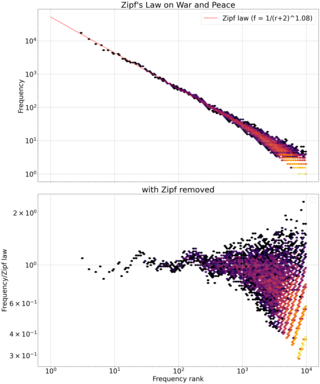
Zipf's law is an empirical law that often holds, approximately, when a list of measured values is sorted in decreasing order. It states that the value of the nth entry is inversely proportional to n.

In linguistics, Heaps' law is an empirical law which describes the number of distinct words in a document as a function of the document length. It can be formulated as
In information science and information retrieval, relevance denotes how well a retrieved document or set of documents meets the information need of the user. Relevance may include concerns such as timeliness, authority or novelty of the result.

Browsing is a kind of orienting strategy. It is supposed to identify something of relevance for the browsing organism. In context of humans, it is a metaphor taken from the animal kingdom. It is used, for example, about people browsing open shelves in libraries, window shopping, or browsing databases or the Internet.
The science of webometrics tries to measure the World Wide Web to get knowledge about the number and types of hyperlinks, structure of the World Wide Web and using patterns. According to Björneborn and Ingwersen, the definition of webometrics is "the study of the quantitative aspects of the construction and use of information resources, structures and technologies on the Web drawing on bibliometric and informetric approaches." The term webometrics was first coined by Almind and Ingwersen (1997). A second definition of webometrics has also been introduced, "the study of web-based content with primarily quantitative methods for social science research goals using techniques that are not specific to one field of study", which emphasizes the development of applied methods for use in the wider social sciences. The purpose of this alternative definition was to help publicize appropriate methods outside the information-science discipline rather than to replace the original definition within information science.
A book review is a form of literary criticism in which a book is merely described or analyzed based on content, style, and merit. A book review may be a primary source, opinion piece, summary review or scholarly review. Books can be reviewed for printed periodicals, magazines and newspapers, as school work, or for book websites on the Internet. A book review's length may vary from a single paragraph to a substantial essay. Such a review may evaluate the book on the basis of personal taste. Reviewers may use the occasion of a book review for an extended essay that can be closely or loosely related to the subject of the book, or to promulgate their own ideas on the topic of a fiction or non-fiction work.
Bibliometrics is the use of statistical methods to analyse books, articles and other publications, especially in scientific contents. Bibliometric methods are frequently used in the field of library and information science. Bibliometrics is closely associated with scientometrics, the analysis of scientific metrics and indicators, to the point that both fields largely overlap.

Lotka's law, named after Alfred J. Lotka, is one of a variety of special applications of Zipf's law. It describes the frequency of publication by authors in any given field. Let X be the number of publications, be the number of authors with publications, and be a constants depending on the specific field. Lotka's law states that .
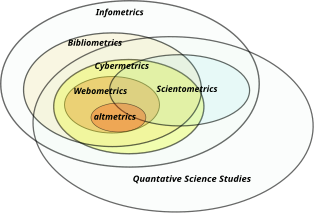
Informetrics is the study of quantitative aspects of information, it is an extension and evolution of traditional bibliometrics and scientometrics. Informetrics uses bibliometrics and scientometrics methods to study mainly the problems of literature information management and evaluation of science and technology. Informetrics is an independent discipline that uses quantitative methods from mathematics and statistics to study the process, phenomena, and law of informetrics. Informetrics has gained more attention as it is a common scientific method for academic evaluation, research hotspots in discipline, and trend analysis.
A bibliogram is a graphical representation of the frequency of certain target words, usually noun phrases, in a given text. The term was introduced in 2005 by Howard D. White to name the linguistic object studied, but not previously named, in informetrics, scientometrics and bibliometrics. The noun phrases in the ranking may be authors, journals, subject headings, or other indexing terms. The "stretches of text” may be a book, a set of related articles, a subject bibliography, a set of Web pages, and so on. Bibliograms are always generated from writings, usually from scholarly or scientific literature.
Source criticism is the process of evaluating an information source, i.e.: a document, a person, a speech, a fingerprint, a photo, an observation, or anything used in order to obtain knowledge. In relation to a given purpose, a given information source may be more or less valid, reliable or relevant. Broadly, "source criticism" is the interdisciplinary study of how information sources are evaluated for given tasks.
Bibliographic coupling, like co-citation, is a similarity measure that uses citation analysis to establish a similarity relationship between documents. Bibliographic coupling occurs when two works reference a common third work in their bibliographies. It is an indication that a probability exists that the two works treat a related subject matter.
Subject indexing is the act of describing or classifying a document by index terms, keywords, or other symbols in order to indicate what different documents are about, to summarize their contents or to increase findability. In other words, it is about identifying and describing the subject of documents. Indexes are constructed, separately, on three distinct levels: terms in a document such as a book; objects in a collection such as a library; and documents within a field of knowledge.
The Redalyc project is a bibliographic database and a digital library of Open Access journals, supported by the Universidad Autónoma del Estado de México with the help of numerous other higher education institutions and information systems.
Aboutness is a term used in library and information science (LIS), linguistics, philosophy of language, and philosophy of mind. In LIS, it is often considered synonymous with subject (documents). In the philosophy of mind it has been often considered synonymous with intentionality, perhaps since John Searle (1983). In the philosophy of logic and language it is understood as the way a piece of text relates to a subject matter or topic. In general, the term refers to the concept that a text, utterance, image, or action is on or of something.
Source literature is a kind of information source. It might, for example, be cited and used as sources in academic writings, and then called the literature on the subject.
Samuel Clement Bradford was a British mathematician, librarian and documentalist at the Science Museum in London. He developed "Bradford's law" regarding differences in demand for scientific journals. This work influences bibliometrics and citation analysis of scientific publications. Bradford founded the British Society for International Bibliography (BSIB) and he was elected president of International Federation for Information and Documentation (FID) in 1945. Bradford was a strong proponent of the UDC and of establishing abstracts of the scientific literature.

Documentation science is the study of the recording and retrieval of information. Documentation science gradually developed into the broader field of information science.
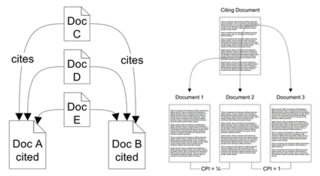
Co-citation is the frequency with which two documents are cited together by other documents. If at least one other document cites two documents in common, these documents are said to be co-cited. The more co-citations two documents receive, the higher their co-citation strength, and the more likely they are semantically related. Like bibliographic coupling, co-citation is a semantic similarity measure for documents that makes use of citation analyses.
Birger Hjørland is a professor of knowledge organization at the Royal School of Library and Information Science (RSLIS) in Copenhagen. His main areas of study pertain to theory of library and information science and of knowledge organization. Hjørland has contributed important developments to domain analysis and concept theory. He has been cited as an anchor of North American knowledge organization studies, as well as an information science pioneer.
