Related Research Articles

Cyc is a long-term artificial intelligence project that aims to assemble a comprehensive ontology and knowledge base that spans the basic concepts and rules about how the world works. Hoping to capture common sense knowledge, Cyc focuses on implicit knowledge that other AI platforms may take for granted. This is contrasted with facts one might find somewhere on the internet or retrieve via a search engine or Wikipedia. Cyc enables semantic reasoners to perform human-like reasoning and be less "brittle" when confronted with novel situations.
Knowledge representation and reasoning is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can use to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language. Knowledge representation incorporates findings from psychology about how humans solve problems and represent knowledge, in order to design formalisms that will make complex systems easier to design and build. Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts, data, or entities that pertain to one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of terms and relational expressions that represent the entities in that subject area. The field which studies ontologies so conceived is sometimes referred to as applied ontology.
Open Mind Common Sense (OMCS) is an artificial intelligence project based at the Massachusetts Institute of Technology (MIT) Media Lab whose goal is to build and utilize a large commonsense knowledge base from the contributions of many thousands of people across the Web. It has been active from 1999 to 2016.
An annotation is extra information associated with a particular point in a document or other piece of information. It can be a note that includes a comment or explanation. Annotations are sometimes presented in the margin of book pages. For annotations of different digital media, see web annotation and text annotation.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".
A semantic wiki is a wiki that has an underlying model of the knowledge described in its pages. Regular, or syntactic, wikis have structured text and untyped hyperlinks. Semantic wikis, on the other hand, provide the ability to capture or identify information about the data within pages, and the relationships between pages, in ways that can be queried or exported like a database through semantic queries.
Ontotext is a software company with offices in Europe and USA. It is the semantic technology branch of Sirma Group. Its main domain of activity is the development of software based on the Semantic Web languages and standards, in particular RDF, OWL and SPARQL. Ontotext is best known for the Ontotext GraphDB semantic graph database engine. Another major business line is the development of enterprise knowledge management and analytics systems that involve big knowledge graphs. Those systems are developed on top of the Ontotext Platform that builds on top of GraphDB capabilities for text mining using big knowledge graphs.
A relationship extraction task requires the detection and classification of semantic relationship mentions within a set of artifacts, typically from text or XML documents. The task is very similar to that of information extraction (IE), but IE additionally requires the removal of repeated relations (disambiguation) and generally refers to the extraction of many different relationships.
DBpedia is a project aiming to extract structured content from the information created in the Wikipedia project. This structured information is made available on the World Wide Web using OpenLink Virtuoso. DBpedia allows users to semantically query relationships and properties of Wikipedia resources, including links to other related datasets.
Amit Sheth is a computer scientist at University of South Carolina in Columbia, South Carolina. He is the founding Director of the Artificial Intelligence Institute, and a Professor of Computer Science and Engineering. From 2007 to June 2019, he was the Lexis Nexis Ohio Eminent Scholar, director of the Ohio Center of Excellence in Knowledge-enabled Computing, and a Professor of Computer Science at Wright State University. Sheth's work has been cited by over 48,800 publications. He has an h-index of 117, which puts him among the top 100 computer scientists with the highest h-index. Prior to founding the Kno.e.sis Center, he served as the director of the Large Scale Distributed Information Systems Lab at the University of Georgia in Athens, Georgia.
Freebase was a large collaborative knowledge base consisting of data composed mainly by its community members. It was an online collection of structured data harvested from many sources, including individual, user-submitted wiki contributions. Freebase aimed to create a global resource that allowed people to access common information more effectively. It was developed by the American software company Metaweb and run publicly beginning in March 2007. Metaweb was acquired by Google in a private sale announced on 16 July 2010. Google's Knowledge Graph is powered in part by Freebase.

YAGO is an open source knowledge base developed at the Max Planck Institute for Informatics in Saarbrücken. It is automatically extracted from Wikidata and Schema.org.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.

