In computer science, a double-ended queue is an abstract data type that generalizes a queue, for which elements can be added to or removed from either the front (head) or back (tail). It is also often called a head-tail linked list, though properly this refers to a specific data structure implementation of a deque.
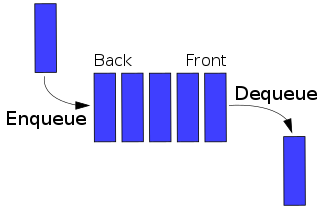
In computing and in systems theory, first in, first out, acronymized as FIFO, is a method for organizing the manipulation of a data structure where the oldest (first) entry, or "head" of the queue, is processed first.
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environments. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
In computer science, mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions. It is the requirement that one thread of execution never enters a critical section while a concurrent thread of execution is already accessing said critical section, which refers to an interval of time during which a thread of execution accesses a shared resource or shared memory.
In computer science, a semaphore is a variable or abstract data type used to control access to a common resource by multiple threads and avoid critical section problems in a concurrent system such as a multitasking operating system. Semaphores are a type of synchronization primitive. A trivial semaphore is a plain variable that is changed depending on programmer-defined conditions.
In computer science, a lock or mutex is a synchronization primitive that prevents state from being modified or accessed by multiple threads of execution at once. Locks enforce mutual exclusion concurrency control policies, and with a variety of possible methods there exist multiple unique implementations for different applications.

In computer science, the dining philosophers problem is an example problem often used in concurrent algorithm design to illustrate synchronization issues and techniques for resolving them.
In computer science, the sleeping barber problem is a classic inter-process communication and synchronization problem that illustrates the complexities that arise when there are multiple operating system processes.
In the C++ programming language, the C++ Standard Library is a collection of classes and functions, which are written in the core language and part of the C++ ISO Standard itself.
Resource acquisition is initialization (RAII) is a programming idiom used in several object-oriented, statically typed programming languages to describe a particular language behavior. In RAII, holding a resource is a class invariant, and is tied to object lifetime. Resource allocation is done during object creation, by the constructor, while resource deallocation (release) is done during object destruction, by the destructor. In other words, resource acquisition must succeed for initialization to succeed. Thus the resource is guaranteed to be held between when initialization finishes and finalization starts, and to be held only when the object is alive. Thus if there are no object leaks, there are no resource leaks.
In concurrent programming, a monitor is a synchronization construct that prevents threads from concurrently accessing a shared object's state and allows them to wait for the state to change. They provide a mechanism for threads to temporarily give up exclusive access in order to wait for some condition to be met, before regaining exclusive access and resuming their task. A monitor consists of a mutex (lock) and at least one condition variable. A condition variable is explicitly 'signalled' when the object's state is modified, temporarily passing the mutex to another thread 'waiting' on the conditional variable.
In computer science, the reentrant mutex is a particular type of mutual exclusion (mutex) device that may be locked multiple times by the same process/thread, without causing a deadlock.
In computer science, future, promise, delay, and deferred refer to constructs used for synchronizing program execution in some concurrent programming languages. They describe an object that acts as a proxy for a result that is initially unknown, usually because the computation of its value is not yet complete.
In computer science, a readers–writer is a synchronization primitive that solves one of the readers–writers problems. An RW lock allows concurrent access for read-only operations, whereas write operations require exclusive access. This means that multiple threads can read the data in parallel but an exclusive lock is needed for writing or modifying data. When a writer is writing the data, all other writers and readers will be blocked until the writer is finished writing. A common use might be to control access to a data structure in memory that cannot be updated atomically and is invalid until the update is complete.
In computer science, the readers–writers problems are examples of a common computing problem in concurrency. There are at least three variations of the problems, which deal with situations in which many concurrent threads of execution try to access the same shared resource at one time.
In computer science, synchronization is the task of coordinating multiple of processes to join up or handshake at a certain point, in order to reach an agreement or commit to a certain sequence of action.
In parallel computing, a barrier is a type of synchronization method. A barrier for a group of threads or processes in the source code means any thread/process must stop at this point and cannot proceed until all other threads/processes reach this barrier.
Concurrent Pascal is a programming language designed by Per Brinch Hansen for writing concurrent computing programs such as operating systems and real-time computing monitoring systems on shared memory computers.
select is a system call and application programming interface (API) in Unix-like and POSIX-compliant operating systems for examining the status of file descriptors of open input/output channels. The select system call is similar to the poll facility introduced in UNIX System V and later operating systems. However, with the c10k problem, both select and poll have been superseded by the likes of kqueue, epoll, /dev/poll and I/O completion ports.
Join-patterns provides a way to write concurrent, parallel and distributed computer programs by message passing. Compared to the use of threads and locks, this is a high level programming model using communication constructs model to abstract the complexity of concurrent environment and to allow scalability. Its focus is on the execution of a chord between messages atomically consumed from a group of channels.