Signal-to-noise ratio is a measure used in science and engineering that compares the level of a desired signal to the level of background noise. SNR is defined as the ratio of signal power to noise power, often expressed in decibels. A ratio higher than 1:1 indicates more signal than noise.
Linear elasticity is a mathematical model of how solid objects deform and become internally stressed due to prescribed loading conditions. It is a simplification of the more general nonlinear theory of elasticity and a branch of continuum mechanics.
In control systems, sliding mode control (SMC) is a nonlinear control method that alters the dynamics of a nonlinear system by applying a discontinuous control signal that forces the system to "slide" along a cross-section of the system's normal behavior. The state-feedback control law is not a continuous function of time. Instead, it can switch from one continuous structure to another based on the current position in the state space. Hence, sliding mode control is a variable structure control method. The multiple control structures are designed so that trajectories always move toward an adjacent region with a different control structure, and so the ultimate trajectory will not exist entirely within one control structure. Instead, it will slide along the boundaries of the control structures. The motion of the system as it slides along these boundaries is called a sliding mode and the geometrical locus consisting of the boundaries is called the sliding (hyper)surface. In the context of modern control theory, any variable structure system, like a system under SMC, may be viewed as a special case of a hybrid dynamical system as the system both flows through a continuous state space but also moves through different discrete control modes.
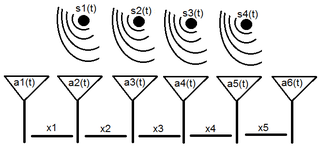
Array processing is a wide area of research in the field of signal processing that extends from the simplest form of 1 dimensional line arrays to 2 and 3 dimensional array geometries. Array structure can be defined as a set of sensors that are spatially separated, e.g. radio antenna and seismic arrays. The sensors used for a specific problem may vary widely, for example microphones, accelerometers and telescopes. However, many similarities exist, the most fundamental of which may be an assumption of wave propagation. Wave propagation means there is a systemic relationship between the signal received on spatially separated sensors. By creating a physical model of the wave propagation, or in machine learning applications a training data set, the relationships between the signals received on spatially separated sensors can be leveraged for many applications.
In statistics, econometrics, and signal processing, an autoregressive (AR) model is a representation of a type of random process; as such, it is used to describe certain time-varying processes in nature, economics, behavior, etc. The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term ; thus the model is in the form of a stochastic difference equation. Together with the moving-average (MA) model, it is a special case and key component of the more general autoregressive–moving-average (ARMA) and autoregressive integrated moving average (ARIMA) models of time series, which have a more complicated stochastic structure; it is also a special case of the vector autoregressive model (VAR), which consists of a system of more than one interlocking stochastic difference equation in more than one evolving random variable.
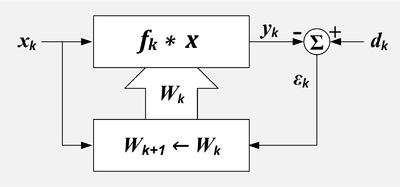
Least mean squares (LMS) algorithms are a class of adaptive filter used to mimic a desired filter by finding the filter coefficients that relate to producing the least mean square of the error signal. It is a stochastic gradient descent method in that the filter is only adapted based on the error at the current time. It was invented in 1960 by Stanford University professor Bernard Widrow and his first Ph.D. student, Ted Hoff.
Recursive least squares (RLS) is an adaptive filter algorithm that recursively finds the coefficients that minimize a weighted linear least squares cost function relating to the input signals. This approach is in contrast to other algorithms such as the least mean squares (LMS) that aim to reduce the mean square error. In the derivation of the RLS, the input signals are considered deterministic, while for the LMS and similar algorithms they are considered stochastic. Compared to most of its competitors, the RLS exhibits extremely fast convergence. However, this benefit comes at the cost of high computational complexity.
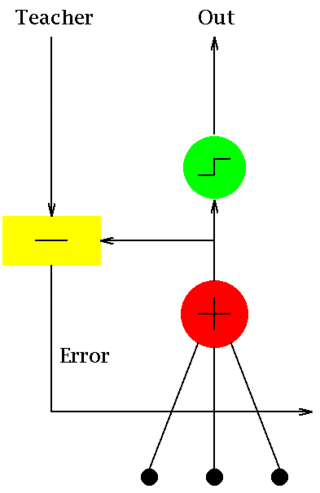
ADALINE is an early single-layer artificial neural network and the name of the physical device that implemented this network. The network uses memistors. It was developed by professor Bernard Widrow and his doctoral student Ted Hoff at Stanford University in 1960. It is based on the perceptron. It consists of a weight, a bias and a summation function.
