
In genetics, complementary DNA (cDNA) is DNA that was reverse transcribed from an RNA. cDNA exists in both single-stranded and double-stranded forms and in both natural and engineered forms.

In molecular biology, messenger ribonucleic acid (mRNA) is a single-stranded molecule of RNA that corresponds to the genetic sequence of a gene, and is read by a ribosome in the process of synthesizing a protein.

A primer is a short, single-stranded nucleic acid used by all living organisms in the initiation of DNA synthesis. A synthetic primer may also be referred to as an oligo, short for oligonucleotide. DNA polymerase enzymes are only capable of adding nucleotides to the 3’-end of an existing nucleic acid, requiring a primer be bound to the template before DNA polymerase can begin a complementary strand. DNA polymerase adds nucleotides after binding to the RNA primer and synthesizes the whole strand. Later, the RNA strands must be removed accurately and replace them with DNA nucleotides forming a gap region known as a nick that is filled in using an enzyme called ligase. The removal process of the RNA primer requires several enzymes, such as Fen1, Lig1, and others that work in coordination with DNA polymerase, to ensure the removal of the RNA nucleotides and the addition of DNA nucleotides. Living organisms use solely RNA primers, while laboratory techniques in biochemistry and molecular biology that require in vitro DNA synthesis usually use DNA primers, since they are more temperature stable. Primers can be designed in laboratory for specific reactions such as polymerase chain reaction (PCR). When designing PCR primers, there are specific measures that must be taken into consideration, like the melting temperature of the primers and the annealing temperature of the reaction itself. Moreover, the DNA binding sequence of the primer in vitro has to be specifically chosen, which is done using a method called basic local alignment search tool (BLAST) that scans the DNA and finds specific and unique regions for the primer to bind.

Protein biosynthesis is a core biological process, occurring inside cells, balancing the loss of cellular proteins through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.

A reverse transcriptase (RT) is an enzyme used to convert RNA genome to DNA, a process termed reverse transcription. Reverse transcriptases are used by viruses such as HIV and hepatitis B to replicate their genomes, by retrotransposon mobile genetic elements to proliferate within the host genome, and by eukaryotic cells to extend the telomeres at the ends of their linear chromosomes. Contrary to a widely held belief, the process does not violate the flows of genetic information as described by the classical central dogma, as transfers of information from RNA to DNA are explicitly held possible.

DNA synthesis is the natural or artificial creation of deoxyribonucleic acid (DNA) molecules. DNA is a macromolecule made up of nucleotide units, which are linked by covalent bonds and hydrogen bonds, in a repeating structure. DNA synthesis occurs when these nucleotide units are joined to form DNA; this can occur artificially or naturally. Nucleotide units are made up of a nitrogenous base, pentose sugar (deoxyribose) and phosphate group. Each unit is joined when a covalent bond forms between its phosphate group and the pentose sugar of the next nucleotide, forming a sugar-phosphate backbone. DNA is a complementary, double stranded structure as specific base pairing occurs naturally when hydrogen bonds form between the nucleotide bases.

Okazaki fragments are short sequences of DNA nucleotides which are synthesized discontinuously and later linked together by the enzyme DNA ligase to create the lagging strand during DNA replication. They were discovered in the 1960s by the Japanese molecular biologists Reiji and Tsuneko Okazaki, along with the help of some of their colleagues.
Polyadenylation is the addition of a poly(A) tail to an RNA transcript, typically a messenger RNA (mRNA). The poly(A) tail consists of multiple adenosine monophosphates; in other words, it is a stretch of RNA that has only adenine bases. In eukaryotes, polyadenylation is part of the process that produces mature mRNA for translation. In many bacteria, the poly(A) tail promotes degradation of the mRNA. It, therefore, forms part of the larger process of gene expression.

