
In statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is
In probability theory, the central limit theorem (CLT) establishes that, in many situations, for independent and identically distributed random variables, the sampling distribution of the standardized sample mean tends towards the standard normal distribution even if the original variables themselves are not normally distributed.

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).
In probability theory, Chebyshev's inequality guarantees that, for a wide class of probability distributions, no more than a certain fraction of values can be more than a certain distance from the mean. Specifically, no more than 1/k2 of the distribution's values can be k or more standard deviations away from the mean. The rule is often called Chebyshev's theorem, about the range of standard deviations around the mean, in statistics. The inequality has great utility because it can be applied to any probability distribution in which the mean and variance are defined. For example, it can be used to prove the weak law of large numbers.

In probability theory and statistics, the Rayleigh distribution is a continuous probability distribution for nonnegative-valued random variables. Up to rescaling, it coincides with the chi distribution with two degrees of freedom. The distribution is named after Lord Rayleigh.
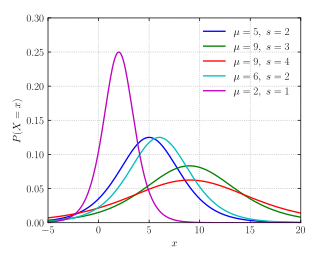
In probability theory and statistics, the logistic distribution is a continuous probability distribution. Its cumulative distribution function is the logistic function, which appears in logistic regression and feedforward neural networks. It resembles the normal distribution in shape but has heavier tails. The logistic distribution is a special case of the Tukey lambda distribution.
In statistics, propagation of uncertainty is the effect of variables' uncertainties on the uncertainty of a function based on them. When the variables are the values of experimental measurements they have uncertainties due to measurement limitations which propagate due to the combination of variables in the function.

In probability theory and statistics, the Lévy distribution, named after Paul Lévy, is a continuous probability distribution for a non-negative random variable. In spectroscopy, this distribution, with frequency as the dependent variable, is known as a van der Waals profile. It is a special case of the inverse-gamma distribution. It is a stable distribution.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.

In probability theory and statistics, the continuous uniform distributions or rectangular distributions are a family of symmetric probability distributions. Such a distribution describes an experiment where there is an arbitrary outcome that lies between certain bounds. The bounds are defined by the parameters, and which are the minimum and maximum values. The interval can either be closed or open. Therefore, the distribution is often abbreviated where stands for uniform distribution. The difference between the bounds defines the interval length; all intervals of the same length on the distribution's support are equally probable. It is the maximum entropy probability distribution for a random variable under no constraint other than that it is contained in the distribution's support.

In probability theory, the Rice distribution or Rician distribution is the probability distribution of the magnitude of a circularly-symmetric bivariate normal random variable, possibly with non-zero mean (noncentral). It was named after Stephen O. Rice (1907–1986).

In probability theory and statistics, the chi distribution is a continuous probability distribution over the non-negative real line. It is the distribution of the positive square root of a sum of squared independent Gaussian random variables. Equivalently, it is the distribution of the Euclidean distance between a multivariate Gaussian random variable and the origin. It is thus related to the chi-squared distribution by describing the distribution of the positive square roots of a variable obeying a chi-squared distribution.
In probability theory, calculation of the sum of normally distributed random variables is an instance of the arithmetic of random variables.
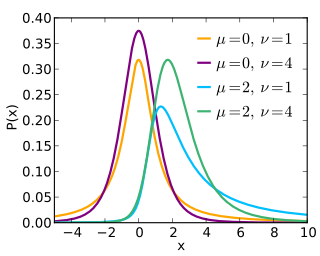
The noncentral t-distribution generalizes Student's t-distribution using a noncentrality parameter. Whereas the central probability distribution describes how a test statistic t is distributed when the difference tested is null, the noncentral distribution describes how t is distributed when the null is false. This leads to its use in statistics, especially calculating statistical power. The noncentral t-distribution is also known as the singly noncentral t-distribution, and in addition to its primary use in statistical inference, is also used in robust modeling for data.
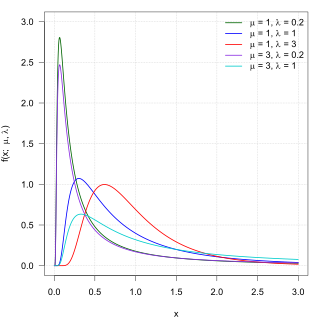
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
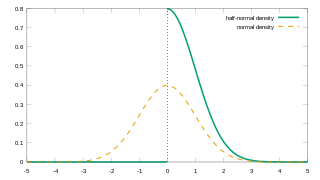
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.

In probability theory, a logit-normal distribution is a probability distribution of a random variable whose logit has a normal distribution. If Y is a random variable with a normal distribution, and t is the standard logistic function, then X = t(Y) has a logit-normal distribution; likewise, if X is logit-normally distributed, then Y = logit(X)= log (X/(1-X)) is normally distributed. It is also known as the logistic normal distribution, which often refers to a multinomial logit version (e.g.).














































