In a blind or blinded experiment, information which may influence the participants of the experiment is withheld until after the experiment is complete. Good blinding can reduce or eliminate experimental biases that arise from a participants' expectations, observer's effect on the participants, observer bias, confirmation bias, and other sources. A blind can be imposed on any participant of an experiment, including subjects, researchers, technicians, data analysts, and evaluators. In some cases, while blinding would be useful, it is impossible or unethical. For example, it is not possible to blind a patient to their treatment in a physical therapy intervention. A good clinical protocol ensures that blinding is as effective as possible within ethical and practical constraints.
Text mining, text data mining (TDM) or text analytics is the process of deriving high-quality information from text. It involves "the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources." Written resources may include websites, books, emails, reviews, and articles. High-quality information is typically obtained by devising patterns and trends by means such as statistical pattern learning. According to Hotho et al. (2005) we can distinguish between three different perspectives of text mining: information extraction, data mining, and a knowledge discovery in databases (KDD) process. Text mining usually involves the process of structuring the input text, deriving patterns within the structured data, and finally evaluation and interpretation of the output. 'High quality' in text mining usually refers to some combination of relevance, novelty, and interest. Typical text mining tasks include text categorization, text clustering, concept/entity extraction, production of granular taxonomies, sentiment analysis, document summarization, and entity relation modeling.

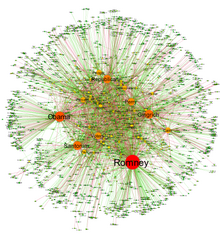
Social network analysis (SNA) is the process of investigating social structures through the use of networks and graph theory. It characterizes networked structures in terms of nodes and the ties, edges, or links that connect them. Examples of social structures commonly visualized through social network analysis include social media networks, meme spread, information circulation, friendship and acquaintance networks, peer learner networks, business networks, knowledge networks, difficult working relationships, collaboration graphs, kinship, disease transmission, and sexual relationships. These networks are often visualized through sociograms in which nodes are represented as points and ties are represented as lines. These visualizations provide a means of qualitatively assessing networks by varying the visual representation of their nodes and edges to reflect attributes of interest.
The branches of science known informally as omics are various disciplines in biology whose names end in the suffix -omics, such as genomics, proteomics, metabolomics, metagenomics, phenomics and transcriptomics. Omics aims at the collective characterization and quantification of pools of biological molecules that translate into the structure, function, and dynamics of an organism or organisms.

Peter Norvig is an American computer scientist and Distinguished Education Fellow at the Stanford Institute for Human-Centered AI. He previously served as a director of research and search quality at Google. Norvig is the co-author with Stuart J. Russell of the most popular textbook in the field of AI: Artificial Intelligence: A Modern Approach used in more than 1,500 universities in 135 countries.

Sauropodomorpha is an extinct clade of long-necked, herbivorous, saurischian dinosaurs that includes the sauropods and their ancestral relatives. Sauropods generally grew to very large sizes, had long necks and tails, were quadrupedal, and became the largest animals to ever walk the Earth. The prosauropods, which preceded the sauropods, were smaller and were often able to walk on two legs. The sauropodomorphs were the dominant terrestrial herbivores throughout much of the Mesozoic Era, from their origins in the Late Triassic until their decline and extinction at the end of the Cretaceous.
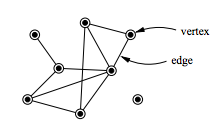
In mathematics, computer science and network science, network theory is a part of graph theory. It defines networks as graphs where the nodes or edges possess attributes. Network theory analyses these networks over the symmetric relations or asymmetric relations between their (discrete) components.
Alan R. Templeton is an American geneticist and statistician at Washington University in St. Louis, where he is the Charles Rebstock emeritus professor of biology. From 2010 to 2019, he held positions in the Institute of Evolution and the Department of Evolutionary and Environmental Biology at the University of Haifa. He is known for his work demonstrating the degree of genetic diversity among humans and, in his opinion, the biological unreality of human races.

