Related Research Articles

Michael Everson is an American and Irish linguist, script encoder, typesetter, type designer and publisher. He runs a publishing company called Evertype, through which he has published over one hundred books since 2006.

The Ol Chiki script, also known as Ol Chemetʼ, Ol Ciki, Ol, and sometimes as the Santhali alphabet is the official writing system for Santhali, an Austroasiatic language recognized as an official regional language in India. It was invented by Pandit Raghunath Murmu in 1925, and is one of the official scripts of the Indian Republic. It has 30 letters, the design of which is intended to evoke natural shapes. The script is written from left to right, and has two styles. Unicode does not maintain a distinction between these two, as is typical for print and cursive variants of a script. In both styles, the script is unicameral.
The shapes of the letters are not arbitrary, but reflect the names for the letters, which are words, usually the names of objects or actions representing conventionalized form in the pictorial shape of the characters.
Geometric Shapes is a Unicode block of 96 symbols at code point range U+25A0–25FF.
Letterlike Symbols is a Unicode block containing 80 characters which are constructed mainly from the glyphs of one or more letters. In addition to this block, Unicode includes full styled mathematical alphabets, although Unicode does not explicitly categorize these characters as being "letterlike."
Block Elements is a Unicode block containing square block symbols of various fill and shading. Used along with block elements are box-drawing characters, shade characters, and terminal graphic characters. These can be used for filling regions of the screen and portraying drop shadows. Its block name in Unicode 1.0 was Blocks.
Control Pictures is a Unicode block containing characters for graphically representing the C0 control codes, and other control characters. Its block name in Unicode 1.0 was Pictures for Control Codes.
Specials is a short Unicode block of characters allocated at the very end of the Basic Multilingual Plane, at U+FFF0–FFFF. Of these 16 code points, five have been assigned since Unicode 3.0:
Cherokee is a Unicode block containing the syllabic characters for writing the Cherokee language. When Cherokee was first added to Unicode in version 3.0 it was treated as a unicameral alphabet, but in version 8.0 it was redefined as a bicameral script. The Cherokee block contains all the uppercase letters plus six lowercase letters. The Cherokee Supplement block, added in version 8.0, contains the rest of the lowercase letters. For backwards compatibility, the Unicode case folding algorithm—which usually converts a string to lowercase characters—maps Cherokee characters to uppercase.
Hiragana is a Unicode block containing hiragana characters for the Japanese language.
Katakana is a Unicode block containing katakana characters for the Japanese and Ainu languages.
Katakana Phonetic Extensions is a Unicode block containing additional small katakana characters for writing the Ainu language, in addition to characters in the Katakana block.
Kana Supplement is a Unicode block containing one archaic katakana character and 255 hentaigana characters. Additional hentaigana characters are encoded in the Kana Extended-A block.
Byzantine Musical Symbols is a Unicode block containing characters for representing Byzantine music in ekphonetic notation.

Enclosed Ideographic Supplement is a Unicode block containing forms of characters and words from Chinese, Japanese and Korean enclosed within or stylised as squares, brackets, or circles. It contains three such characters containing one or more kana, and many containing CJK ideographs. Many of its characters were added for compatibility with the Japanese ARIB STD-B24 standard. Six symbols from Chinese folk religion were added in Unicode version 10.
Cherokee Supplement is a Unicode block containing the syllabic characters for writing the Cherokee language. When Cherokee was first added to Unicode in version 3.0 it was treated as a unicameral alphabet, but in version 8.0 it was redefined as a bicameral script. The Cherokee Supplement block contains lowercase letters only, whereas the Cherokee block contains all the uppercase letters, together with six lowercase letters. For backwards compatibility, the Unicode case folding algorithm—which usually converts a string to lowercase characters—maps Cherokee characters to uppercase.
Kana Extended-A is a Unicode block containing hentaigana and historic kana characters. Additional hentaigana characters are encoded in the Kana Supplement block.
Symbols for Legacy Computing is a Unicode block containing graphic characters that were used for various home computers from the 1970s and 1980s and in Teletext broadcasting standards. It includes characters from the Amstrad CPC, MSX, Mattel Aquarius, RISC OS, MouseText, Atari ST, TRS-80 Color Computer, Oric, Texas Instruments TI-99/4A, TRS-80, Minitel, Teletext, ATASCII, PETSCII, ZX80, and ZX81 character sets. Semigraphics characters are also included in the form of new block-shaped characters, line-drawing characters, and 60 "sextant" characters.
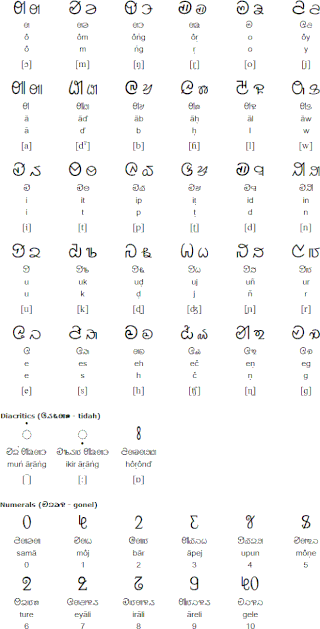
The Ol Onal, also known as also known as Bhumij Lipi or Bhumij Onal, is an alphabetic writing system for the Bhumij language. Ol Onal script was created between 1981 and 1992 by Ol Guru Mahendra Nath Sardar. Ol Onal script is used to write the Bhumij language in some parts of West Bengal, Jharkhand, Orissa, and Assam.

Meitei input methods are the methods that allow users of computers to input texts in the Meitei script, systematically for Meitei language.
References
- ↑ "Unicode character database". The Unicode Standard. Retrieved 2023-07-26.
- ↑ "Enumerated Versions of The Unicode Standard". The Unicode Standard. Retrieved 2023-07-26.