
In mathematics, two quantities are in the golden ratio if their ratio is the same as the ratio of their sum to the larger of the two quantities. Expressed algebraically, for quantities and with , is in a golden ratio to if
The number π is a mathematical constant that is the ratio of a circle's circumference to its diameter, approximately equal to 3.14159. The number π appears in many formulae across mathematics and physics. It is an irrational number, meaning that it cannot be expressed exactly as a ratio of two integers, although fractions such as are commonly used to approximate it. Consequently, its decimal representation never ends, nor enters a permanently repeating pattern. It is a transcendental number, meaning that it cannot be a solution of an equation involving only finite sums, products, powers, and integers. The transcendence of π implies that it is impossible to solve the ancient challenge of squaring the circle with a compass and straightedge. The decimal digits of π appear to be randomly distributed, but no proof of this conjecture has been found.
The kinetic theory of gases is a simple classical model of the thermodynamic behavior of gases. It treats a gas as composed of numerous particles, too small to see with a microscope, which are constantly in random motion. Their collisions with each other and with the walls of their container are used to explain physical properties of the gas—for example, the relationship between its temperature, pressure, and volume. The particles are now known to be the atoms or molecules of the gas.
Pearson's chi-squared test or Pearson's test is a statistical test applied to sets of categorical data to evaluate how likely it is that any observed difference between the sets arose by chance. It is the most widely used of many chi-squared tests – statistical procedures whose results are evaluated by reference to the chi-squared distribution. Its properties were first investigated by Karl Pearson in 1900. In contexts where it is important to improve a distinction between the test statistic and its distribution, names similar to Pearson χ-squared test or statistic are used.

A torsion spring is a spring that works by twisting its end along its axis; that is, a flexible elastic object that stores mechanical energy when it is twisted. When it is twisted, it exerts a torque in the opposite direction, proportional to the amount (angle) it is twisted. There are various types:
Binomial test is an exact test of the statistical significance of deviations from a theoretically expected distribution of observations into two categories using sample data.
Cohen's kappa coefficient is a statistic that is used to measure inter-rater reliability for qualitative (categorical) items. It is generally thought to be a more robust measure than simple percent agreement calculation, as κ takes into account the possibility of the agreement occurring by chance. There is controversy surrounding Cohen's kappa due to the difficulty in interpreting indices of agreement. Some researchers have suggested that it is conceptually simpler to evaluate disagreement between items.

In probability theory and directional statistics, the von Mises distribution is a continuous probability distribution on the circle. It is a close approximation to the wrapped normal distribution, which is the circular analogue of the normal distribution. A freely diffusing angle on a circle is a wrapped normally distributed random variable with an unwrapped variance that grows linearly in time. On the other hand, the von Mises distribution is the stationary distribution of a drift and diffusion process on the circle in a harmonic potential, i.e. with a preferred orientation. The von Mises distribution is the maximum entropy distribution for circular data when the real and imaginary parts of the first circular moment are specified. The von Mises distribution is a special case of the von Mises–Fisher distribution on the N-dimensional sphere.

In electromagnetics, directivity is a parameter of an antenna or optical system which measures the degree to which the radiation emitted is concentrated in a single direction. It is the ratio of the radiation intensity in a given direction from the antenna to the radiation intensity averaged over all directions. Therefore, the directivity of a hypothetical isotropic radiator is 1, or 0 dBi.

Approximations for the mathematical constant pi in the history of mathematics reached an accuracy within 0.04% of the true value before the beginning of the Common Era. In Chinese mathematics, this was improved to approximations correct to what corresponds to about seven decimal digits by the 5th century.
Fleiss' kappa is a statistical measure for assessing the reliability of agreement between a fixed number of raters when assigning categorical ratings to a number of items or classifying items. This contrasts with other kappas such as Cohen's kappa, which only work when assessing the agreement between not more than two raters or the intra-rater reliability. The measure calculates the degree of agreement in classification over that which would be expected by chance.
The Debye–Hückel theory was proposed by Peter Debye and Erich Hückel as a theoretical explanation for departures from ideality in solutions of electrolytes and plasmas. It is a linearized Poisson–Boltzmann model, which assumes an extremely simplified model of electrolyte solution but nevertheless gave accurate predictions of mean activity coefficients for ions in dilute solution. The Debye–Hückel equation provides a starting point for modern treatments of non-ideality of electrolyte solutions.
In statistics, inter-rater reliability is the degree of agreement among independent observers who rate, code, or assess the same phenomenon.
Expected shortfall (ES) is a risk measure—a concept used in the field of financial risk measurement to evaluate the market risk or credit risk of a portfolio. The "expected shortfall at q% level" is the expected return on the portfolio in the worst of cases. ES is an alternative to value at risk that is more sensitive to the shape of the tail of the loss distribution.
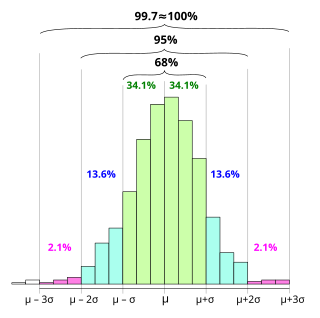
In statistics, the 68–95–99.7 rule, also known as the empirical rule, and sometimes abbreviated 3sr, is a shorthand used to remember the percentage of values that lie within an interval estimate in a normal distribution: approximately 68%, 95%, and 99.7% of the values lie within one, two, and three standard deviations of the mean, respectively.
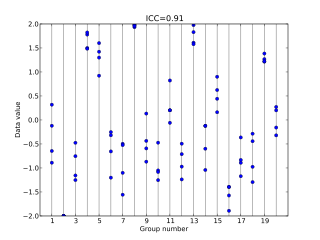
In statistics, the intraclass correlation, or the intraclass correlation coefficient (ICC), is a descriptive statistic that can be used when quantitative measurements are made on units that are organized into groups. It describes how strongly units in the same group resemble each other. While it is viewed as a type of correlation, unlike most other correlation measures, it operates on data structured as groups rather than data structured as paired observations.
Multinomial test is the statistical test of the null hypothesis that the parameters of a multinomial distribution equal specified values; it is used for categorical data.
Krippendorff's alpha coefficient, named after academic Klaus Krippendorff, is a statistical measure of the agreement achieved when coding a set of units of analysis. Since the 1970s, alpha has been used in content analysis where textual units are categorized by trained readers, in counseling and survey research where experts code open-ended interview data into analyzable terms, in psychological testing where alternative tests of the same phenomena need to be compared, or in observational studies where unstructured happenings are recorded for subsequent analysis.
The Hosmer–Lemeshow test is a statistical test for goodness of fit and calibration for logistic regression models. It is used frequently in risk prediction models. The test assesses whether or not the observed event rates match expected event rates in subgroups of the model population. The Hosmer–Lemeshow test specifically identifies subgroups as the deciles of fitted risk values. Models for which expected and observed event rates in subgroups are similar are called well calibrated.
A Calvo contract is the name given in macroeconomics to the pricing model that when a firm sets a nominal price there is a constant probability that a firm might be able to reset its price which is independent of the time since the price was last reset. The model was first put forward by Guillermo Calvo in his 1983 article "Staggered Prices in a Utility-Maximizing Framework". The original article was written in a continuous time mathematical framework, but nowadays is mostly used in its discrete time version. The Calvo model is the most common way to model nominal rigidity in new Keynesian DSGE macroeconomic models.


