Related Research Articles

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts, data, or entities that pertain to one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of terms and relational expressions that represent the entities in that subject area. The field which studies ontologies so conceived is sometimes referred to as applied ontology.
MPEG-7 is a multimedia content description standard. It was standardized in ISO/IEC 15938. This description will be associated with the content itself, to allow fast and efficient searching for material that is of interest to the user. MPEG-7 is formally called Multimedia Content Description Interface. Thus, it is not a standard which deals with the actual encoding of moving pictures and audio, like MPEG-1, MPEG-2 and MPEG-4. It uses XML to store metadata, and can be attached to timecode in order to tag particular events, or synchronise lyrics to a song, for example.
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects.
Web annotation can refer to online annotations of web resources such as web pages or parts of them, or a set of W3C standards developed for this purpose. The term can also refer to the creations of annotations on the World Wide Web and it has been used in this sense for the annotation tool INCEpTION, formerly WebAnno. This is a general feature of several tools for annotation in natural language processing or in the philologies.
An annotation is extra information associated with a particular point in a document or other piece of information. It can be a note that includes a comment or explanation. Annotations are sometimes presented in the margin of book pages. For annotations of different digital media, see web annotation and text annotation.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".
RDFa or Resource Description Framework in Attributes is a W3C Recommendation that adds a set of attribute-level extensions to HTML, XHTML and various XML-based document types for embedding rich metadata within Web documents. The Resource Description Framework (RDF) data-model mapping enables its use for embedding RDF subject-predicate-object expressions within XHTML documents. It also enables the extraction of RDF model triples by compliant user agents.
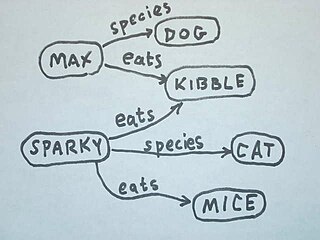
The ultimate goal of semantic technology is to help machines understand data. To enable the encoding of semantics with the data, well-known technologies are RDF and OWL. These technologies formally represent the meaning involved in information. For example, ontology can describe concepts, relationships between things, and categories of things. These embedded semantics with the data offer significant advantages such as reasoning over data and dealing with heterogeneous data sources.
The Systems Biology Ontology (SBO) is a set of controlled, relational vocabularies of terms commonly used in systems biology, and in particular in computational modeling.
Semantic publishing on the Web, or semantic web publishing, refers to publishing information on the web as documents accompanied by semantic markup. Semantic publication provides a way for computers to understand the structure and even the meaning of the published information, making information search and data integration more efficient.
Linguistic categories include
DBpedia is a project aiming to extract structured content from the information created in the Wikipedia project. This structured information is made available on the World Wide Web. DBpedia allows users to semantically query relationships and properties of Wikipedia resources, including links to other related datasets.
Amit Sheth is a computer scientist at University of South Carolina in Columbia, South Carolina. He is the founding Director of the Artificial Intelligence Institute, and a Professor of Computer Science and Engineering. From 2007 to June 2019, he was the Lexis Nexis Ohio Eminent Scholar, director of the Ohio Center of Excellence in Knowledge-enabled Computing, and a Professor of Computer Science at Wright State University. Sheth's work has been cited by over 48,800 publications. He has an h-index of 106, which puts him among the top 100 computer scientists with the highest h-index. Prior to founding the Kno.e.sis Center, he served as the director of the Large Scale Distributed Information Systems Lab at the University of Georgia in Athens, Georgia.

In computer science, information science and systems engineering, ontology engineering is a field which studies the methods and methodologies for building ontologies, which encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities of a given domain of interest. In a broader sense, this field also includes a knowledge construction of the domain using formal ontology representations such as OWL/RDF. A large-scale representation of abstract concepts such as actions, time, physical objects and beliefs would be an example of ontological engineering. Ontology engineering is one of the areas of applied ontology, and can be seen as an application of philosophical ontology. Core ideas and objectives of ontology engineering are also central in conceptual modeling.

