Related Research Articles
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
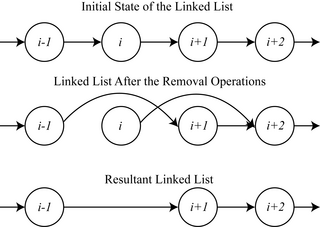
In computer science, mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions. It is the requirement that one thread of execution never enters a critical section while a concurrent thread of execution is already accessing said critical section, which refers to an interval of time during which a thread of execution accesses a shared resource or shared memory.

In concurrent computing, deadlock is any situation in which no member of some group of entities can proceed because each waits for another member, including itself, to take action, such as sending a message or, more commonly, releasing a lock. Deadlocks are a common problem in multiprocessing systems, parallel computing, and distributed systems, because in these contexts systems often use software or hardware locks to arbitrate shared resources and implement process synchronization.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
In information technology and computer science, especially in the fields of computer programming, operating systems, multiprocessors, and databases, concurrency control ensures that correct results for concurrent operations are generated, while getting those results as quickly as possible.
In computer science, a lock or mutex is a synchronization primitive that prevents state from being modified or accessed by multiple threads of execution at once. Locks enforce mutual exclusion concurrency control policies, and with a variety of possible methods there exists multiple unique implementations for different applications.
In databases and transaction processing, two-phase locking (2PL) is a concurrency control method that guarantees serializability. It is also the name of the resulting set of database transaction schedules (histories). The protocol uses locks, applied by a transaction to data, which may block other transactions from accessing the same data during the transaction's life.
In software engineering, a spinlock is a lock that causes a thread trying to acquire it to simply wait in a loop ("spin") while repeatedly checking whether the lock is available. Since the thread remains active but is not performing a useful task, the use of such a lock is a kind of busy waiting. Once acquired, spinlocks will usually be held until they are explicitly released, although in some implementations they may be automatically released if the thread being waited on blocks or "goes to sleep".

In computer science, the dining philosophers problem is an example problem often used in concurrent algorithm design to illustrate synchronization issues and techniques for resolving them.
In computer science, an algorithm is called non-blocking if failure or suspension of any thread cannot cause failure or suspension of another thread; for some operations, these algorithms provide a useful alternative to traditional blocking implementations. A non-blocking algorithm is lock-free if there is guaranteed system-wide progress, and wait-free if there is also guaranteed per-thread progress. "Non-blocking" was used as a synonym for "lock-free" in the literature until the introduction of obstruction-freedom in 2003.
In computer science, serializing tokens are a concept in concurrency control arising from the ongoing development of DragonFly BSD. According to Matthew Dillon, they are most akin to SPLs, except a token works across multiple CPUs while SPLs only work within a single CPU's domain.

In concurrent programming, an operation is linearizable if it consists of an ordered list of invocation and response events, that may be extended by adding response events such that:
- The extended list can be re-expressed as a sequential history.
- That sequential history is a subset of the original unextended list.
In computer science, software transactional memory (STM) is a concurrency control mechanism analogous to database transactions for controlling access to shared memory in concurrent computing. It is an alternative to lock-based synchronization. STM is a strategy implemented in software, rather than as a hardware component. A transaction in this context occurs when a piece of code executes a series of reads and writes to shared memory. These reads and writes logically occur at a single instant in time; intermediate states are not visible to other (successful) transactions. The idea of providing hardware support for transactions originated in a 1986 paper by Tom Knight. The idea was popularized by Maurice Herlihy and J. Eliot B. Moss. In 1995 Nir Shavit and Dan Touitou extended this idea to software-only transactional memory (STM). Since 2005, STM has been the focus of intense research and support for practical implementations is growing.
In computer science, the reentrant mutex is a particular type of mutual exclusion (mutex) device that may be locked multiple times by the same process/thread, without causing a deadlock.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.
In computer science, a readers–writer is a synchronization primitive that solves one of the readers–writers problems. An RW lock allows concurrent access for read-only operations, whereas write operations require exclusive access. This means that multiple threads can read the data in parallel but an exclusive lock is needed for writing or modifying data. When a writer is writing the data, all other writers and readers will be blocked until the writer is finished writing. A common use might be to control access to a data structure in memory that cannot be updated atomically and is invalid until the update is complete.
In concurrency control of databases, transaction processing, and various transactional applications, both centralized and distributed, a transaction schedule is serializable if its outcome is equal to the outcome of its transactions executed serially, i.e. without overlapping in time. Transactions are normally executed concurrently, since this is the most efficient way. Serializability is the major correctness criterion for concurrent transactions' executions. It is considered the highest level of isolation between transactions, and plays an essential role in concurrency control. As such it is supported in all general purpose database systems. Strong strict two-phase locking (SS2PL) is a popular serializability mechanism utilized in most of the database systems since their early days in the 1970s.
Commitment ordering (CO) is a class of interoperable serializability techniques in concurrency control of databases, transaction processing, and related applications. It allows optimistic (non-blocking) implementations. With the proliferation of multi-core processors, CO has also been increasingly utilized in concurrent programming, transactional memory, and software transactional memory (STM) to achieve serializability optimistically. CO is also the name of the resulting transaction schedule (history) property, defined in 1988 with the name dynamic atomicity. In a CO compliant schedule, the chronological order of commitment events of transactions is compatible with the precedence order of the respective transactions. CO is a broad special case of conflict serializability and effective means to achieve global serializability across any collection of database systems that possibly use different concurrency control mechanisms.
In computer science, synchronization is the task of coordinating multiple of processes to join up or handshake at a certain point, in order to reach an agreement or commit to a certain sequence of action.

A wait-for graph in computer science is a directed graph used for deadlock detection in operating systems and relational database systems.