Mach is a kernel developed at Carnegie Mellon University to support operating system research, primarily distributed and parallel computing. Mach is often mentioned as one of the earliest examples of a microkernel. However, not all versions of Mach are microkernels. Mach's derivatives are the basis of the modern operating system kernels in GNU Hurd and Apple's operating systems macOS, iOS, tvOS, and watchOS.

Symmetric multiprocessing (SMP) involves a multiprocessor computer hardware and software architecture where two or more identical processors are connected to a single, shared main memory, have full access to all input and output devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
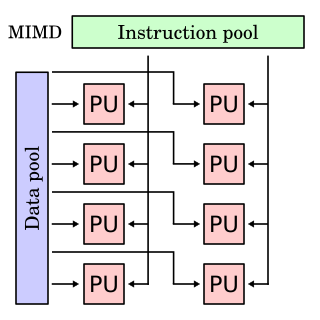
In computing, MIMD is a technique employed to achieve parallelism. Machines using MIMD have a number of processors that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data. MIMD architectures may be used in a number of application areas such as computer-aided design/computer-aided manufacturing, simulation, modeling, and as communication switches. MIMD machines can be of either shared memory or distributed memory categories. These classifications are based on how MIMD processors access memory. Shared memory machines may be of the bus-based, extended, or hierarchical type. Distributed memory machines may have hypercube or mesh interconnection schemes.

In computer architecture, cache coherence is the uniformity of shared resource data that ends up stored in multiple local caches. When clients in a system maintain caches of a common memory resource, problems may arise with incoherent data, which is particularly the case with CPUs in a multiprocessing system.

The UNIVAC 1100/2200 series is a series of compatible 36-bit computer systems, beginning with the UNIVAC 1107 in 1962, initially made by Sperry Rand. The series continues to be supported today by Unisys Corporation as the ClearPath Dorado Series. The solid-state 1107 model number was in the same sequence as the earlier vacuum-tube computers, but the early computers were not compatible with the solid-state successors.

In computer science, distributed memory refers to a multiprocessor computer system in which each processor has its own private memory. Computational tasks can only operate on local data, and if remote data is required, the computational task must communicate with one or more remote processors. In contrast, a shared memory multiprocessor offers a single memory space used by all processors. Processors do not have to be aware where data resides, except that there may be performance penalties, and that race conditions are to be avoided.
In computer science, distributed shared memory (DSM) is a form of memory architecture where physically separated memories can be addressed as one logically shared address space. Here, the term "shared" does not mean that there is a single centralized memory, but that the address space is "shared". Distributed global address space (DGAS), is a similar term for a wide class of software and hardware implementations, in which each node of a cluster has access to shared memory in addition to each node's non-shared private memory.
A memory barrier, also known as a membar, memory fence or fence instruction, is a type of barrier instruction that causes a central processing unit (CPU) or compiler to enforce an ordering constraint on memory operations issued before and after the barrier instruction. This typically means that operations issued prior to the barrier are guaranteed to be performed before operations issued after the barrier.
Cache only memory architecture (COMA) is a computer memory organization for use in multiprocessors in which the local memories at each node are used as cache. This is in contrast to using the local memories as actual main memory, as in NUMA organizations.
Unified Parallel C (UPC) is an extension of the C programming language designed for high-performance computing on large-scale parallel machines, including those with a common global address space and those with distributed memory. The programmer is presented with a single shared, partitioned address space, where variables may be directly read and written by any processor, but each variable is physically associated with a single processor. UPC uses a single program, multiple data (SPMD) model of computation in which the amount of parallelism is fixed at program startup time, typically with a single thread of execution per processor.

The C.mmp was an early MIMD multiprocessor system developed at Carnegie Mellon University by William Wulf (1971). The notation C.mmp came from the PMS notation of Bell and Newell, where a CPU was designated as C and a variant was noted by the dot notation; mmp stood for Multi-Mini-Processor
In computer science, a partitioned global address space (PGAS) is a parallel programming model. It assumes a global memory address space that is logically partitioned and a portion of it is local to each process, thread, or processing element. The novelty of PGAS is that the portions of the shared memory space may have an affinity for a particular process, thereby exploiting locality of reference. The PGAS model is the basis of Unified Parallel C, Coarray Fortran, Split-C, Fortress, Chapel, X10, UPC++, Coarray C++, Global Arrays, DASH and SHMEM. In standard Fortran, this model is now an integrated part of the language. PGAS attempts to combine the advantages of a SPMD programming style for distributed memory systems with the data referencing semantics of shared memory systems. This is more realistic than the traditional shared memory approach of one flat address space, because hardware-specific data locality can be modeled in the partitioning of the address space.
An Active message is a messaging object capable of performing processing on its own. It is a lightweight messaging protocol used to optimize network communications with an emphasis on reducing latency by removing software overheads associated with buffering and providing applications with direct user-level access to the network hardware. This contrasts with traditional computer-based messaging systems in which messages are passive entities with no processing power.

The kernel is a computer program that is the core of a computer's operating system, with complete control over everything in the system. On most systems, it is one of the first programs loaded on start-up. It handles the rest of start-up as well as input/output requests from software, translating them into data-processing instructions for the central processing unit. It handles memory and peripherals like keyboards, monitors, printers, and speakers.
Manycore processors are specialist multi-core processors designed for a high degree of parallel processing, containing a large number of simpler, independent processor cores. Manycore processors are used extensively in embedded computers and high-performance computing. As of November 2018, the world's third fastest supercomputer, the Chinese Sunway TaihuLight, obtains its performance from 40,960 SW26010 manycore processors, each containing 256 cores.
In operating systems, memory management is the function responsible for managing the computer's primary memory.
SHMEM is a family of parallel programming libraries, providing one-sided, RDMA, parallel-processing interfaces for low-latency distributed-memory supercomputers. The SHMEM acronym was subsequently reverse engineered to mean "Symmetric Hierarchical MEMory”. Later it was expanded to distributed memory parallel computer clusters, and is used as parallel programming interface or as low-level interface to build partitioned global address space (PGAS) systems and languages. “Libsma”, the first SHMEM library, was created by Richard Smith at Cray Research in 1993 as a set of thin interfaces to access the CRAY T3D’s inter-processor-communication hardware. SHMEM has been implemented by Cray Research, SGI, Cray Inc., Quadrics, HP, GSHMEM, IBM, QLogic, Mellanox, Universities of Houston and Florida; there is also open-source OpenSHMEM.
Heterogeneous computing refers to systems that use more than one kind of processor or cores. These systems gain performance or energy efficiency not just by adding the same type of processors, but by adding dissimilar coprocessors, usually incorporating specialized processing capabilities to handle particular tasks.
A multiprocessor system is defined as :