Semantics
An ID is a directed acyclic graph with three types (plus one subtype) of node and three types of arc (or arrow) between nodes.
Nodes:
- Decision node (corresponding to each decision to be made) is drawn as a rectangle.
- Uncertainty node (corresponding to each uncertainty to be modeled) is drawn as an oval.
- Deterministic node (corresponding to special kind of uncertainty that its outcome is deterministically known whenever the outcome of some other uncertainties are also known) is drawn as a double oval.
Arcs:
- Functional arcs (ending in value node) indicate that one of the components of additively separable utility function is a function of all the nodes at their tails.
- Conditional arcs (ending in uncertainty node) indicate that the uncertainty at their heads is probabilistically conditioned on all the nodes at their tails.
- Conditional arcs (ending in deterministic node) indicate that the uncertainty at their heads is deterministically conditioned on all the nodes at their tails.
- Informational arcs (ending in decision node) indicate that the decision at their heads is made with the outcome of all the nodes at their tails known beforehand.
Given a properly structured ID:
- Decision nodes and incoming information arcs collectively state the alternatives (what can be done when the outcome of certain decisions and/or uncertainties are known beforehand)
- Uncertainty/deterministic nodes and incoming conditional arcs collectively model the information (what are known and their probabilistic/deterministic relationships)
- Value nodes and incoming functional arcs collectively quantify the preference (how things are preferred over one another).
Alternative, information, and preference are termed decision basis in decision analysis, they represent three required components of any valid decision situation.
Formally, the semantic of influence diagram is based on sequential construction of nodes and arcs, which implies a specification of all conditional independencies in the diagram. The specification is defined by the  -separation criterion of Bayesian network. According to this semantic, every node is probabilistically independent on its non-successor nodes given the outcome of its immediate predecessor nodes. Likewise, a missing arc between non-value node
-separation criterion of Bayesian network. According to this semantic, every node is probabilistically independent on its non-successor nodes given the outcome of its immediate predecessor nodes. Likewise, a missing arc between non-value node  and non-value node
and non-value node  implies that there exists a set of non-value nodes
implies that there exists a set of non-value nodes  , e.g., the parents of , that renders independent of given the outcome of the nodes in .
, e.g., the parents of , that renders independent of given the outcome of the nodes in .
The above example highlights the power of the influence diagram in representing an extremely important concept in decision analysis known as the value of information. Consider the following three scenarios;
- Scenario 1: The decision-maker could make their Vacation Activity decision while knowing what Weather Condition will be like. This corresponds to adding extra informational arc from Weather Condition to Vacation Activity in the above influence diagram.
- Scenario 2: The original influence diagram as shown above.
- Scenario 3: The decision-maker makes their decision without even knowing the Weather Forecast. This corresponds to removing informational arc from Weather Forecast to Vacation Activity in the above influence diagram.
Scenario 1 is the best possible scenario for this decision situation since there is no longer any uncertainty on what they care about (Weather Condition) when making their decision. Scenario 3, however, is the worst possible scenario for this decision situation since they need to make their decision without any hint (Weather Forecast) on what they care about (Weather Condition) will turn out to be.
The decision-maker is usually better off (definitely no worse off, on average) to move from scenario 3 to scenario 2 through the acquisition of new information. The most they should be willing to pay for such move is called the value of information on Weather Forecast, which is essentially the value of imperfect information on Weather Condition.
Likewise, it is the best for the decision-maker to move from scenario 3 to scenario 1. The most they should be willing to pay for such move is called the value of perfect information on Weather Condition.
The applicability of this simple ID and the value of information concept is tremendous, especially in medical decision making when most decisions have to be made with imperfect information about their patients, diseases, etc.
Hidden Markov Model (HMM) is a statistical Markov model in which the system being modeled is assumed to be a Markov process — call it — with unobservable ("hidden") states. As part of the definition, HMM requires that there be an observable process whose outcomes are "influenced" by the outcomes of in a known way. Since cannot be observed directly, the goal is to learn about by observing HMM has an additional requirement that the outcome of at time may be "influenced" exclusively by the outcome of at and that the outcomes of and at must not affect the outcome of at
A Bayesian network is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases.

A decision tree is a decision support tool that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm that only contains conditional control statements.