The multidelay block frequency domain adaptive filter (MDF) algorithm is a block-based frequency domain implementation of the (normalised) Least mean squares filter (LMS) algorithm.
The Least mean squares filter solution converges to the Wiener filter solution, assuming that the unknown system is LTI and the noise is stationary. Both filters can be used to identify the impulse response of an unknown system, knowing only the original input signal and the output of the unknown system. By relaxing the error criterion to reduce current sample error instead of minimizing the total error over all of n, the LMS algorithm can be derived from the Wiener filter.
In the fields of computer vision and image analysis, the Harris affine region detector belongs to the category of feature detection. Feature detection is a preprocessing step of several algorithms that rely on identifying characteristic points or interest points so to make correspondences between images, recognize textures, categorize objects or build panoramas.
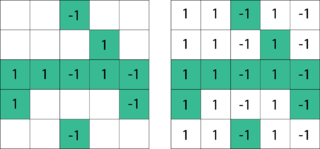
Matrix completion is the task of filling in the missing entries of a partially observed matrix, which is equivalent to performing data imputation in statistics. A wide range of datasets are naturally organized in matrix form. One example is the movie-ratings matrix, as appears in the Netflix problem: Given a ratings matrix in which each entry represents the rating of movie by customer , if customer has watched movie and is otherwise missing, we would like to predict the remaining entries in order to make good recommendations to customers on what to watch next. Another example is the document-term matrix: The frequencies of words used in a collection of documents can be represented as a matrix, where each entry corresponds to the number of times the associated term appears in the indicated document.
A two-dimensional (2D) adaptive filter is very much like a one-dimensional adaptive filter in that it is a linear system whose parameters are adaptively updated throughout the process, according to some optimization approach. The main difference between 1D and 2D adaptive filters is that the former usually take as inputs signals with respect to time, what implies in causality constraints, while the latter handles signals with 2 dimensions, like x-y coordinates in the space domain, which are usually non-causal. Moreover, just like 1D filters, most 2D adaptive filters are digital filters, because of the complex and iterative nature of the algorithms.
The distributional learning theory or learning of probability distribution is a framework in computational learning theory. It has been proposed from Michael Kearns, Yishay Mansour, Dana Ron, Ronitt Rubinfeld, Robert Schapire and Linda Sellie in 1994 and it was inspired from the PAC-framework introduced by Leslie Valiant.
Carrier frequency offset (CFO) is one of many non-ideal conditions that may affect in baseband receiver design. In designing a baseband receiver, we should notice not only the degradation invoked by non-ideal channel and noise, we should also regard RF and analog parts as the main consideration. Those non-idealities include sampling clock offset, IQ imbalance, power amplifier, phase noise and carrier frequency offset nonlinearity.
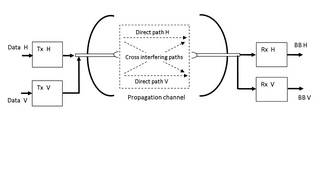
XPIC, or cross-polarization interference cancelling technology, is an algorithm to suppress mutual interference between two received streams in a Polarization-division multiplexing communication system.

Batch normalization is a method used to make training of artificial neural networks faster and more stable through normalization of the layers' inputs by re-centering and re-scaling. It was proposed by Sergey Ioffe and Christian Szegedy in 2015.
Adding controlled noise from predetermined distributions is a way of designing differentially private mechanisms. This technique is useful for designing private mechanisms for real-valued functions on sensitive data. Some commonly used distributions for adding noise include Laplace and Gaussian distributions.
A guided filter is an edge-preserving smoothing image filter. As with a bilateral filter, it can filter out noise or texture while retaining sharp edges.
Adaptive noise cancelling is an unorthodox signal processing technique that is highly effective in suppressing additive interference or noise corrupting a received target signal at the main or primary sensor in certain common situations where the interference is known and is accessible but unavoidable and where the target signal and the interference are unrelated, that is, uncorrelated. Examples of such situations include: