Corpus linguistics is the study of a language as that language is expressed in its text corpus, its body of "real world" text. Corpus linguistics proposes that a reliable analysis of a language is more feasible with corpora collected in the field—the natural context ("realia") of that language—with minimal experimental interference. The large collections of text allow linguistics to run quantitative analyses on linguistic concepts, otherwise harder to quantify.
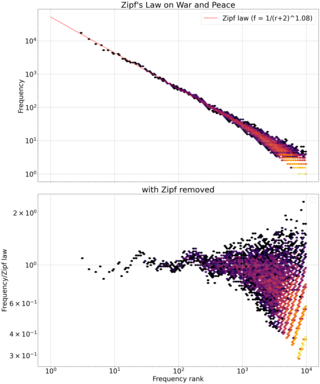
Zipf's law is an empirical law that often holds, approximately, when a list of measured values is sorted in decreasing order. It states that the value of the nth entry is inversely proportional to n.
In linguistics and natural language processing, a corpus or text corpus is a dataset, consisting of natively digital and older, digitalized, language resources, either annotated or unannotated.
Henry Kučera, born Jindřich Kučera, was a Czech-American linguist who pioneered corpus linguistics, linguistic software, a major contributor to the American Heritage Dictionary, and a pioneer in the development of spell checking computer software. He is remembered in particular as one of the initiators of the Brown Corpus.
In probability theory and statistics, the Zipf–Mandelbrot law is a discrete probability distribution. Also known as the Pareto–Zipf law, it is a power-law distribution on ranked data, named after the linguist George Kingsley Zipf who suggested a simpler distribution called Zipf's law, and the mathematician Benoit Mandelbrot, who subsequently generalized it.
In corpus linguistics, part-of-speech tagging, also called grammatical tagging is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition and its context. A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc.
Studies that estimate and rank the most common words in English examine texts written in English. Perhaps the most comprehensive such analysis is one that was conducted against the Oxford English Corpus (OEC), a massive text corpus that is written in the English language.
The British National Corpus (BNC) is a 100-million-word text corpus of samples of written and spoken English from a wide range of sources. The corpus covers British English of the late 20th century from a wide variety of genres, with the intention that it be a representative sample of spoken and written British English of that time. It is used in corpus linguistics for analysis of corpora.
Linguistic categories include
The International Corpus of English (ICE) is a set of text corpora representing varieties of English from around the world. Over twenty countries or groups of countries where English is the first language or an official second language are included.
The Constituent Likelihood Automatic Word-tagging System (CLAWS) is a program that performs part-of-speech tagging. It was developed in the 1980s at Lancaster University by the University Centre for Computer Corpus Research on Language. It has an overall accuracy rate of 96-97% with the latest version (CLAWS4) tagging around 100 million words of the British National Corpus.
The Lancaster-Oslo/Bergen (LOB) Corpus is a one-million-word collection of British English texts which was compiled in the 1970s in collaboration between the University of Lancaster, the University of Oslo, and the Norwegian Computing Centre for the Humanities, Bergen, to provide a British counterpart to the Brown Corpus compiled by Henry Kučera and W. Nelson Francis for American English in the 1960s.
A word list is a list of a language's lexicon within some given text corpus, serving the purpose of vocabulary acquisition. A lexicon sorted by frequency "provides a rational basis for making sure that learners get the best return for their vocabulary learning effort", but is mainly intended for course writers, not directly for learners. Frequency lists are also made for lexicographical purposes, serving as a sort of checklist to ensure that common words are not left out. Some major pitfalls are the corpus content, the corpus register, and the definition of "word". While word counting is a thousand years old, with still gigantic analysis done by hand in the mid-20th century, natural language electronic processing of large corpora such as movie subtitles has accelerated the research field.
Classic monolingual Word Sense Disambiguation evaluation tasks uses WordNet as its sense inventory and is largely based on supervised / semi-supervised classification with the manually sense annotated corpora:
The Spoken English Corpus (SEC) is a speech corpus collection of recordings of spoken British English compiled during 1984–1987. The corpus manual can be found on ICAME.

W. Nelson Francis was an American author, linguist, and university professor. He served as a member of the faculties of Franklin & Marshall College and Brown University, where he specialized in English and corpus linguistics. He is known for his work compiling a text collection entitled the Brown University Standard Corpus of Present-Day American English, which he completed with Henry Kučera.
The International Computer Archive of Modern and Medieval English (ICAME) is an international group of linguists and data scientists working in corpus linguistics to digitise English texts. The organisation was founded in Oslo, Norway in 1977 as the International Computer Archive of Modern English, before being renamed to its current title.
The Bulgarian Sense-annotated Corpus (BulSemCor) is a structured corpus of Bulgarian texts in which each lexical item is assigned a sense tag. BulSemCor was created by the Department of Computational Linguistics at the Institute for Bulgarian Language of the Bulgarian Academy of Sciences.
The Bulgarian National Corpus (BulNC) is a large representative corpus of Bulgarian comprising about 200,000 texts and amounting to over 1 billion words.
The Czech National Corpus (CNC) is a large electronic corpus of written and spoken Czech language, developed by the Institute of the Czech National Corpus (ICNC) in the Faculty of Arts at Charles University in Prague. The collection is used for teaching and research in corpus linguistics. The ICNC collaborates with over 200 researchers and students, 270 publishers, and other similar research projects.
