In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children. Unlike other self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as databases and file systems.

In computer science, a tree is a widely used abstract data type that represents a hierarchical tree structure with a set of connected nodes. Each node in the tree can be connected to many children, but must be connected to exactly one parent, except for the root node, which has no parent. These constraints mean there are no cycles or "loops", and also that each child can be treated like the root node of its own subtree, making recursion a useful technique for tree traversal. In contrast to linear data structures, many trees cannot be represented by relationships between neighboring nodes in a single straight line.
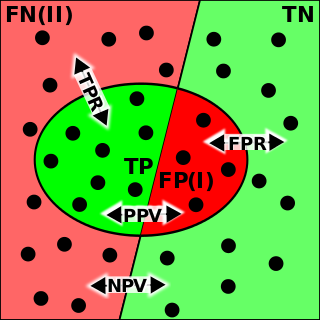
Binary classification is the task of classifying the elements of a set into one of two groups. Typical binary classification problems include:

A decision tree is a decision support hierarchical model that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm that only contains conditional control statements.

A star system or stellar system is a small number of stars that orbit each other, bound by gravitational attraction. A large group of stars bound by gravitation is generally called a star cluster or galaxy, although, broadly speaking, they are also star systems. Star systems are not to be confused with planetary systems, which include planets and similar bodies.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.
The Lempel–Ziv–Markov chain algorithm (LZMA) is an algorithm used to perform lossless data compression. It has been under development since either 1996 or 1998 by Igor Pavlov and was first used in the 7z format of the 7-Zip archiver. This algorithm uses a dictionary compression scheme somewhat similar to the LZ77 algorithm published by Abraham Lempel and Jacob Ziv in 1977 and features a high compression ratio and a variable compression-dictionary size, while still maintaining decompression speed similar to other commonly used compression algorithms.
In computer science, a binary decision diagram (BDD) or branching program is a data structure that is used to represent a Boolean function. On a more abstract level, BDDs can be considered as a compressed representation of sets or relations. Unlike other compressed representations, operations are performed directly on the compressed representation, i.e. without decompression.
Decision tree learning is a supervised learning approach used in statistics, data mining and machine learning. In this formalism, a classification or regression decision tree is used as a predictive model to draw conclusions about a set of observations.
In computer science, tree traversal is a form of graph traversal and refers to the process of visiting each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.
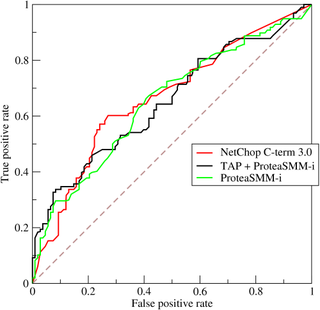
A receiver operating characteristic curve, or ROC curve, is a graphical plot that illustrates the performance of a binary classifier model at varying threshold values.
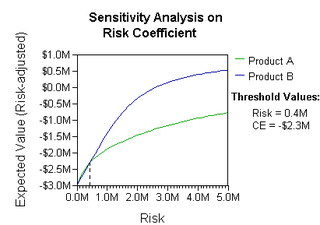
Multiple-criteria decision-making (MCDM) or multiple-criteria decision analysis (MCDA) is a sub-discipline of operations research that explicitly evaluates multiple conflicting criteria in decision making. It is also known as multiple attribute utility theory, multiple attribute value theory, multiple attribute preference theory, and multi-objective decision analysis.
When classification is performed by a computer, statistical methods are normally used to develop the algorithm.
Troubleshooting is a form of problem solving, often applied to repair failed products or processes on a machine or a system. It is a logical, systematic search for the source of a problem in order to solve it, and make the product or process operational again. Troubleshooting is needed to identify the symptoms. Determining the most likely cause is a process of elimination—eliminating potential causes of a problem. Finally, troubleshooting requires confirmation that the solution restores the product or process to its working state.
In statistics, multinomial logistic regression is a classification method that generalizes logistic regression to multiclass problems, i.e. with more than two possible discrete outcomes. That is, it is a model that is used to predict the probabilities of the different possible outcomes of a categorically distributed dependent variable, given a set of independent variables.
In phylogenetics, a single-access key is an identification key where the sequence and structure of identification steps is fixed by the author of the key. At each point in the decision process, multiple alternatives are offered, each leading to a result or a further choice. The alternatives are commonly called "leads", and the set of leads at a given point a "couplet".
In machine learning and statistical classification, multiclass classification or multinomial classification is the problem of classifying instances into one of three or more classes. For example, deciding on whether an image is showing a banana, an orange, or an apple is a multiclass classification problem, with three possible classes, while deciding on whether an image contains an apple or not is a binary classification problem.
DEX is a qualitative multi-criteria decision analysis (MCDA) method for decision making and is implemented in DEX software. This method was developed by a research team led by Bohanec, Bratko, and Rajkovič. The method supports decision makers in making complex decisions based on multiple, possibly conflicting, attributes. In DEX, all attributes are qualitative and can take values represented by words, such as “low” or “excellent”. Attributes are generally organized in a hierarchy. The evaluation of decision alternatives is carried out by utility functions, which are represented in the form of decision rules. All attributes are assumed to be discrete. Additionally, they can be preferentially ordered, so that a higher ordinal value represents a better preference.
In computer science, a weak heap is a data structure for priority queues, combining features of the binary heap and binomial heap. It can be stored in an array as an implicit binary tree like a binary heap, and has the efficiency guarantees of binomial heaps.
In statistics, specifically regression analysis, a binary regression estimates a relationship between one or more explanatory variables and a single output binary variable. Generally the probability of the two alternatives is modeled, instead of simply outputting a single value, as in linear regression.