In natural language processing, entity linking, also referred to as named-entity linking (NEL), named-entity disambiguation (NED), named-entity recognition and disambiguation (NERD) or named-entity normalization (NEN) is the task of assigning a unique identity to entities mentioned in text. For example, given the sentence "Paris is the capital of France", the idea is to determine that "Paris" refers to the city of Paris and not to Paris Hilton or any other entity that could be referred to as "Paris". Entity linking is different from named-entity recognition (NER) in that NER identifies the occurrence of a named entity in text but it does not identify which specific entity it is.

UMBEL is a logically organized knowledge graph of 34,000 concepts and entity types that can be used in information science for relating information from disparate sources to one another. It was retired at the end of 2019. UMBEL was first released in July 2008. Version 1.00 was released in February 2011. Its current release is version 1.50.
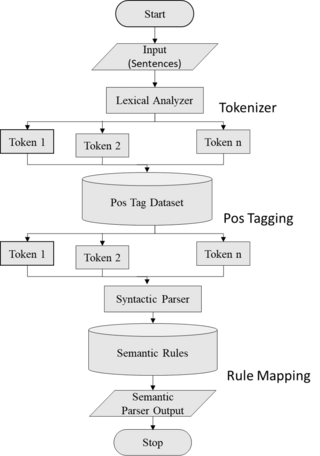
Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.

In knowledge representation and reasoning, a knowledge graph is a knowledge base that uses a graph-structured data model or topology to represent and operate on data. Knowledge graphs are often used to store interlinked descriptions of entities – objects, events, situations or abstract concepts – while also encoding the free-form semantics or relationships underlying these entities.

Jens Lehmann is a computer scientist, who works with knowledge graphs and artificial intelligence. He is a principal scientist at Amazon, an honorary professor at TU Dresden and a fellow of European Laboratory for Learning and Intelligent Systems. Formerly, he was a full professor at the University of Bonn, Germany and lead scientist for Conversational AI and Knowledge Graphs at Fraunhofer IAIS.
References
- ↑ Kotis, K.I., Vouros, G.A. and Spiliotopoulos, D., 2020. Ontology engineering methodologies for the evolution of living and reused ontologies: status, trends, findings and recommendations. The Knowledge Engineering Review, 35.
- ↑ Fathalla, S., Auer, S. and Lange, C., 2020, March. Towards the semantic formalization of science. In Proceedings of the 35th Annual ACM Symposium on Applied Computing (pp. 2057-2059).
- ↑ "Press Release - Springer Nature". 5 January 2020. Retrieved 2020-01-10.
- ↑ "Last version of CSO". 6 July 2020. Retrieved 2020-07-06.
- ↑ Salatino, A.A., Thanapalasingam, T., Mannocci, A., Birukou, A., Osborne, F. and Motta, E. (2019) The Computer Science Ontology: A Comprehensive Automatically-Generated Taxonomy of Research Areas, Data Intelligence.
- ↑ "The CSO Portal" . Retrieved 4 January 2020.
- ↑ Zhang, X., Chandrasegaran, S. and Ma, K.L., 2020. ConceptScope: Organizing and Visualizing Knowledge in Documents based on Domain Ontology. arXiv preprint arXiv:2003.05108.
- ↑ "The CSO Classifier" . Retrieved 4 January 2020.
- ↑ Iana, A., Jung, S., Naeser, P., Birukou, A., Hertling, S. and Paulheim, H., 2019, September. Building a conference recommender system based on SciGraph and WikiCFP. In International Conference on Semantic Systems (pp. 117-123). Springer, Cham.
- ↑ Supriyati, E., Iqbal, M. and Khotimah, T., 2019. Using similarity degrees to improve fuzzy mining association rule based model for analysing IT entrepreneurial tendency. IIUM Engineering Journal, 20(2), pp.78-89.
- ↑ Borges, M.V.M., dos Reis, J.C. and Gribeler, G.P., 2019, June. Empirical Analysis of Semantic Metadata Extraction from Video Lecture Subtitles. In 2019 IEEE 28th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE) (pp. 301-306). IEEE.
- ↑ Zhang, X., Chandrasegaran, S. and Ma, K.L., 2020. ConceptScope: Organizing and Visualizing Knowledge in Documents based on Domain Ontology. arXiv preprint arXiv:2003.05108.