Structure
In UNL, the information conveyed by the natural language is represented sentence by sentence as a hypergraph composed of a set of directed binary labeled links between nodes or hypernodes. As an example, the English sentence "The sky was blue?!" can be represented in UNL as follows:
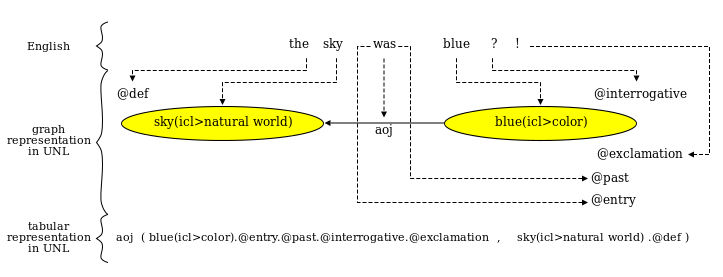
In the example above, sky(icl>natural world) and blue(icl>color), which represent individual concepts, are UW's attributes of an object directed to linking the semantic relation between the two UWs; "@def", "@interrogative", "@past", "@exclamation" and "@entry" are attributes modifying UWs.
UWs are expressed in natural language to be humanly readable. They consist of a "headword" (the UW root) and a "constraint list" (the UW suffix between parentheses), where the constraints are used to disambiguate the general concept conveyed by the headword. The set of UWs is organized in the UNL Ontology.
Relations are intended to represent semantic links between words in every existing language. They can be ontological (such as "icl" and "iof"), logical (such as "and" and "or"), or thematic (such as "agt" = agent, "ins" = instrument, "tim" = time, "plc" = place, etc.). There are currently 46 relations in the UNL Specs that jointly define the UNL syntax.
Within the UNL program, the process of representing natural language sentences in UNL graphs is called UNLization, and the process of generating natural language sentences out of UNL graphs is called NLization. UNLization is intended to be carried out semi-automatically (i.e., by humans with computer aids), and NLization is intended to be carried out automatically.
History
The UNL program started in 1996 as an initiative of the Institute of Advanced Studies (IAS) of the United Nations University (UNU) in Tokyo, Japan. In January 2001, the United Nations University set up an autonomous and non-profit organization, the UNDL Foundation, to be responsible for the development and management of the UNL program. It inherited from the UNU/IAS the mandate of implementing the UNL program.
The overall architecture of the UNL System has been developed with a set of basic software and tools.
It was recognized by the Patent Cooperation Treaty (PCT) for the "industrial applicability" of the UNL, which was obtained in May 2002 through the World Intellectual Property Organization (WIPO); the UNL acquired the US patents 6,704,700 and 7,107,206.
This page is based on this
Wikipedia article Text is available under the
CC BY-SA 4.0 license; additional terms may apply.
Images, videos and audio are available under their respective licenses.
