
Artificial neural networks are a branch of machine learning models that are built using principles of neuronal organization discovered by connectionism in the biological neural networks constituting animal brains.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech to text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.

Jürgen Schmidhuber is a German computer scientist noted for his work in the field of artificial intelligence, specifically artificial neural networks. He is a scientific director of the Dalle Molle Institute for Artificial Intelligence Research in Switzerland. He is also director of the Artificial Intelligence Initiative and professor of the Computer Science program in the Computer, Electrical, and Mathematical Sciences and Engineering (CEMSE) division at the King Abdullah University of Science and Technology (KAUST) in Saudi Arabia.

A recurrent neural network (RNN) is one of the two broad types of artificial neural network, characterized by direction of the flow of information between its layers. In contrast to uni-directional feedforward neural network, it is a bi-directional artificial neural network, meaning that it allows the output from some nodes to affect subsequent input to the same nodes. Their ability to use internal state (memory) to process arbitrary sequences of inputs makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. The term "recurrent neural network" is used to refer to the class of networks with an infinite impulse response, whereas "convolutional neural network" refers to the class of finite impulse response. Both classes of networks exhibit temporal dynamic behavior. A finite impulse recurrent network is a directed acyclic graph that can be unrolled and replaced with a strictly feedforward neural network, while an infinite impulse recurrent network is a directed cyclic graph that can not be unrolled.

An echo state network (ESN) is a type of reservoir computer that uses a recurrent neural network with a sparsely connected hidden layer. The connectivity and weights of hidden neurons are fixed and randomly assigned. The weights of output neurons can be learned so that the network can produce or reproduce specific temporal patterns. The main interest of this network is that although its behaviour is non-linear, the only weights that are modified during training are for the synapses that connect the hidden neurons to output neurons. Thus, the error function is quadratic with respect to the parameter vector and can be differentiated easily to a linear system.

Spiking neural networks (SNNs) are artificial neural networks that more closely mimic natural neural networks. In addition to neuronal and synaptic state, SNNs incorporate the concept of time into their operating model. The idea is that neurons in the SNN do not transmit information at each propagation cycle, but rather transmit information only when a membrane potential – an intrinsic quality of the neuron related to its membrane electrical charge – reaches a specific value, called the threshold. When the membrane potential reaches the threshold, the neuron fires, and generates a signal that travels to other neurons which, in turn, increase or decrease their potentials in response to this signal. A neuron model that fires at the moment of threshold crossing is also called a spiking neuron model.

Long short-term memory (LSTM) network is a recurrent neural network (RNN), aimed to deal with the vanishing gradient problem present in traditional RNNs. Its relative insensitivity to gap length is its advantage over other RNNs, hidden Markov models and other sequence learning methods. It aims to provide a short-term memory for RNN that can last thousands of timesteps, thus "long short-term memory". It is applicable to classification, processing and predicting data based on time series, such as in handwriting, speech recognition, machine translation, speech activity detection, robot control, video games, and healthcare.
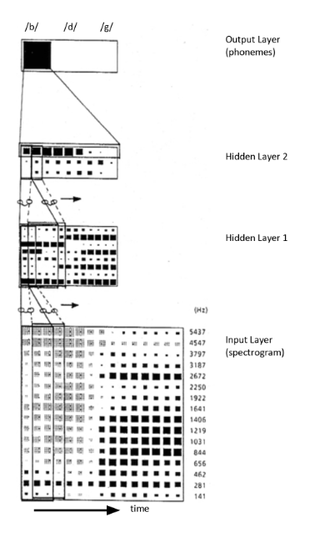
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
There are many types of artificial neural networks (ANN).

Deep learning is part of a broader family of machine learning methods, which is based on artificial neural networks with representation learning. The adjective "deep" in deep learning refers to the use of multiple layers in the network. Methods used can be either supervised, semi-supervised or unsupervised.
In deep learning, a convolutional neural network (CNN) is a class of artificial neural network most commonly applied to analyze visual imagery. CNNs use a mathematical operation called convolution in place of general matrix multiplication in at least one of their layers. They are specifically designed to process pixel data and are used in image recognition and processing. They have applications in:
Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model.
Gated recurrent units (GRUs) are a gating mechanism in recurrent neural networks, introduced in 2014 by Kyunghyun Cho et al. The GRU is like a long short-term memory (LSTM) with a forget gate, but has fewer parameters than LSTM, as it lacks an output gate. GRU's performance on certain tasks of polyphonic music modeling, speech signal modeling and natural language processing was found to be similar to that of LSTM. GRUs showed that gating is indeed helpful in general, and Bengio's team came to no concrete conclusion on which of the two gating units was better.
Connectionist temporal classification (CTC) is a type of neural network output and associated scoring function, for training recurrent neural networks (RNNs) such as LSTM networks to tackle sequence problems where the timing is variable. It can be used for tasks like on-line handwriting recognition or recognizing phonemes in speech audio. CTC refers to the outputs and scoring, and is independent of the underlying neural network structure. It was introduced in 2006.

A Residual Neural Network is a deep learning model in which the weight layers learn residual functions with reference to the layer inputs. A Residual Network is a network with skip connections that perform identity mappings, merged with the layer outputs by addition. It behaves like a Highway Network whose gates are opened through strongly positive bias weights. This enables deep learning models with tens or hundreds of layers to train easily and approach better accuracy when going deeper. The identity skip connections, often referred to as "residual connections", are also used in the 1997 LSTM networks, Transformer models, the AlphaGo Zero system, the AlphaStar system, and the AlphaFold system.

rnn is an open-source machine learning framework that implements recurrent neural network architectures, such as LSTM and GRU, natively in the R programming language, that has been downloaded over 100,000 times.
In video games, various artificial intelligence techniques have been used in a variety of ways, ranging from non-player character (NPC) control to procedural content generation (PCG). Machine learning is a subset of artificial intelligence that focuses on using algorithms and statistical models to make machines act without specific programming. This is in sharp contrast to traditional methods of artificial intelligence such as search trees and expert systems.
A Transformer is a deep learning architecture that relies on the attention mechanism. It is notable for requiring less training time compared to previous recurrent neural architectures, such as long short-term memory (LSTM), and has been prevalently adopted for training large language models on large (language) datasets, such as the Wikipedia Corpus and Common Crawl, by virtue of the parallelized processing of input sequence. More specifically, the model takes in tokenized input tokens, and at each layer, contextualizes each token with other (unmasked) input tokens in parallel via attention mechanism. Though the Transformer model came out in 2017, the core attention mechanism was proposed earlier in 2014 by Bahdanau, Cho, and Bengio for machine translation. This architecture is now used not only in natural language processing, computer vision, but also in audio, and multi-modal processing. It has also led to the development of pre-trained systems, such as generative pre-trained transformers (GPTs) and BERT.
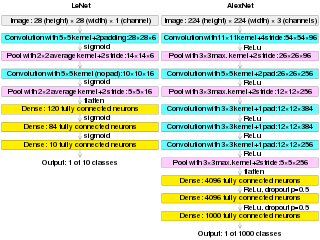
A layer in a deep learning model is a structure or network topology in the model's architecture, which takes information from the previous layers and then passes it to the next layer.