Computational sociology is a branch of sociology that uses computationally intensive methods to analyze and model social phenomena. Using computer simulations, artificial intelligence, complex statistical methods, and analytic approaches like social network analysis, computational sociology develops and tests theories of complex social processes through bottom-up modeling of social interactions.
Dale Hollis Hoiberg is a sinologist and has been the editor-in-chief of the Encyclopædia Britannica since 1997. He holds a PhD degree in Chinese literature and began to work for Encyclopædia Britannica as an index editor in 1978. In 2010, Hoiberg co-authored a paper with Harvard researchers Jean-Baptiste Michel and Erez Lieberman Aiden entitled "Quantitative Analysis of Culture Using Millions of Digitized Books". The paper was the first to describe the term culturomics.
Digital broadcasting is the practice of using digital signals rather than analogue signals for broadcasting over radio frequency bands. Digital television broadcasting is widespread. Digital audio broadcasting is being adopted more slowly for radio broadcasting where it is mainly used in Satellite radio.

Laurasiatheria is a superorder of placental mammals that groups together true insectivores (eulipotyphlans), bats (chiropterans), carnivorans, pangolins (pholidotes), even-toed ungulates (artiodactyls), odd-toed ungulates (perissodactyls), and all their extinct relatives. From systematics and phylogenetic perspectives, it is subdivided into order Eulipotyphla and clade Scrotifera. It is a sister group to Euarchontoglires with which it forms the magnorder Boreoeutheria. Laurasiatheria was discovered on the basis of the similar gene sequences shared by the mammals belonging to it; no anatomical features have yet been found that unite the group, although a few have been suggested such as a small coracoid process, a simplified hindgut and allantoic vessels that are large to moderate in size. The Laurasiatheria clade is based on DNA sequence analyses and retrotransposon presence/absence data. The superorder originated on the northern supercontinent of Laurasia, after it split from Gondwana when Pangaea broke up. Its last common ancestor is supposed to have lived between ca. 76 to 90 million years ago.

Atlantogenata is a proposed clade of placental mammals containing the cohorts or superorders Xenarthra and Afrotheria. These groups originated and radiated in the South American and African continents, respectively, presumably in the Cretaceous. Together with Boreoeutheria, they make up Eutheria. The monophyly of this grouping was supported by some genetic evidence.
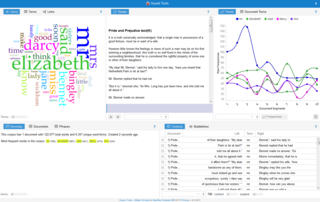
Digital humanities (DH) is an area of scholarly activity at the intersection of computing or digital technologies and the disciplines of the humanities. It includes the systematic use of digital resources in the humanities, as well as the analysis of their application. DH can be defined as new ways of doing scholarship that involve collaborative, transdisciplinary, and computationally engaged research, teaching, and publishing. It brings digital tools and methods to the study of the humanities with the recognition that the printed word is no longer the main medium for knowledge production and distribution.
Google Trends is a website by Google that analyzes the popularity of top search queries in Google Search across various regions and languages. The website uses graphs to compare the search volume of different queries over time.
Cliodynamics is a transdisciplinary area of research that integrates cultural evolution, economic history/cliometrics, macrosociology, the mathematical modeling of historical processes during the longue durée, and the construction and analysis of historical databases.

Erez Lieberman Aiden is an American research scientist active in multiple fields related to applied mathematics. He is an associate professor at the Baylor College of Medicine, and formerly a fellow at the Harvard Society of Fellows and visiting faculty member at Google. He is an adjunct assistant professor of computer science at Rice University. Using mathematical and computational approaches, he has studied evolution in a range of contexts, including that of networks through evolutionary graph theory and languages in the field of culturomics. He has published scientific articles in a variety of disciplines.
Infoveillance is a type of syndromic surveillance that specifically utilizes information found online. The term, along with the term infodemiology, was coined by Gunther Eysenbach to describe research that uses online information to gather information about human behavior.

The Google Ngram Viewer or Google Books Ngram Viewer is an online search engine that charts the frequencies of any set of search strings using a yearly count of n-grams found in printed sources published between 1500 and 2019 in Google's text corpora in English, Chinese (simplified), French, German, Hebrew, Italian, Russian, or Spanish. There are also some specialized English corpora, such as American English, British English, and English Fiction.
Computational social science is the academic sub-discipline concerned with computational approaches to the social sciences. This means that computers are used to model, simulate, and analyze social phenomena. Fields include computational economics, computational sociology, cliodynamics, culturomics, nonprofit studies, and the automated analysis of contents, in social and traditional media. It focuses on investigating social and behavioral relationships and interactions through social simulation, modeling, network analysis, and media analysis.