Formal statement
Let be a sequence of i.i.d. random variables whose moment generating function is finite for some , and let , with . Then, the process defined by







is a martingale known as Wald's martingale. [4] In particular, for all .
In probability theory, Wald's martingale is the name sometimes given to a martingale used to study sums of i.i.d. random variables. It is named after the mathematician Abraham Wald, who used these ideas in a series of influential publications. [1] [2] [3]
Wald's martingale can be seen as discrete-time equivalent of the Doléans-Dade exponential.
Let be a sequence of i.i.d. random variables whose moment generating function is finite for some , and let , with . Then, the process defined by
is a martingale known as Wald's martingale. [4] In particular, for all .
| | This probability-related article is a stub. You can help Wikipedia by expanding it. |
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.

In mathematics, the Wiener process is a real-valued continuous-time stochastic process named in honor of American mathematician Norbert Wiener for his investigations on the mathematical properties of the one-dimensional Brownian motion. It is often also called Brownian motion due to its historical connection with the physical process of the same name originally observed by Scottish botanist Robert Brown. It is one of the best known Lévy processes and occurs frequently in pure and applied mathematics, economics, quantitative finance, evolutionary biology, and physics.

In probability theory, the law of large numbers (LLN) is a mathematical theorem that states that the average of the results obtained from a large number of independent and identical random samples converges to the true value, if it exists. More formally, the LLN states that given a sample of independent and identically distributed values, the sample mean converges to the true mean.
In numerical analysis and computational statistics, rejection sampling is a basic technique used to generate observations from a distribution. It is also commonly called the acceptance-rejection method or "accept-reject algorithm" and is a type of exact simulation method. The method works for any distribution in with a density.
In probability theory, a Lévy process, named after the French mathematician Paul Lévy, is a stochastic process with independent, stationary increments: it represents the motion of a point whose successive displacements are random, in which displacements in pairwise disjoint time intervals are independent, and displacements in different time intervals of the same length have identical probability distributions. A Lévy process may thus be viewed as the continuous-time analog of a random walk.
In probability theory, Wald's equation, Wald's identity or Wald's lemma is an important identity that simplifies the calculation of the expected value of the sum of a random number of random quantities. In its simplest form, it relates the expectation of a sum of randomly many finite-mean, independent and identically distributed random variables to the expected number of terms in the sum and the random variables' common expectation under the condition that the number of terms in the sum is independent of the summands.
In probability theory, the theory of large deviations concerns the asymptotic behaviour of remote tails of sequences of probability distributions. While some basic ideas of the theory can be traced to Laplace, the formalization started with insurance mathematics, namely ruin theory with Cramér and Lundberg. A unified formalization of large deviation theory was developed in 1966, in a paper by Varadhan. Large deviations theory formalizes the heuristic ideas of concentration of measures and widely generalizes the notion of convergence of probability measures.
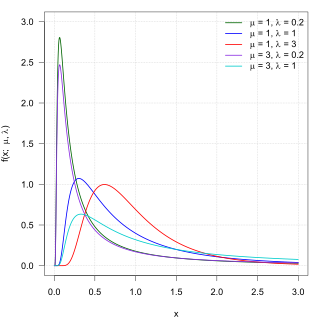
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
In statistics, an exchangeable sequence of random variables is a sequence X1, X2, X3, ... whose joint probability distribution does not change when the positions in the sequence in which finitely many of them appear are altered. In other words, the joint distribution is invariant to finite permutation. Thus, for example the sequences
The sequential probability ratio test (SPRT) is a specific sequential hypothesis test, developed by Abraham Wald and later proven to be optimal by Wald and Jacob Wolfowitz. Neyman and Pearson's 1933 result inspired Wald to reformulate it as a sequential analysis problem. The Neyman-Pearson lemma, by contrast, offers a rule of thumb for when all the data is collected.
Stochastic approximation methods are a family of iterative methods typically used for root-finding problems or for optimization problems. The recursive update rules of stochastic approximation methods can be used, among other things, for solving linear systems when the collected data is corrupted by noise, or for approximating extreme values of functions which cannot be computed directly, but only estimated via noisy observations.
In probability theory, Bernstein inequalities give bounds on the probability that the sum of random variables deviates from its mean. In the simplest case, let X1, ..., Xn be independent Bernoulli random variables taking values +1 and −1 with probability 1/2, then for every positive ,
In statistics, the Chapman–Robbins bound or Hammersley–Chapman–Robbins bound is a lower bound on the variance of estimators of a deterministic parameter. It is a generalization of the Cramér–Rao bound; compared to the Cramér–Rao bound, it is both tighter and applicable to a wider range of problems. However, it is usually more difficult to compute.
In stochastic calculus, the Doléans-Dade exponential or stochastic exponential of a semimartingale X is the unique strong solution of the stochastic differential equation
In statistics, the Khmaladze transformation is a mathematical tool used in constructing convenient goodness of fit tests for hypothetical distribution functions. More precisely, suppose are i.i.d., possibly multi-dimensional, random observations generated from an unknown probability distribution. A classical problem in statistics is to decide how well a given hypothetical distribution function , or a given hypothetical parametric family of distribution functions , fits the set of observations. The Khmaladze transformation allows us to construct goodness of fit tests with desirable properties. It is named after Estate V. Khmaladze.
Minimum-distance estimation (MDE) is a conceptual method for fitting a statistical model to data, usually the empirical distribution. Often-used estimators such as ordinary least squares can be thought of as special cases of minimum-distance estimation.
For certain applications in linear algebra, it is useful to know properties of the probability distribution of the largest eigenvalue of a finite sum of random matrices. Suppose is a finite sequence of random matrices. Analogous to the well-known Chernoff bound for sums of scalars, a bound on the following is sought for a given parameter t:
Exponential Tilting (ET), Exponential Twisting, or Exponential Change of Measure (ECM) is a distribution shifting technique used in many parts of mathematics. The different exponential tiltings of a random variable is known as the natural exponential family of .
In probability, weak dependence of random variables is a generalization of independence that is weaker than the concept of a martingale. A (time) sequence of random variables is weakly dependent if distinct portions of the sequence have a covariance that asymptotically decreases to 0 as the blocks are further separated in time. Weak dependence primarily appears as a technical condition in various probabilistic limit theorems.
In statistical hypothesis testing, e-values quantify the evidence in the data against a null hypothesis. They serve as a more robust alternative to p-values, addressing some shortcomings of the latter.

