In statistics and probability theory, the median is the value separating the higher half from the lower half of a data sample, a population, or a probability distribution. For a data set, it may be thought of as "the middle" value. The basic feature of the median in describing data compared to the mean is that it is not skewed by a small proportion of extremely large or small values, and therefore provides a better representation of the center. Median income, for example, may be a better way to describe center of the income distribution because increases in the largest incomes alone have no effect on median. For this reason, the median is of central importance in robust statistics.

In machine learning, support vector machines are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vladimir Vapnik with colleagues SVMs are one of the most robust prediction methods, being based on statistical learning frameworks or VC theory proposed by Vapnik and Chervonenkis (1974). Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier. SVM maps training examples to points in space so as to maximise the width of the gap between the two categories. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.

Principal component analysis (PCA) is a popular technique for analyzing large datasets containing a high number of dimensions/features per observation, increasing the interpretability of data while preserving the maximum amount of information, and enabling the visualization of multidimensional data. Formally, PCA is a statistical technique for reducing the dimensionality of a dataset. This is accomplished by linearly transforming the data into a new coordinate system where the variation in the data can be described with fewer dimensions than the initial data. Many studies use the first two principal components in order to plot the data in two dimensions and to visually identify clusters of closely related data points. Principal component analysis has applications in many fields such as population genetics, microbiome studies, and atmospheric science.
In mathematics, given a non-empty set of objects of finite extension in -dimensional space, for example a set of points, a bounding sphere, enclosing sphere or enclosing ball for that set is an -dimensional solid sphere containing all of these objects.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. k-d trees are a useful data structure for several applications, such as searches involving a multidimensional search key and creating point clouds. k-d trees are a special case of binary space partitioning trees.
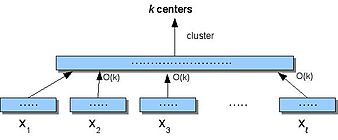
k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells. k-means clustering minimizes within-cluster variances, but not regular Euclidean distances, which would be the more difficult Weber problem: the mean optimizes squared errors, whereas only the geometric median minimizes Euclidean distances. For instance, better Euclidean solutions can be found using k-medians and k-medoids.
Medoids are representative objects of a data set or a cluster within a data set whose sum of dissimilarities to all the objects in the cluster is minimal. Medoids are similar in concept to means or centroids, but medoids are always restricted to be members of the data set. Medoids are most commonly used on data when a mean or centroid cannot be defined, such as graphs. They are also used in contexts where the centroid is not representative of the dataset like in images, 3-D trajectories and gene expression. These are also of interest while wanting to find a representative using some distance other than squared euclidean distance.

