frequency as the dependent variable, is known as a van der Waals profile. It is a special case of the inverse-gamma distribution. It is a stable distribution.
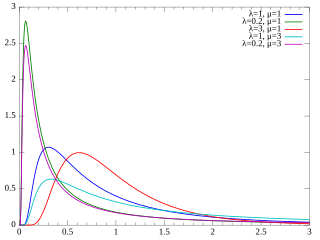
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
In statistics, the inverse Wishart distribution, also called the inverted Wishart distribution, is a probability distribution defined on real-valued positive-definite matrices. In Bayesian statistics it is used as the conjugate prior for the covariance matrix of a multivariate normal distribution.
In probability theory and statistics, the Dirichlet-multinomial distribution is a family of discrete multivariate probability distributions on a finite support of non-negative integers. It is also called the Dirichlet compound multinomial distribution (DCM) or multivariate Pólya distribution. It is a compound probability distribution, where a probability vector p is drawn from a Dirichlet distribution with parameter vector , and an observation drawn from a multinomial distribution with probability vector p and number of trials n. The compounding corresponds to a Polya urn scheme. It is frequently encountered in Bayesian statistics, empirical Bayes methods and classical statistics as an overdispersed multinomial distribution.
In statistics, the generalized Dirichlet distribution (GD) is a generalization of the Dirichlet distribution with a more general covariance structure and almost twice the number of parameters. Random variables with a GD distribution are not completely neutral.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.
In probability theory, the family of complex normal distributions characterizes complex random variables whose real and imaginary parts are jointly normal. The complex normal family has three parameters: location parameter μ, covariance matrix , and the relation matrix . The standard complex normal is the univariate distribution with , , and .

In probability theory, a logit-normal distribution is a probability distribution of a random variable whose logit has a normal distribution. If Y is a random variable with a normal distribution, and P is the standard logistic function, then X = P(Y) has a logit-normal distribution; likewise, if X is logit-normally distributed, then Y = logit(X)= log is normally distributed. It is also known as the logistic normal distribution, which often refers to a multinomial logit version (e.g.).
In statistics, the matrix t-distribution is the generalization of the multivariate t-distribution from vectors to matrices. The matrix t-distribution shares the same relationship with the multivariate t-distribution that the matrix normal distribution shares with the multivariate normal distribution. For example, the matrix t-distribution is the compound distribution that results from sampling from a matrix normal distribution having sampled the covariance matrix of the matrix normal from an inverse Wishart distribution.
In statistics, the graphical lasso is an algorithm to estimate the precision matrix from the observations from multivariate Gaussian distribution.
In statistics, the matrix variate beta distribution is a generalization of the beta distribution. If is a positive definite matrix with a matrix variate beta distribution, and are real parameters, we write . The probability density function for is:
A. K. Gupta and D. K. Nagar 1999. "Matrix variate distributions". Chapman and Hall.