Text annotation is the practice and the result of adding a note or gloss to a text, which may include highlights or underlining, comments, footnotes, tags, and links. Text annotations can include notes written for a reader's private purposes, as well as shared annotations written for the purposes of collaborative writing and editing, commentary, or social reading and sharing. In some fields, text annotation is comparable to metadata insofar as it is added post hoc and provides information about a text without fundamentally altering that original text. Text annotations are sometimes referred to as marginalia, though some reserve this term specifically for hand-written notes made in the margins of books or manuscripts. Annotations have been found to be useful and help to develop knowledge of English literature.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
In markup languages and the digital humanities, overlap occurs when a document has two or more structures that interact in a non-hierarchical manner. A document with overlapping markup cannot be represented as a tree. This is also known as concurrent markup. Overlap happens, for instance, in poetry, where there may be a metrical structure of feet and lines; a linguistic structure of sentences and quotations; and a physical structure of volumes and pages and editorial annotations.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.
In linguistics and language technology, a language resource is a "[composition] of linguistic material used in the construction, improvement and/or evaluation of language processing applications, (...) in language and language-mediated research studies and applications."
References
- ↑ Shakespeare, William; edited by Harold Jenkins (1997). Hamlet (Repr. by Nelson. ed.). Walton-on-Thames: Thomas Nelson. ISBN 978-0174434696.
{{cite book}}:|first1=has generic name (help)CS1 maint: multiple names: authors list (link) - ↑ Berners-Lee, Tim; Hendler, James; Lassila, Ora (1 January 2001). "The Semantic Web". Scientific American. 284 (5): 34–43. Bibcode:2001SciAm.284e..34B. doi:10.1038/scientificamerican0501-34. Archived from the original on 6 September 2018. Retrieved 12 October 2016.
- ↑ ZARRI, GIAN PIERO (September 1997). "NKRL, a knowledge representation tool for encoding the 'meaning' of complex narrative texts". Natural Language Engineering. 3 (2): 231–253. CiteSeerX 10.1.1.519.7577 . doi:10.1017/S1351324997001794. S2CID 29721071.
- ↑ Elson, David K. "DramaBank: Annotating Agency in Narrative Discourse" (PDF): 2813–2819.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Schank, Roger C.; Abelson, Robert P. (1 January 1975). "Scripts, Plans, and Knowledge". Proceedings of the 4th International Joint Conference on Artificial Intelligence - Volume 1. Ijcai'75: 151–157.
- ↑ Minsky, Marvin (1 January 1975). "Minsky's Frame System Theory". Proceedings of the 1975 Workshop on Theoretical Issues in Natural Language Processing. Tinlap '75: 104–116. doi: 10.3115/980190.980222 .
- ↑ Baker, Collin F.; Fillmore, Charles J.; Lowe, John B. (1 January 1998). "The Berkeley FrameNet Project". Proceedings of the 36th annual meeting on Association for Computational Linguistics -. Vol. 1. pp. 86–90. doi: 10.3115/980845.980860 .
{{cite book}}:|journal=ignored (help) - ↑ Finlayson, Mark Alan. "The Story Workbench: An Extensible Semi-Automatic Text Annotation Tool": 21–24.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Coombs, James H.; Renear, Allen H.; DeRose, Steven J. (1 November 1987). "Markup Systems and the Future of Scholarly Text Processing". Commun. ACM. 30 (11): 933–947. CiteSeerX 10.1.1.515.5618 . doi:10.1145/32206.32209. ISSN 0001-0782. S2CID 59941802.
- ↑ ZARRI, GIAN PIERO (September 1997). "NKRL, a knowledge representation tool for encoding the 'meaning' of complex narrative texts". Natural Language Engineering. 3 (2): 231–253. CiteSeerX 10.1.1.519.7577 . doi:10.1017/S1351324997001794. S2CID 29721071.
- ↑ http://lrec.elra.info/proceedings/lrec2012/pdf/866_Paper.pdf [ bare URL PDF ]
- ↑ Rahimtoroghi, Elahe; Corcoran, Thomas; Swanson, Reid; Walker, Marilyn A.; Sagae, Kenji; Gordon, Andrew (23 October 2014). "Minimal Narrative Annotation Schemes and Their Applications".
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Francois, A.R.J.; Nevatia, R.; Hobbs, J.; Bolles, R.C. (October 2005). "VERL: An Ontology Framework for Representing and Annotating Video Events". IEEE MultiMedia. 12 (4): 76–86. doi:10.1109/MMUL.2005.87. S2CID 8772560.
- ↑ Shaw, Ryan; Troncy, Raphaël; Hardman, Lynda (6 December 2009). "LODE: Linking Open Descriptions of Events". The Semantic Web. Lecture Notes in Computer Science. Vol. 5926. pp. 153–167. CiteSeerX 10.1.1.154.5031 . doi:10.1007/978-3-642-10871-6_11. ISBN 978-3-642-10870-9. S2CID 14327857.
- ↑ Khrouf, Houda; Troncy, Raphael (2016). "EventMedia: a LOD Dataset of Events Illustrated with Media". Semantic Web. 7 (2): 193–199. doi:10.3233/SW-150184.
- ↑ "Jey Biddulph".
- ↑ Wolff, Annika; Mulholland, Paul; Collins, Trevor (1 January 2012). "Storyspace". Proceedings of the 23rd ACM conference on Hypertext and social media. pp. 89–98. doi:10.1145/2309996.2310012. ISBN 9781450313353. S2CID 3340126.
- ↑ Mulholland, P.; Collins, T. (1 September 2002). "Using digital narratives to support the collaborative learning and exploration of cultural heritage". Proceedings. 13th International Workshop on Database and Expert Systems Applications. 13th International Workshop on Database and Expert Systems Applications, 2002. Proceedings. pp. 527–531. CiteSeerX 10.1.1.8.7977 . doi:10.1109/DEXA.2002.1045951. ISBN 978-0-7695-1668-4.
- ↑ Martens, Chris; Bosser, Anne-Gwenn; Ferreira, João F.; Cavazza, Marc (15 September 2013). "Linear Logic Programming for Narrative Generation". Logic Programming and Nonmonotonic Reasoning. Lecture Notes in Computer Science. Vol. 8148. pp. 427–432. doi:10.1007/978-3-642-40564-8_42. hdl:10149/312346. ISBN 978-3-642-40563-1.
- ↑ Peinado, Federico; Gervás, Pablo; Díaz-Agudo, Belén (2004). "A description logic ontology for fairy tale generation". LREC Workshop on Language Resources for Linguistic Creativity. 4: 56–61.
- ↑ Szilas, Nicolas (11 February 2016). "Modeling and Representing Dramatic Situations as Paradoxical Structures". Digital Scholarship in the Humanities. 32 (2): 403–422. doi:10.1093/llc/fqv071. ISSN 2055-7671.