A graphical model or probabilistic graphical model (PGM) or structured probabilistic model is a probabilistic model for which a graph expresses the conditional dependence structure between random variables. They are commonly used in probability theory, statistics—particularly Bayesian statistics—and machine learning.
In statistics, Gibbs sampling or a Gibbs sampler is a Markov chain Monte Carlo (MCMC) algorithm for obtaining a sequence of observations which are approximated from a specified multivariate probability distribution, when direct sampling is difficult. This sequence can be used to approximate the joint distribution ; to approximate the marginal distribution of one of the variables, or some subset of the variables ; or to compute an integral. Typically, some of the variables correspond to observations whose values are known, and hence do not need to be sampled.
The Markov condition, sometimes called the Markov assumption, is an assumption made in Bayesian probability theory, that every node in a Bayesian network is conditionally independent of its nondescendants, given its parents. Stated loosely, it is assumed that a node has no bearing on nodes which do not descend from it. In a DAG, this local Markov condition is equivalent to the global Markov condition, which states that d-separations in the graph also correspond to conditional independence relations. This also means that a node is conditionally independent of the entire network, given its Markov blanket.
Decision analysis (DA) is the discipline comprising the philosophy, methodology, and professional practice necessary to address important decisions in a formal manner. Decision analysis includes many procedures, methods, and tools for identifying, clearly representing, and formally assessing important aspects of a decision; for prescribing a recommended course of action by applying the maximum expected-utility axiom to a well-formed representation of the decision; and for translating the formal representation of a decision and its corresponding recommendation into insight for the decision maker, and other corporate and non-corporate stakeholders.
Value of information is the amount a decision maker would be willing to pay for information prior to making a decision.
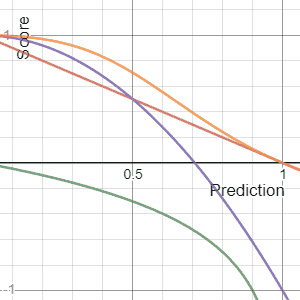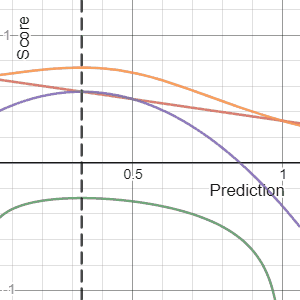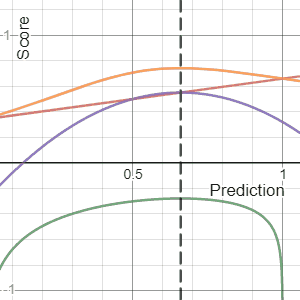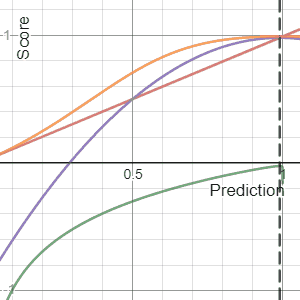
In decision theory, a score function, or scoring rule, measures the accuracy of probabilistic predictions. It is applicable to tasks in which predictions must assign probabilities to a set of mutually exclusive outcomes or classes. The set of possible outcomes can be either binary or categorical in nature, and the probabilities assigned to this set of outcomes must sum to one. A score can be thought of as either a measure of the "calibration" of a set of probabilistic predictions, or as a "cost function" or "loss function".
Probabilistic forecasting summarizes what is known about, or opinions about, future events. In contrast to single-valued forecasts, probabilistic forecasts assign a probability to each of a number of different outcomes, and the complete set of probabilities represents a probability forecast. Thus, probabilistic forecasting is a type of probabilistic classification.
Uncertainty quantification (UQ) is the science of quantitative characterization and reduction of uncertainties in both computational and real world applications. It tries to determine how likely certain outcomes are if some aspects of the system are not exactly known. An example would be to predict the acceleration of a human body in a head-on crash with another car: even if the speed was exactly known, small differences in the manufacturing of individual cars, how tightly every bolt has been tightened, etc., will lead to different results that can only be predicted in a statistical sense.

Event chain methodology is a network analysis technique that is focused on identifying and managing events and relationship between them that affect project schedules. It is an uncertainty modeling schedule technique. Event chain methodology is an extension of quantitative project risk analysis with Monte Carlo simulations. It is the next advance beyond critical path method and critical chain project management. Event chain methodology tries to mitigate the effect of motivational and cognitive biases in estimating and scheduling. It improves accuracy of risk assessment and helps to generate more realistic risk adjusted project schedules.
In decision theory, the expected value of sample information (EVSI) is the expected increase in utility that a decision-maker could obtain from gaining access to a sample of additional observations before making a decision. The additional information obtained from the sample may allow them to make a more informed, and thus better, decision, thus resulting in an increase in expected utility. EVSI attempts to estimate what this improvement would be before seeing actual sample data; hence, EVSI is a form of what is known as preposterior analysis.
In Bayesian inference, plate notation is a method of representing variables that repeat in a graphical model. Instead of drawing each repeated variable individually, a plate or rectangle is used to group variables into a subgraph that repeat together, and a number is drawn on the plate to represent the number of repetitions of the subgraph in the plate. The assumptions are that the subgraph is duplicated that many times, the variables in the subgraph are indexed by the repetition number, and any links that cross a plate boundary are replicated once for each subgraph repetition.
An optimal decision is a decision that leads to at least as good a known or expected outcome as all other available decision options. It is an important concept in decision theory. In order to compare the different decision outcomes, one commonly assigns a utility value to each of them.
In mathematics and computer science, the probabilistic method is used to prove the existence of mathematical objects with desired combinatorial properties. The proofs are probabilistic — they work by showing that a random object, chosen from some probability distribution, has the desired properties with positive probability. Consequently, they are nonconstructive — they don't explicitly describe an efficient method for computing the desired objects.
A binary decision is a choice between two alternatives, for instance between taking some specific action or not taking it.
A graphoid is a set of statements of the form, "X is irrelevant to Y given that we know Z" where X, Y and Z are sets of variables. The notion of "irrelevance" and "given that we know" may obtain different interpretations, including probabilistic, relational and correlational, depending on the application. These interpretations share common properties that can be captured by paths in graphs. The theory of graphoids characterizes these properties in a finite set of axioms that are common to informational irrelevance and its graphical representations.

Richard Eugene Neapolitan was an American scientist. Neapolitan is most well-known for his role in establishing the use of probability theory in artificial intelligence and in the development of the field Bayesian networks.
Probabilistic numerics is a scientific field at the intersection of statistics, machine learning and applied mathematics, where tasks in numerical analysis including finding numerical solutions for integration, linear algebra, optimisation and differential equations are seen as problems of statistical, probabilistic, or Bayesian inference.