A primary transcript is the single-stranded ribonucleic acid (RNA) product synthesized by transcription of DNA, and processed to yield various mature RNA products such as mRNAs, tRNAs, and rRNAs. The primary transcripts designated to be mRNAs are modified in preparation for translation. For example, a precursor mRNA (pre-mRNA) is a type of primary transcript that becomes a messenger RNA (mRNA) after processing.
Rapid amplification of cDNA ends (RACE) is a technique used in molecular biology to obtain the full length sequence of an RNA transcript found within a cell. RACE results in the production of a cDNA copy of the RNA sequence of interest, produced through reverse transcription, followed by PCR amplification of the cDNA copies. The amplified cDNA copies are then sequenced and, if long enough, should map to a unique genomic region. RACE is commonly followed up by cloning before sequencing of what was originally individual RNA molecules. A more high-throughput alternative which is useful for identification of novel transcript structures, is to sequence the RACE-products by next generation sequencing technologies.
This is a list of topics in molecular biology. See also index of biochemistry articles.
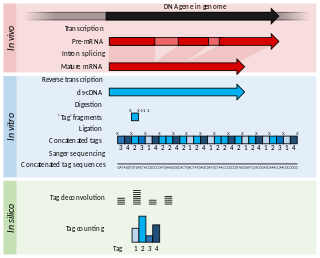
Serial Analysis of Gene Expression (SAGE) is a transcriptomic technique used by molecular biologists to produce a snapshot of the messenger RNA population in a sample of interest in the form of small tags that correspond to fragments of those transcripts. Several variants have been developed since, most notably a more robust version, LongSAGE, RL-SAGE and the most recent SuperSAGE. Many of these have improved the technique with the capture of longer tags, enabling more confident identification of a source gene.

Transcriptional modification or co-transcriptional modification is a set of biological processes common to most eukaryotic cells by which an RNA primary transcript is chemically altered following transcription from a gene to produce a mature, functional RNA molecule that can then leave the nucleus and perform any of a variety of different functions in the cell. There are many types of post-transcriptional modifications achieved through a diverse class of molecular mechanisms.
Exon shuffling is a molecular mechanism for the formation of new genes. It is a process through which two or more exons from different genes can be brought together ectopically, or the same exon can be duplicated, to create a new exon-intron structure. There are different mechanisms through which exon shuffling occurs: transposon mediated exon shuffling, crossover during sexual recombination of parental genomes and illegitimate recombination.
The versatility of polymerase chain reaction (PCR) has led to modifications of the basic protocol being used in a large number of variant techniques designed for various purposes. This article summarizes many of the most common variations currently or formerly used in molecular biology laboratories; familiarity with the fundamental premise by which PCR works and corresponding terms and concepts is necessary for understanding these variant techniques.
Numerous key discoveries in biology have emerged from studies of RNA, including seminal work in the fields of biochemistry, genetics, microbiology, molecular biology, molecular evolution, and structural biology. As of 2010, 30 scientists have been awarded Nobel Prizes for experimental work that includes studies of RNA. Specific discoveries of high biological significance are discussed in this article.

Illumina dye sequencing is a technique used to determine the series of base pairs in DNA, also known as DNA sequencing. The reversible terminated chemistry concept was invented by Bruno Canard and Simon Sarfati at the Pasteur Institute in Paris. It was developed by Shankar Balasubramanian and David Klenerman of Cambridge University, who subsequently founded Solexa, a company later acquired by Illumina. This sequencing method is based on reversible dye-terminators that enable the identification of single nucleotides as they are washed over DNA strands. It can also be used for whole-genome and region sequencing, transcriptome analysis, metagenomics, small RNA discovery, methylation profiling, and genome-wide protein-nucleic acid interaction analysis.
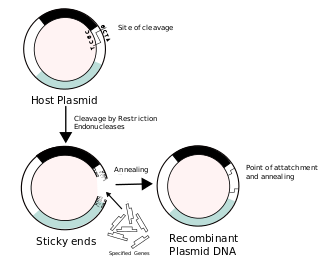
Recombinant DNA (rDNA), or molecular cloning, is the process by which a single gene, or segment of DNA, is isolated and amplified. Recombinant DNA is also known as in vitro recombination. A cloning vector is a DNA molecule that carries foreign DNA into a host cell, where it replicates, producing many copies of itself along with the foreign DNA. There are many types of cloning vectors such as plasmids and phages. In order to carry out recombination between vector and the foreign DNA, it is necessary the vector and DNA to be cloned by digestion, ligase the foreign DNA into the vector with the enzyme DNA ligase. And DNA is inserted by introducing the DNA into bacteria cells by transformation.
G&T-seq is a novel form of single cell sequencing technique allowing one to simultaneously obtain both transcriptomic and genomic data from single cells, allowing for direct comparison of gene expression data to its corresponding genomic data in the same cell...
This glossary of cellular and molecular biology is a list of definitions of terms and concepts commonly used in the study of cell biology, molecular biology, and related disciplines, including molecular genetics, biochemistry, and microbiology. It is split across two articles:
