
The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
The Resource Description Framework (RDF) is a World Wide Web Consortium (W3C) standard originally designed as a data model for metadata. It has come to be used as a general method for description and exchange of graph data. RDF provides a variety of syntax notations and data serialization formats, with Turtle currently being the most widely used notation.
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects.
SPARQL is an RDF query language—that is, a semantic query language for databases—able to retrieve and manipulate data stored in Resource Description Framework (RDF) format. It was made a standard by the RDF Data Access Working Group (DAWG) of the World Wide Web Consortium, and is recognized as one of the key technologies of the semantic web. On 15 January 2008, SPARQL 1.0 was acknowledged by W3C as an official recommendation, and SPARQL 1.1 in March, 2013.

FOAF is a machine-readable ontology describing persons, their activities and their relations to other people and objects. Anyone can use FOAF to describe themselves. FOAF allows groups of people to describe social networks without the need for a centralised database.
A semantic wiki is a wiki that has an underlying model of the knowledge described in its pages. Regular, or syntactic, wikis have structured text and untyped hyperlinks. Semantic wikis, on the other hand, provide the ability to capture or identify information about the data within pages, and the relationships between pages, in ways that can be queried or exported like a database through semantic queries.
RDFa or Resource Description Framework in Attributes is a W3C Recommendation that adds a set of attribute-level extensions to HTML, XHTML and various XML-based document types for embedding rich metadata within Web documents. The Resource Description Framework (RDF) data-model mapping enables its use for embedding RDF subject-predicate-object expressions within XHTML documents. It also enables the extraction of RDF model triples by compliant user agents.
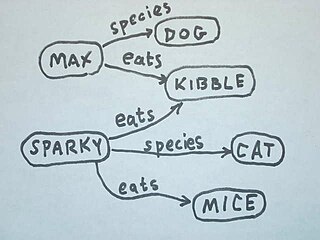
The ultimate goal of semantic technology is to help machines understand data. To enable the encoding of semantics with the data, well-known technologies are RDF and OWL. These technologies formally represent the meaning involved in information. For example, ontology can describe concepts, relationships between things, and categories of things. These embedded semantics with the data offer significant advantages such as reasoning over data and dealing with heterogeneous data sources.
Simple Knowledge Organization System (SKOS) is a W3C recommendation designed for representation of thesauri, classification schemes, taxonomies, subject-heading systems, or any other type of structured controlled vocabulary. SKOS is part of the Semantic Web family of standards built upon RDF and RDFS, and its main objective is to enable easy publication and use of such vocabularies as linked data.
Haystack is a project at the Massachusetts Institute of Technology to research and develop several applications around personal information management and the Semantic Web. The most notable of those applications is the Haystack client, a research personal information manager (PIM) and one of the first to be based on semantic desktop technologies. The Haystack client is published as open source software under the BSD license.
Oracle Spatial and Graph, formerly Oracle Spatial, is a free option component of the Oracle Database. The spatial features in Oracle Spatial and Graph aid users in managing geographic and location-data in a native type within an Oracle database, potentially supporting a wide range of applications — from automated mapping, facilities management, and geographic information systems (AM/FM/GIS), to wireless location services and location-enabled e-business. The graph features in Oracle Spatial and Graph include Oracle Network Data Model (NDM) graphs used in traditional network applications in major transportation, telcos, utilities and energy organizations and RDF semantic graphs used in social networks and social interactions and in linking disparate data sets to address requirements from the research, health sciences, finance, media and intelligence communities.
Semantic publishing on the Web, or semantic web publishing, refers to publishing information on the web as documents accompanied by semantic markup. Semantic publication provides a way for computers to understand the structure and even the meaning of the published information, making information search and data integration more efficient.
Semantically Interlinked Online Communities Project is a Semantic Web technology. SIOC provides methods for interconnecting discussion methods such as blogs, forums and mailing lists to each other. It consists of the SIOC ontology, an open-standard machine-readable format for expressing the information contained both explicitly and implicitly in Internet discussion methods, of SIOC metadata producers for a number of popular blogging platforms and content management systems, and of storage and browsing/searching systems for leveraging this SIOC data.
In computer science, the semantic desktop is a collective term for ideas related to changing a computer's user interface and data handling capabilities so that data are more easily shared between different applications or tasks and so that data that once could not be automatically processed by a computer could be. It also encompasses some ideas about being able to share information automatically between different people. This concept is very much related to the Semantic Web, but is distinct insofar as its main concern is the personal use of information.
SIMILE was a joint research project run by the World Wide Web Consortium (W3C), Massachusetts Institute of Technology Libraries and MIT CSAIL and funded by the Andrew W. Mellon Foundation. The project ran from 2003 to August 2008. It focused on developing tools to increase the interoperability of disparate digital collections. Much of SIMILE's technical focus is oriented towards Semantic Web technology and standards such as Resource Description Framework (RDF).
Hyperdata are data objects linked to other data objects in other places, as hypertext indicates text linked to other text in other places. Hyperdata enables the formation of a web of data, evolving from the "data on the Web" that is not inter-related.
The Semantic Web Stack, also known as Semantic Web Cake or Semantic Web Layer Cake, illustrates the architecture of the Semantic Web.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
The Open Semantic Framework (OSF) is an integrated software stack using semantic technologies for knowledge management. It has a layered architecture that combines existing open source software with additional open source components developed specifically to provide a complete Web application framework. OSF is made available under the Apache 2 license.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.