In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding or using such a code is Huffman coding, an algorithm developed by David A. Huffman while he was a Sc.D. student at MIT, and published in the 1952 paper "A Method for the Construction of Minimum-Redundancy Codes".

In information theory, the entropy of a random variable is the average level of "information", "surprise", or "uncertainty" inherent to the variable's possible outcomes. Given a discrete random variable , which takes values in the set and is distributed according to , the entropy is
In computer science, a red–black tree is a self-balancing binary search tree data structure noted for fast storage and retrieval of ordered information. The nodes in a red-black tree hold an extra "color" bit, often drawn as red and black, which help ensure that the tree is always approximately balanced.

A decision tree is a decision support hierarchical model that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm that only contains conditional control statements.
Decision tree learning is a supervised learning approach used in statistics, data mining and machine learning. In this formalism, a classification or regression decision tree is used as a predictive model to draw conclusions about a set of observations.
Association rule learning is a rule-based machine learning method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using some measures of interestingness. In any given transaction with a variety of items, association rules are meant to discover the rules that determine how or why certain items are connected.
Feature selection is the process of selecting a subset of relevant features for use in model construction. Stylometry and DNA microarray analysis are two cases where feature selection is used. It should be distinguished from feature extraction.
In computer science, corecursion is a type of operation that is dual to recursion. Whereas recursion works analytically, starting on data further from a base case and breaking it down into smaller data and repeating until one reaches a base case, corecursion works synthetically, starting from a base case and building it up, iteratively producing data further removed from a base case. Put simply, corecursive algorithms use the data that they themselves produce, bit by bit, as they become available, and needed, to produce further bits of data. A similar but distinct concept is generative recursion, which may lack a definite "direction" inherent in corecursion and recursion.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. K-dimensional is that which concerns exactly k orthogonal axes or a space of any number of dimensions. k-d trees are a useful data structure for several applications, such as:

C4.5 is an algorithm used to generate a decision tree developed by Ross Quinlan. C4.5 is an extension of Quinlan's earlier ID3 algorithm. The decision trees generated by C4.5 can be used for classification, and for this reason, C4.5 is often referred to as a statistical classifier. In 2011, authors of the Weka machine learning software described the C4.5 algorithm as "a landmark decision tree program that is probably the machine learning workhorse most widely used in practice to date".
In information theory and machine learning, information gain is a synonym for Kullback–Leibler divergence; the amount of information gained about a random variable or signal from observing another random variable. However, in the context of decision trees, the term is sometimes used synonymously with mutual information, which is the conditional expected value of the Kullback–Leibler divergence of the univariate probability distribution of one variable from the conditional distribution of this variable given the other one.
Bidirectional search is a graph search algorithm that finds a shortest path from an initial vertex to a goal vertex in a directed graph. It runs two simultaneous searches: one forward from the initial state, and one backward from the goal, stopping when the two meet. The reason for this approach is that in many cases it is faster: for instance, in a simplified model of search problem complexity in which both searches expand a tree with branching factor b, and the distance from start to goal is d, each of the two searches has complexity O(bd/2) (in Big O notation), and the sum of these two search times is much less than the O(bd) complexity that would result from a single search from the beginning to the goal.
John Ross Quinlan is a computer science researcher in data mining and decision theory. He has contributed extensively to the development of decision tree algorithms, including inventing the canonical C4.5 and ID3 algorithms. He also contributed to early ILP literature with First Order Inductive Learner (FOIL). He is currently running the company RuleQuest Research which he founded in 1997.
An alternating decision tree (ADTree) is a machine learning method for classification. It generalizes decision trees and has connections to boosting.
Hilbert R-tree, an R-tree variant, is an index for multidimensional objects such as lines, regions, 3-D objects, or high-dimensional feature-based parametric objects. It can be thought of as an extension to B+-tree for multidimensional objects.
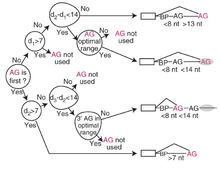
In decision tree learning, information gain ratio is a ratio of information gain to the intrinsic information. It was proposed by Ross Quinlan, to reduce a bias towards multi-valued attributes by taking the number and size of branches into account when choosing an attribute.
Gradient boosting is a machine learning technique based on boosting in a functional space, where the target is pseudo-residuals rather than the typical residuals used in traditional boosting. It gives a prediction model in the form of an ensemble of weak prediction models, i.e., models that make very few assumptions about the data, which are typically simple decision trees. When a decision tree is the weak learner, the resulting algorithm is called gradient-boosted trees; it usually outperforms random forest. A gradient-boosted trees model is built in a stage-wise fashion as in other boosting methods, but it generalizes the other methods by allowing optimization of an arbitrary differentiable loss function.
Features from accelerated segment test (FAST) is a corner detection method, which could be used to extract feature points and later used to track and map objects in many computer vision tasks. The FAST corner detector was originally developed by Edward Rosten and Tom Drummond, and was published in 2006. The most promising advantage of the FAST corner detector is its computational efficiency. Referring to its name, it is indeed faster than many other well-known feature extraction methods, such as difference of Gaussians (DoG) used by the SIFT, SUSAN and Harris detectors. Moreover, when machine learning techniques are applied, superior performance in terms of computation time and resources can be realised. The FAST corner detector is very suitable for real-time video processing application because of this high-speed performance.

The Wavelet Tree is a succinct data structure to store strings in compressed space. It generalizes the and operations defined on bitvectors to arbitrary alphabets.
Isolation Forest is an algorithm for data anomaly detection initially developed by Fei Tony Liu in 2008. Isolation Forest detects anomalies using binary trees. The algorithm has a linear time complexity and a low memory requirement, which works well with high-volume data. In essence, the algorithm relies upon the characteristics of anomalies, i.e., being few and different, in order to detect anomalies. No density estimation is performed in the algorithm. The algorithm is different from decision tree algorithms in that only the path-length measure or approximation is being used to generate the anomaly score, no leaf node statistics on class distribution or target value is needed.