
In statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is
The weighted arithmetic mean is similar to an ordinary arithmetic mean, except that instead of each of the data points contributing equally to the final average, some data points contribute more than others. The notion of weighted mean plays a role in descriptive statistics and also occurs in a more general form in several other areas of mathematics.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
In mathematical analysis, Hölder's inequality, named after Otto Hölder, is a fundamental inequality between integrals and an indispensable tool for the study of Lp spaces.
In statistics, the mean squared error (MSE) or mean squared deviation (MSD) of an estimator measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss. The fact that MSE is almost always strictly positive is because of randomness or because the estimator does not account for information that could produce a more accurate estimate. In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk, as an estimate of the true MSE.

In statistics, the Pearson correlation coefficient (PCC) is a correlation coefficient that measures linear correlation between two sets of data. It is the ratio between the covariance of two variables and the product of their standard deviations; thus, it is essentially a normalized measurement of the covariance, such that the result always has a value between −1 and 1. As with covariance itself, the measure can only reflect a linear correlation of variables, and ignores many other types of relationships or correlations. As a simple example, one would expect the age and height of a sample of teenagers from a high school to have a Pearson correlation coefficient significantly greater than 0, but less than 1.
Ridge regression is a method of estimating the coefficients of multiple-regression models in scenarios where the independent variables are highly correlated. It has been used in many fields including econometrics, chemistry, and engineering. Also known as Tikhonov regularization, named for Andrey Tikhonov, it is a method of regularization of ill-posed problems. It is particularly useful to mitigate the problem of multicollinearity in linear regression, which commonly occurs in models with large numbers of parameters. In general, the method provides improved efficiency in parameter estimation problems in exchange for a tolerable amount of bias.
In statistics, sometimes the covariance matrix of a multivariate random variable is not known but has to be estimated. Estimation of covariance matrices then deals with the question of how to approximate the actual covariance matrix on the basis of a sample from the multivariate distribution. Simple cases, where observations are complete, can be dealt with by using the sample covariance matrix. The sample covariance matrix (SCM) is an unbiased and efficient estimator of the covariance matrix if the space of covariance matrices is viewed as an extrinsic convex cone in Rp×p; however, measured using the intrinsic geometry of positive-definite matrices, the SCM is a biased and inefficient estimator. In addition, if the random variable has a normal distribution, the sample covariance matrix has a Wishart distribution and a slightly differently scaled version of it is the maximum likelihood estimate. Cases involving missing data, heteroscedasticity, or autocorrelated residuals require deeper considerations. Another issue is the robustness to outliers, to which sample covariance matrices are highly sensitive.
In statistics, the theory of minimum norm quadratic unbiased estimation (MINQUE) was developed by C. R. Rao. MINQUE is a theory alongside other estimation methods in estimation theory, such as the method of moments or maximum likelihood estimation. Similar to the theory of best linear unbiased estimation, MINQUE is specifically concerned with linear regression models. The method was originally conceived to estimate heteroscedastic error variance in multiple linear regression. MINQUE estimators also provide an alternative to maximum likelihood estimators or restricted maximum likelihood estimators for variance components in mixed effects models. MINQUE estimators are quadratic forms of the response variable and are used to estimate a linear function of the variances.
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the input dataset and the output of the (linear) function of the independent variable.
In information theory, the cross-entropy between two probability distributions and over the same underlying set of events measures the average number of bits needed to identify an event drawn from the set if a coding scheme used for the set is optimized for an estimated probability distribution , rather than the true distribution .
Weighted least squares (WLS), also known as weighted linear regression, is a generalization of ordinary least squares and linear regression in which knowledge of the unequal variance of observations (heteroscedasticity) is incorporated into the regression. WLS is also a specialization of generalized least squares, when all the off-diagonal entries of the covariance matrix of the errors, are null.

In statistics, an empirical distribution function is the distribution function associated with the empirical measure of a sample. This cumulative distribution function is a step function that jumps up by 1/n at each of the n data points. Its value at any specified value of the measured variable is the fraction of observations of the measured variable that are less than or equal to the specified value.
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood estimation are special cases of M-estimators. The definition of M-estimators was motivated by robust statistics, which contributed new types of M-estimators. However, M-estimators are not inherently robust, as is clear from the fact that they include maximum likelihood estimators, which are in general not robust. The statistical procedure of evaluating an M-estimator on a data set is called M-estimation.
In statistics, generalized least squares (GLS) is a method used to estimate the unknown parameters in a linear regression model. It is used when there is a non-zero amount of correlation between the residuals in the regression model. GLS is employed to improve statistical efficiency and reduce the risk of drawing erroneous inferences, as compared to conventional least squares and weighted least squares methods. It was first described by Alexander Aitken in 1935.
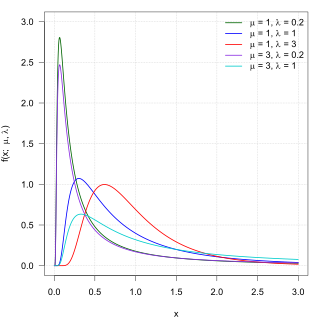
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
The topic of heteroskedasticity-consistent (HC) standard errors arises in statistics and econometrics in the context of linear regression and time series analysis. These are also known as heteroskedasticity-robust standard errors, Eicker–Huber–White standard errors, to recognize the contributions of Friedhelm Eicker, Peter J. Huber, and Halbert White.
In statistics and machine learning, lasso is a regression analysis method that performs both variable selection and regularization in order to enhance the prediction accuracy and interpretability of the resulting statistical model. The lasso method assumes that the coefficients of the linear model are sparse, meaning that few of them are non-zero. It was originally introduced in geophysics, and later by Robert Tibshirani, who coined the term.
In statistics, the Horvitz–Thompson estimator, named after Daniel G. Horvitz and Donovan J. Thompson, is a method for estimating the total and mean of a pseudo-population in a stratified sample by applying inverse probability weighting to account for the difference in the sampling distribution between the collected data and the a target population. The Horvitz–Thompson estimator is frequently applied in survey analyses and can be used to account for missing data, as well as many sources of unequal selection probabilities.
The streamline upwind Petrov–Galerkin pressure-stabilizing Petrov–Galerkin formulation for incompressible Navier–Stokes equations can be used for finite element computations of high Reynolds number incompressible flow using equal order of finite element space by introducing additional stabilization terms in the Navier–Stokes Galerkin formulation.










































