A statistical hypothesis test is a method of statistical inference used to decide whether the data at hand sufficiently support a particular hypothesis. Hypothesis testing allows us to make probabilistic statements about population parameters.

A cognitive bias is a systematic pattern of deviation from norm or rationality in judgment. Individuals create their own "subjective reality" from their perception of the input. An individual's construction of reality, not the objective input, may dictate their behavior in the world. Thus, cognitive biases may sometimes lead to perceptual distortion, inaccurate judgment, illogical interpretation, or what is broadly called irrationality.
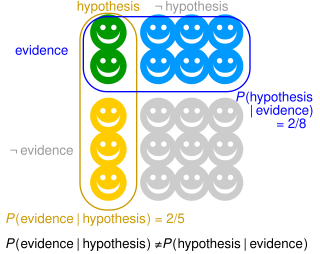
The prosecutor's fallacy is a fallacy of statistical reasoning involving a test for an occurrence, such as a DNA match. A positive result in the test may paradoxically be more likely to be an erroneous result than an actual occurrence, even if the test is very accurate. The fallacy is named because it is typically used by a prosecutor to exaggerate the probability of a criminal defendant's guilt. The fallacy can be used to support other claims as well – including the innocence of a defendant.
Confirmation bias is the tendency to search for, interpret, favor, and recall information in a way that confirms or supports one's prior beliefs or values. People display this bias when they select information that supports their views, ignoring contrary information, or when they interpret ambiguous evidence as supporting their existing attitudes. The effect is strongest for desired outcomes, for emotionally charged issues, and for deeply entrenched beliefs. Confirmation bias cannot be eliminated, but it can be managed, for example, by education and training in critical thinking skills.

A chi-squared test is a statistical hypothesis test used in the analysis of contingency tables when the sample sizes are large. In simpler terms, this test is primarily used to examine whether two categorical variables are independent in influencing the test statistic. The test is valid when the test statistic is chi-squared distributed under the null hypothesis, specifically Pearson's chi-squared test and variants thereof. Pearson's chi-squared test is used to determine whether there is a statistically significant difference between the expected frequencies and the observed frequencies in one or more categories of a contingency table. For contingency tables with smaller sample sizes, a Fisher's exact test is used instead.
The availability heuristic, also known as availability bias, is a mental shortcut that relies on immediate examples that come to a given person's mind when evaluating a specific topic, concept, method, or decision. This heuristic, operating on the notion that, if something can be recalled, it must be important, or at least more important than alternative solutions not as readily recalled, is inherently biased toward recently acquired information.
Hindsight bias, also known as the knew-it-all-along phenomenon or creeping determinism, is the common tendency for people to perceive past events as having been more predictable than they were.
The mere-exposure effect is a psychological phenomenon by which people tend to develop a preference for things merely because they are familiar with them. In social psychology, this effect is sometimes called the familiarity principle. The effect has been demonstrated with many kinds of things, including words, Chinese characters, paintings, pictures of faces, geometric figures, and sounds. In studies of interpersonal attraction, the more often people see a person, the more pleasing and likeable they find that person.
The conjunction fallacy is an inference from an array of particulars, in violation of the laws of probability, that a conjoint set of two or more conclusions is likelier than any single member of that same set. It is a type of formal fallacy.

The base rate fallacy, also called base rate neglect or base rate bias, is a type of fallacy in which people tend to ignore the base rate in favor of the individuating information . Base rate neglect is a specific form of the more general extension neglect.
The recognition heuristic, originally termed the recognition principle, has been used as a model in the psychology of judgment and decision making and as a heuristic in artificial intelligence. The goal is to make inferences about a criterion that is not directly accessible to the decision maker, based on recognition retrieved from memory. This is possible if recognition of alternatives has relevance to the criterion. For two alternatives, the heuristic is defined as:
If one of two objects is recognized and the other is not, then infer that the recognized object has the higher value with respect to the criterion.

Gerd Gigerenzer is a German psychologist who has studied the use of bounded rationality and heuristics in decision making. Gigerenzer is director emeritus of the Center for Adaptive Behavior and Cognition (ABC) at the Max Planck Institute for Human Development and director of the Harding Center for Risk Literacy, both in Berlin.
Cue validity is the conditional probability that an object falls in a particular category given a particular feature or cue. The term was popularized by Beach (1964), Reed (1972) and especially by Eleanor Rosch in her investigations of the acquisition of so-called basic categories.
The negativity bias, also known as the negativity effect, is a cognitive bias that, even when of equal intensity, things of a more negative nature have a greater effect on one's psychological state and processes than neutral or positive things. In other words, something very positive will generally have less of an impact on a person's behavior and cognition than something equally emotional but negative. The negativity bias has been investigated within many different domains, including the formation of impressions and general evaluations; attention, learning, and memory; and decision-making and risk considerations.
In probability and statistics, the base rate is the class of probabilities unconditional on "featural evidence" (likelihoods).
The psychology of reasoning is the study of how people reason, often broadly defined as the process of drawing conclusions to inform how people solve problems and make decisions. It overlaps with psychology, philosophy, linguistics, cognitive science, artificial intelligence, logic, and probability theory.
Metamemory or Socratic awareness, a type of metacognition, is both the introspective knowledge of one's own memory capabilities and the processes involved in memory self-monitoring. This self-awareness of memory has important implications for how people learn and use memories. When studying, for example, students make judgments of whether they have successfully learned the assigned material and use these decisions, known as "judgments of learning", to allocate study time.
Heuristics is the process by which humans use mental short cuts to arrive at decisions. Heuristics are simple strategies that humans, animals, organizations, and even machines use to quickly form judgments, make decisions, and find solutions to complex problems. Often this involves focusing on the most relevant aspects of a problem or situation to formulate a solution. While heuristic processes are used to find the answers and solutions that are most likely to work or be correct, they are not always right or the most accurate. Judgments and decisions based on heuristics are simply good enough to satisfy a pressing need in situations of uncertainty, where information is incomplete. In that sense they can differ from answers given by logic and probability.
Social heuristics are simple decision making strategies that guide people's behavior and decisions in the social environment when time, information, or cognitive resources are scarce. Social environments tend to be characterised by complexity and uncertainty, and in order to simplify the decision making process, people may use heuristics, which are decision making strategies that involve ignoring some information or relying on simple rules of thumb.
Intuitive statistics, or folk statistics, refers to the cognitive phenomenon where organisms use data to make generalizations and predictions about the world. This can be a small amount of sample data or training instances, which in turn contribute to inductive inferences about either population-level properties, future data, or both. Inferences can involve revising hypotheses, or beliefs, in light of probabilistic data that inform and motivate future predictions. The informal tendency for cognitive animals to intuitively generate statistical inferences, when formalized with certain axioms of probability theory, constitutes statistics as an academic discipline.