
Devanagari is an Indic script used in the northern Indian subcontinent. Also simply called Nāgari, it is a left-to-right abugida, based on the ancient Brāhmi script. It is one of the official scripts of the Republic of India and Nepal. It was developed and in regular use by the 7th century CE and achieved its modern form by 1000 CE. The Devanāgari script, composed of 48 primary characters, including 14 vowels and 34 consonants, is the fourth most widely adopted writing system in the world, being used for over 120 languages.

The Sinhala script, also known as Sinhalese script, is a writing system used by the Sinhalese people and most Sri Lankans in Sri Lanka and elsewhere to write the Sinhala language as well as the liturgical languages Pali and Sanskrit. The Sinhalese Akṣara Mālāva, one of the Brahmic scripts, is a descendant of the Ancient Indian Brahmi script. It is also related to the Grantha script.

The Kannada script is an abugida of the Brahmic family, used to write Kannada, one of the Dravidian languages of South India especially in the state of Karnataka. It is one of the official scripts of the Indian Republic. Kannada script is also widely used for writing Sanskrit texts in Karnataka. Several minor languages, such as Tulu, Konkani, Kodava, Sanketi and Beary, also use alphabets based on the Kannada script. The Kannada and Telugu scripts share very high mutual intellegibility with each other, and are often considered to be regional variants of single script. Other scripts similar to Kannada script are Sinhala script, and Old Peguan script (used in Burma).
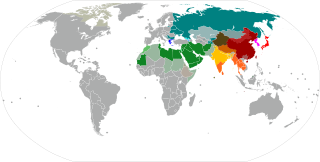
The Brahmic scripts, also known as Indic scripts, are a family of abugida writing systems. They are used throughout the Indian subcontinent, Southeast Asia and parts of East Asia. They are descended from the Brahmi script of ancient India and are used by various languages in several language families in South, East and Southeast Asia: Indo-Aryan, Dravidian, Tibeto-Burman, Mongolic, Austroasiatic, Austronesian, and Tai. They were also the source of the dictionary order (gojūon) of Japanese kana.
The Thai script is the abugida used to write Thai, Southern Thai and many other languages spoken in Thailand. The Thai alphabet itself has 44 consonant symbols and 16 vowel symbols that combine into at least 32 vowel forms and four tone diacritics to create characters mostly representing syllables.
Malayalam script is a Brahmic script used commonly to write Malayalam, which is the principal language of Kerala, India, spoken by 45 million people in the world. It is a Dravidian language spoken in the Indian state of Kerala and the union territories of Lakshadweep and Puducherry by the Malayali people. It is one of the official scripts of the Indian Republic. Malayalam script is also widely used for writing Sanskrit texts in Kerala.

In linguistics, romanization is the conversion of text from a different writing system to the Roman (Latin) script, or a system for doing so. Methods of romanization include transliteration, for representing written text, and transcription, for representing the spoken word, and combinations of both. Transcription methods can be subdivided into phonemic transcription, which records the phonemes or units of semantic meaning in speech, and more strict phonetic transcription, which records speech sounds with precision.
Anusvara, also known as Bindu, is a symbol used in many Indic scripts to mark a type of nasal sound, typically transliterated ⟨ṃ⟩ or ⟨ṁ⟩ in standards like ISO 15919 and IAST. Depending on its location in the word and the language for which it is used, its exact pronunciation can vary. In the context of ancient Sanskrit, anusvara is the name of the particular nasal sound itself, regardless of written representation.
Devanagari is an Indic script used for many Indo-Aryan languages of North India and Nepal, including Hindi, Marathi and Nepali, which was the script used to write Classical Sanskrit. There are several somewhat similar methods of transliteration from Devanagari to the Roman script, including the influential and lossless IAST notation. Romanised Devanagari is also called Romanagari.
The National Library at Kolkata romanisation is a widely used transliteration scheme in dictionaries and grammars of Indic languages. This transliteration scheme is also known as (American) Library of Congress and is nearly identical to one of the possible ISO 15919 variants. The scheme is an extension of the IAST scheme that is used for transliteration of Sanskrit.

The Grantha script was a classical South Indian Brahmic script, found particularly in Tamil Nadu and Kerala. Originating from the Pallava script, the Grantha script is related to Tamil and Vatteluttu scripts. The modern Malayalam script of Kerala is a direct descendant of the Grantha script. The Southeast Asian and Indonesian scripts such as Thai and Javanese respectively, as well as South Asian Tigalari and Sinhala scripts, are derived or closely related to Grantha through the early Pallava script. The Pallava script or Pallava Grantha, emerged in the 4th century CE and was used until the 7th century CE, in India. This early Grantha script was used to write Sanskrit texts, inscriptions on copper plates and stones of Hindu temples and monasteries. It was also used for classical Manipravalam – a language that is a blend of Sanskrit and Tamil. From it evolved Middle Grantha by the 7th century, and Transitional Grantha by about the 8th century, which remained in use until about the 14th century. Modern Grantha has been in use since the 14th century and into the modern era, to write classical texts in Sanskrit and Dravidian languages. It is also used to chant hymns and in traditional Vedic schools.
The Harvard-Kyoto Convention is a system for transliterating Sanskrit and other languages that use the Devanāgarī script into ASCII. It is predominantly used informally in e-mail, and for electronic texts.
ISO 15919 is one of a series of international standards for romanization by the International Organization for Standardization. It was published in 2001 and uses diacritics to map the much larger set of consonants and vowels in Brahmic and Nastaliq scripts to the Latin script.
The "Indian languages TRANSliteration" (ITRANS) is an ASCII transliteration scheme for Indic scripts, particularly for the Devanagari script.
There are several romanisation schemes for the Malayalam script, including ITRANS and ISO 15919.
Romanisation of Bengali is the representation of written Bengali language in the Latin script. Various romanisation systems for Bengali are used, most of which do not perfectly represent Bengali pronunciation. While different standards for romanisation have been proposed for Bengali, none has been adopted with the same degree of uniformity as Japanese or Sanskrit.
Indic Computing means "computing in Indic", i.e., Indian Scripts and Languages. It involves developing software in Indic Scripts/languages, Input methods, Localization of computer applications, web development, Database Management, Spell checkers, Speech to Text and Text to Speech applications and OCR in Indian languages.
The Sanskrit Library Phonetic basic encoding scheme (SLP1) is an ASCII transliteration scheme for the Sanskrit language from and to the Devanagari script.
The Velthuis system of transliteration is an ASCII transliteration scheme for the Sanskrit language from and to the Devanagari script. It was developed in about 1983 by Frans Velthuis, a scholar living in Groningen, Netherlands, who created a popular, high-quality software package in LaTeX for typesetting Devanāgarī. The primary documentation for the scheme is the system's clearly-written software manual. It is based on using the ISO 646 repertoire to represent mnemonically the accents used in standard scholarly transliteration. It does not use diacritics as IAST does. It may optionally use capital letters in a manner similar but not identical to the Harvard-Kyoto or ITRANS schemes.manual para 4.1

Meitei input methods are the methods that allow users of computers to input texts in the Meitei script, systematically for Meitei language.
