In mathematics and computer programming, exponentiating by squaring is a general method for fast computation of large positive integer powers of a number, or more generally of an element of a semigroup, like a polynomial or a square matrix. Some variants are commonly referred to as square-and-multiply algorithms or binary exponentiation. These can be of quite general use, for example in modular arithmetic or powering of matrices. For semigroups for which additive notation is commonly used, like elliptic curves used in cryptography, this method is also referred to as double-and-add.

In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the relative order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.
Merge algorithms are a family of algorithms that take multiple sorted lists as input and produce a single list as output, containing all the elements of the inputs lists in sorted order. These algorithms are used as subroutines in various sorting algorithms, most famously merge sort.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.
In computer science, divide and conquer is an algorithm design paradigm. A divide-and-conquer algorithm recursively breaks down a problem into two or more sub-problems of the same or related type, until these become simple enough to be solved directly. The solutions to the sub-problems are then combined to give a solution to the original problem.
The Cooley–Tukey algorithm, named after J. W. Cooley and John Tukey, is the most common fast Fourier transform (FFT) algorithm. It re-expresses the discrete Fourier transform (DFT) of an arbitrary composite size in terms of N1 smaller DFTs of sizes N2, recursively, to reduce the computation time to O(N log N) for highly composite N (smooth numbers). Because of the algorithm's importance, specific variants and implementation styles have become known by their own names, as described below.
In computer science, a selection algorithm is an algorithm for finding the th smallest value in a collection of ordered values, such as numbers. The value that it finds is called the th order statistic. Selection includes as special cases the problems of finding the minimum, median, and maximum element in the collection. Selection algorithms include quickselect, and the median of medians algorithm. When applied to a collection of values, these algorithms take linear time, as expressed using big O notation. For data that is already structured, faster algorithms may be possible; as an extreme case, selection in an already-sorted array takes time .
External sorting is a class of sorting algorithms that can handle massive amounts of data. External sorting is required when the data being sorted do not fit into the main memory of a computing device and instead they must reside in the slower external memory, usually a disk drive. Thus, external sorting algorithms are external memory algorithms and thus applicable in the external memory model of computation.
In computing, a cache-oblivious algorithm is an algorithm designed to take advantage of a processor cache without having the size of the cache as an explicit parameter. An optimal cache-oblivious algorithm is a cache-oblivious algorithm that uses the cache optimally. Thus, a cache-oblivious algorithm is designed to perform well, without modification, on multiple machines with different cache sizes, or for a memory hierarchy with different levels of cache having different sizes. Cache-oblivious algorithms are contrasted with explicit loop tiling, which explicitly breaks a problem into blocks that are optimally sized for a given cache.
In computing, external memory algorithms or out-of-core algorithms are algorithms that are designed to process data that are too large to fit into a computer's main memory at once. Such algorithms must be optimized to efficiently fetch and access data stored in slow bulk memory such as hard drives or tape drives, or when memory is on a computer network. External memory algorithms are analyzed in the external memory model.
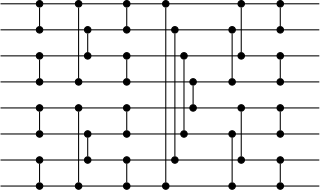
Bitonic mergesort is a parallel algorithm for sorting. It is also used as a construction method for building a sorting network. The algorithm was devised by Ken Batcher. The resulting sorting networks consist of comparators and have a delay of , where is the number of items to be sorted. This makes it a popular choice for sorting large numbers of elements on an architecture which itself contains a large number of parallel execution units running in lockstep, such as a typical GPU.

Quicksort is an efficient, general-purpose sorting algorithm. Quicksort was developed by British computer scientist Tony Hoare in 1959 and published in 1961. It is still a commonly used algorithm for sorting. Overall, it is slightly faster than merge sort and heapsort for randomized data, particularly on larger distributions.
Because matrix multiplication is such a central operation in many numerical algorithms, much work has been invested in making matrix multiplication algorithms efficient. Applications of matrix multiplication in computational problems are found in many fields including scientific computing and pattern recognition and in seemingly unrelated problems such as counting the paths through a graph. Many different algorithms have been designed for multiplying matrices on different types of hardware, including parallel and distributed systems, where the computational work is spread over multiple processors.
Samplesort is a sorting algorithm that is a divide and conquer algorithm often used in parallel processing systems. Conventional divide and conquer sorting algorithms partitions the array into sub-intervals or buckets. The buckets are then sorted individually and then concatenated together. However, if the array is non-uniformly distributed, the performance of these sorting algorithms can be significantly throttled. Samplesort addresses this issue by selecting a sample of size s from the n-element sequence, and determining the range of the buckets by sorting the sample and choosing p−1 < s elements from the result. These elements then divide the array into p approximately equal-sized buckets. Samplesort is described in the 1970 paper, "Samplesort: A Sampling Approach to Minimal Storage Tree Sorting", by W. D. Frazer and A. C. McKellar.

In computer science, a doubly logarithmic tree is a tree where each internal node of height 1, the tree layer above the leaves, has two children, and each internal node of height has children. Each child of the root contains leaves. The number of children at a node from each leaf to root is 0,2,2,4,16, 256, 65536, ...
In mathematics, elliptic curve primality testing techniques, or elliptic curve primality proving (ECPP), are among the quickest and most widely used methods in primality proving. It is an idea put forward by Shafi Goldwasser and Joe Kilian in 1986 and turned into an algorithm by A. O. L. Atkin the same year. The algorithm was altered and improved by several collaborators subsequently, and notably by Atkin and François Morain, in 1993. The concept of using elliptic curves in factorization had been developed by H. W. Lenstra in 1985, and the implications for its use in primality testing followed quickly.
The cache-oblivious distribution sort is a comparison-based sorting algorithm. It is similar to quicksort, but it is a cache-oblivious algorithm, designed for a setting where the number of elements to sort is too large to fit in a cache where operations are done. In the external memory model, the number of memory transfers it needs to perform a sort of items on a machine with cache of size and cache lines of length is , under the tall cache assumption that . This number of memory transfers has been shown to be asymptotically optimal for comparison sorts. This distribution sort also achieves the asymptotically optimal runtime complexity of .

In computer science, sorting is the problem of sorting pairs of numbers by their sums. Applications of the problem include transit fare minimisation, VLSI design, and sparse polynomial multiplication. As with comparison sorting and integer sorting more generally, algorithms for this problem can be based only on comparisons of these sums, or on other operations that work only when the inputs are small integers.
In computer science, an oblivious data structure is a data structure that gives no information about the sequence or pattern of the operations that have been applied except for the final result of the operations.
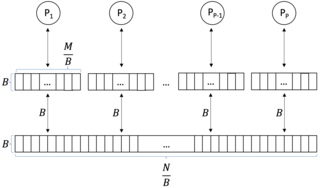
In computer science, a parallel external memory (PEM) model is a cache-aware, external-memory abstract machine. It is the parallel-computing analogy to the single-processor external memory (EM) model. In a similar way, it is the cache-aware analogy to the parallel random-access machine (PRAM). The PEM model consists of a number of processors, together with their respective private caches and a shared main memory.


































