
A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map. Typical standardized semantic networks are expressed as semantic triples.
WordNet is a lexical database of semantic relations between words. WordNet links words into semantic relations including synonyms, hyponyms, and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. WordNet can thus be seen as a combination and extension of a dictionary and thesaurus. While it is accessible to human users via a web browser, its primary use is in automatic text analysis and artificial intelligence applications. WordNet was first created in the English language and the English WordNet database and software tools have been released under a BSD style license and are freely available for download from that WordNet website. There are now WordNets in more than 200 languages.
In computer science and information science, an ontology encompasses a representation, formal naming, and definition of the categories, properties, and relations between the concepts, data, and entities that substantiate one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of concepts and categories that represent the subject.
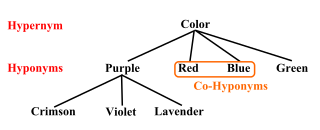
In linguistics, semantics, general semantics, and ontologies, hyponymy is a semantic relation between a hyponym denoting a subtype and a hypernym or hyperonym denoting a supertype. In other words, the semantic field of the hyponym is included within that of the hypernym.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".
In information science, an upper ontology is an ontology which consists of very general terms that are common across all domains. An important function of an upper ontology is to support broad semantic interoperability among a large number of domain-specific ontologies by providing a common starting point for the formulation of definitions. Terms in the domain ontology are ranked under the terms in the upper ontology, e.g., the upper ontology classes are superclasses or supersets of all the classes in the domain ontologies.
In metadata, a synonym ring or synset, is a group of data elements that are considered semantically equivalent for the purposes of information retrieval. These data elements are frequently found in different metadata registries. Although a group of terms can be considered equivalent, metadata registries store the synonyms at a central location called the preferred data element.

A semantic lexicon is a digital dictionary of words labeled with semantic classes so associations can be drawn between words that have not previously been encountered. Semantic lexicons are built upon semantic networks, which represent the semantic relations between words. The difference between a semantic lexicon and a semantic network is that a semantic lexicon has definitions for each word, or a "gloss".
Simple Knowledge Organization System (SKOS) is a W3C recommendation designed for representation of thesauri, classification schemes, taxonomies, subject-heading systems, or any other type of structured controlled vocabulary. SKOS is part of the Semantic Web family of standards built upon RDF and RDFS, and its main objective is to enable easy publication and use of such vocabularies as linked data.
The sequence between semantic related ordered words is classified as a lexical chain. A lexical chain is a sequence of related words in writing, spanning short or long distances. A chain is independent of the grammatical structure of the text and in effect it is a list of words that captures a portion of the cohesive structure of the text. A lexical chain can provide a context for the resolution of an ambiguous term and enable identification of the concept that the term represents.
Ontology learning is the automatic or semi-automatic creation of ontologies, including extracting the corresponding domain's terms and the relationships between the concepts that these terms represent from a corpus of natural language text, and encoding them with an ontology language for easy retrieval. As building ontologies manually is extremely labor-intensive and time-consuming, there is great motivation to automate the process.
In digital lexicography, natural language processing, and digital humanities, a lexical resource is a language resource consisting of data regarding the lexemes of the lexicon of one or more languages e.g., in the form of a database.
A concept search is an automated information retrieval method that is used to search electronically stored unstructured text for information that is conceptually similar to the information provided in a search query. In other words, the ideas expressed in the information retrieved in response to a concept search query are relevant to the ideas contained in the text of the query.
Contemporary ontologies share many structural similarities, regardless of the ontology language in which they are expressed. Most ontologies describe individuals (instances), classes (concepts), attributes, and relations.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
GermaNet is a semantic network for the German language. It relates nouns, verbs, and adjectives semantically by grouping lexical units that express the same concept into synsets and by defining semantic relations between these synsets. GermaNet is free for academic use, after signing a license. GermaNet has much in common with the English WordNet and can be viewed as an on-line thesaurus or a light-weight ontology. GermaNet has been developed and maintained at the University of Tübingen since 1997 within the research group for General and Computational Linguistics. It has been integrated into the EuroWordNet, a multilingual lexical-semantic database.

BabelNet is a multilingual lexicalized semantic network and ontology developed at the NLP group of the Sapienza University of Rome. BabelNet was automatically created by linking Wikipedia to the most popular computational lexicon of the English language, WordNet. The integration is done using an automatic mapping and by filling in lexical gaps in resource-poor languages by using statistical machine translation. The result is an encyclopedic dictionary that provides concepts and named entities lexicalized in many languages and connected with large amounts of semantic relations. Additional lexicalizations and definitions are added by linking to free-license wordnets, OmegaWiki, the English Wiktionary, Wikidata, FrameNet, VerbNet and others. Similarly to WordNet, BabelNet groups words in different languages into sets of synonyms, called Babel synsets. For each Babel synset, BabelNet provides short definitions in many languages harvested from both WordNet and Wikipedia.
plWordNet is a lexico-semantic database of the Polish language. It includes sets of synonymous lexical units (synsets) followed by short definitions. plWordNet serves as a thesaurus-dictionary where concepts (synsets) and individual word meanings are defined by their location in the network of mutual relations, reflecting the lexico-semantic system of the Polish language. plWordNet is also used as one of the basic resources for the construction of natural language processing tools for Polish.
The Bulgarian WordNet (BulNet) is an electronic multilingual dictionary of synonym sets along with their explanatory definitions and sets of semantic relations with other words in the language.
OntoLex is the short name of a vocabulary for lexical resources in the web of data (OntoLex-Lemon) and the short name of the W3C community group that created it.