In geometry, the geometric median of a discrete set of sample points in a Euclidean space is the point minimizing the sum of distances to the sample points. This generalizes the median, which has the property of minimizing the sum of distances for one-dimensional data, and provides a central tendency in higher dimensions. It is also known as the 1-median, spatial median, Euclidean minisum point, or Torricelli point.
The study of facility location problems (FLP), also known as location analysis, is a branch of operations research and computational geometry concerned with the optimal placement of facilities to minimize transportation costs while considering factors like avoiding placing hazardous materials near housing, and competitors' facilities. The techniques also apply to cluster analysis.
In computer science, online machine learning is a method of machine learning in which data becomes available in a sequential order and is used to update the best predictor for future data at each step, as opposed to batch learning techniques which generate the best predictor by learning on the entire training data set at once. Online learning is a common technique used in areas of machine learning where it is computationally infeasible to train over the entire dataset, requiring the need of out-of-core algorithms. It is also used in situations where it is necessary for the algorithm to dynamically adapt to new patterns in the data, or when the data itself is generated as a function of time, e.g., stock price prediction. Online learning algorithms may be prone to catastrophic interference, a problem that can be addressed by incremental learning approaches.
An important aspect in the study of elliptic curves is devising effective ways of counting points on the curve. There have been several approaches to do so, and the algorithms devised have proved to be useful tools in the study of various fields such as number theory, and more recently in cryptography and Digital Signature Authentication. While in number theory they have important consequences in the solving of Diophantine equations, with respect to cryptography, they enable us to make effective use of the difficulty of the discrete logarithm problem (DLP) for the group , of elliptic curves over a finite field , where q = pk and p is a prime. The DLP, as it has come to be known, is a widely used approach to public key cryptography, and the difficulty in solving this problem determines the level of security of the cryptosystem. This article covers algorithms to count points on elliptic curves over fields of large characteristic, in particular p > 3. For curves over fields of small characteristic more efficient algorithms based on p-adic methods exist.
In computer science, streaming algorithms are algorithms for processing data streams in which the input is presented as a sequence of items and can be examined in only a few passes, typically just one. These algorithms are designed to operate with limited memory, generally logarithmic in the size of the stream and/or in the maximum value in the stream, and may also have limited processing time per item.
BIRCH is an unsupervised data mining algorithm used to perform hierarchical clustering over particularly large data-sets. With modifications it can also be used to accelerate k-means clustering and Gaussian mixture modeling with the expectation–maximization algorithm. An advantage of BIRCH is its ability to incrementally and dynamically cluster incoming, multi-dimensional metric data points in an attempt to produce the best quality clustering for a given set of resources. In most cases, BIRCH only requires a single scan of the database.
In data mining, k-means++ is an algorithm for choosing the initial values for the k-means clustering algorithm. It was proposed in 2007 by David Arthur and Sergei Vassilvitskii, as an approximation algorithm for the NP-hard k-means problem—a way of avoiding the sometimes poor clusterings found by the standard k-means algorithm. It is similar to the first of three seeding methods proposed, in independent work, in 2006 by Rafail Ostrovsky, Yuval Rabani, Leonard Schulman and Chaitanya Swamy.
In graph theory, the metric k-center problem is a combinatorial optimization problem studied in theoretical computer science. Given n cities with specified distances, one wants to build k warehouses in different cities and minimize the maximum distance of a city to a warehouse. In graph theory, this means finding a set of k vertices for which the largest distance of any point to its closest vertex in the k-set is minimum. The vertices must be in a metric space, providing a complete graph that satisfies the triangle inequality.
In numerical mathematics, hierarchical matrices (H-matrices) are used as data-sparse approximations of non-sparse matrices. While a sparse matrix of dimension can be represented efficiently in units of storage by storing only its non-zero entries, a non-sparse matrix would require units of storage, and using this type of matrices for large problems would therefore be prohibitively expensive in terms of storage and computing time. Hierarchical matrices provide an approximation requiring only units of storage, where is a parameter controlling the accuracy of the approximation. In typical applications, e.g., when discretizing integral equations, preconditioning the resulting systems of linear equations, or solving elliptic partial differential equations, a rank proportional to with a small constant is sufficient to ensure an accuracy of . Compared to many other data-sparse representations of non-sparse matrices, hierarchical matrices offer a major advantage: the results of matrix arithmetic operations like matrix multiplication, factorization or inversion can be approximated in operations, where
In data mining and machine learning, kq-flats algorithm is an iterative method which aims to partition m observations into k clusters where each cluster is close to a q-flat, where q is a given integer.
In data structures, a range query consists of pre-processing some input data into a data structure to efficiently answer any number of queries on any subset of the input. Particularly, there is a group of problems that have been extensively studied where the input is an array of unsorted numbers and a query consists of computing some function, such as the minimum, on a specific range of the array.

In computational geometry, the farthest-first traversal of a compact metric space is a sequence of points in the space, where the first point is selected arbitrarily and each successive point is as far as possible from the set of previously-selected points. The same concept can also be applied to a finite set of geometric points, by restricting the selected points to belong to the set or equivalently by considering the finite metric space generated by these points. For a finite metric space or finite set of geometric points, the resulting sequence forms a permutation of the points, also known as the greedy permutation.

In machine learning, Manifold regularization is a technique for using the shape of a dataset to constrain the functions that should be learned on that dataset. In many machine learning problems, the data to be learned do not cover the entire input space. For example, a facial recognition system may not need to classify any possible image, but only the subset of images that contain faces. The technique of manifold learning assumes that the relevant subset of data comes from a manifold, a mathematical structure with useful properties. The technique also assumes that the function to be learned is smooth: data with different labels are not likely to be close together, and so the labeling function should not change quickly in areas where there are likely to be many data points. Because of this assumption, a manifold regularization algorithm can use unlabeled data to inform where the learned function is allowed to change quickly and where it is not, using an extension of the technique of Tikhonov regularization. Manifold regularization algorithms can extend supervised learning algorithms in semi-supervised learning and transductive learning settings, where unlabeled data are available. The technique has been used for applications including medical imaging, geographical imaging, and object recognition.