Related Research Articles

Character encoding is the process of assigning numbers to graphical characters, especially the written characters of human language, allowing them to be stored, transmitted, and transformed using digital computers. The numerical values that make up a character encoding are known as "code points" and collectively comprise a "code space", a "code page", or a "character map".
In computer science, an integer is a datum of integral data type, a data type that represents some range of mathematical integers. Integral data types may be of different sizes and may or may not be allowed to contain negative values. Integers are commonly represented in a computer as a group of binary digits (bits). The size of the grouping varies so the set of integer sizes available varies between different types of computers. Computer hardware nearly always provides a way to represent a processor register or memory address as an integer.
The octal numeral system, or oct for short, is the base-8 number system, and uses the digits 0 to 7, that is to say 10 represents 8 in decimal and 100 represents 64 in decimal. However, English uses a base-10 number language system, hence a true octal system might use different language to avoid confusion with the decimal system.

In computer programming, a string is traditionally a sequence of characters, either as a literal constant or as some kind of variable. The latter may allow its elements to be mutated and the length changed, or it may be fixed. A string is generally considered as a data type and is often implemented as an array data structure of bytes that stores a sequence of elements, typically characters, using some character encoding. String may also denote more general arrays or other sequence data types and structures.
In computing, serialization or serialisation is the process of translating a data structure or object state into a format that can be stored or transmitted and reconstructed later. When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object. For many complex objects, such as those that make extensive use of references, this process is not straightforward. Serialization of object-oriented objects does not include any of their associated methods with which they were previously linked.
UTF-8 is a variable-width character encoding used for electronic communication. Defined by the Unicode Standard, the name is derived from UnicodeTransformation Format – 8-bit.

UTF-16 (16-bit Unicode Transformation Format) is a character encoding capable of encoding all 1,112,064 valid character code points of Unicode (in fact this number of code points is dictated by the design of UTF-16). The encoding is variable-length, as code points are encoded with one or two 16-bit code units. UTF-16 arose from an earlier obsolete fixed-width 16-bit encoding, now known as UCS-2 (for 2-byte Universal Character Set), once it became clear that more than 216 (65,536) code points were needed.
A computer number format is the internal representation of numeric values in digital device hardware and software, such as in programmable computers and calculators. Numerical values are stored as groupings of bits, such as bytes and words. The encoding between numerical values and bit patterns is chosen for convenience of the operation of the computer; the encoding used by the computer's instruction set generally requires conversion for external use, such as for printing and display. Different types of processors may have different internal representations of numerical values and different conventions are used for integer and real numbers. Most calculations are carried out with number formats that fit into a processor register, but some software systems allow representation of arbitrarily large numbers using multiple words of memory.
In computer science, an escape sequence is a combination of characters that has a meaning other than the literal characters contained therein; it is marked by one or more preceding characters.

Abstract Syntax Notation One (ASN.1) is a standard interface description language for defining data structures that can be serialized and deserialized in a cross-platform way. It is broadly used in telecommunications and computer networking, and especially in cryptography.
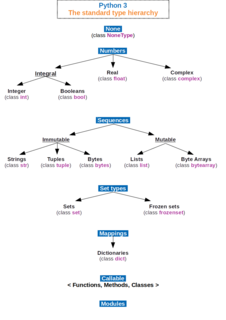
In computer science and computer programming, a data type or simply type is an attribute of data which tells the compiler or interpreter how the programmer intends to use the data. Most programming languages support basic data types of integer numbers, floating-point numbers, characters and Booleans. A data type constrains the values that an expression, such as a variable or a function, might take. This data type defines the operations that can be done on the data, the meaning of the data, and the way values of that type can be stored. A data type provides a set of values from which an expression may take its values.
A string literal or anonymous string is a type of literal for the representation of a string value in the source code of a computer program. In modern programming languages, this is usually a quoted sequence of characters, as in x = "foo", where "foo" is a string literal with value foo – the quotes are not part of the value, and one must use a method such as escape sequences to avoid the problem of delimiter collision and allow the delimiters themselves to be embedded in a string. However, there are numerous alternate notations for specifying string literals, particularly more complicated cases, and the exact notation depends on the individual programming language in question. Nevertheless, there are general guidelines that most modern programming languages follow.

Newline is a control character or sequence of control characters in a character encoding specification that is used to signify the end of a line of text and the start of a new one, e.g., Line Feed (LF) in Unix. Some text editors set this special character when pressing the ↵ Enter key.
In computer science, primitive data type is either of the following:
The null character is a control character with the value zero. It is present in many character sets, including those defined by the Baudot and ITA2 codes, ISO/IEC 646, the C0 control code, the Universal Coded Character Set, and EBCDIC. It is available in nearly all mainstream programming languages. It is often abbreviated as NUL (or NULL though in some contexts that term is used for the null pointer. In 8-bit codes, it is known as a null byte.
uuencoding is a form of binary-to-text encoding that originated in the Unix programs uuencode and uudecode written by Mary Ann Horton at UC Berkeley in 1980, for encoding binary data for transmission in email systems.
In computer science, type conversion, type casting, type coercion, and type juggling are different ways of changing an expression from one data type to another. An example would be the conversion of an integer value into a floating point value or its textual representation as a string, and vice versa. Type conversions can take advantage of certain features of type hierarchies or data representations. Two important aspects of a type conversion are whether it happens implicitly (automatically) or explicitly, and whether the underlying data representation is converted from one representation into another, or a given representation is merely reinterpreted as the representation of another data type. In general, both primitive and compound data types can be converted.
A wide character is a computer character datatype that generally has a size greater than the traditional 8-bit character. The increased datatype size allows for the use of larger coded character sets.
Bencode is the encoding used by the peer-to-peer file sharing system BitTorrent for storing and transmitting loosely structured data.
Escape sequences are used in the programming languages C and C++, and their design was copied in many other languages such as Java, PHP, C#, etc. An escape sequence is a sequence of characters that does not represent itself when used inside a character or string literal, but is translated into another character or a sequence of characters that may be difficult or impossible to represent directly.
References
- ↑ "Primitive Data Types (The Java™ Tutorials > Learning the Java Language > Language Basics)". docs.oracle.com. Retrieved 2016-09-24.
- ↑ "Data Type Summary (Visual Basic)". msdn.microsoft.com. Retrieved 2016-09-24.
- ↑ "5. Built-in Types — Python 2.7.12 documentation". docs.python.org. Retrieved 2016-09-24.
- ↑ "PHP: Types - Manual". php.net. Retrieved 2016-09-24.